本次和大家聊一下TCP效能優化。
TCP全稱為Transmission Control Protocol,每一個IT人士對TCP都有一定了解。TCP協議屬於底層協議,對於大部分研發人員來說,這是透明的,無需關心TCP的實現與細節。
不過如果想做深入的效能優化,TCP是繞不過去的一環。要講TCP效能優化,必須先回顧一下TCP的一些細節。讓我們先來看一下TCP的首部格式
TCP報文段的首部格式
TCP報文段首部的前20個位元組是固定的,後面有4n位元組是根據需要而增加的選項(n是整數)。因此TCP首部的最小長度是20位元組。
- 序號:欄位值指的是本報文段所傳送的資料的第一個位元組的序號
- 確認號:是期望收到對方下一個報文段的第一個資料位元組的序號。若確認號為= N,則表明:到序號N-1為止的所有資料都已正確收到
- ACK: 僅當ACK = 1時確認號欄位才有效,當ACK = 0時確認號無效。TCP規定,在連線建立後所有的傳送的報文段都必須把ACK置為1
- SYN: 在連線建立時用來同步序號。當SYN=1而ACK=0時,表明這是一個連線請求報文段。對方若同意建立連線,則應在響應的報文段中使SYN=1和ACK=1,因此SYN置為1就表示這是一個連線請求或連線接受報文
- 視窗:視窗欄位明確指出了現在允許對方傳送的資料量。視窗值經常在動態變化。
- 選項:
- 最大報文段長度MSS:
- 乙太網Ethernet最大的資料幀是1518位元組。乙太網幀的幀頭14位元組和幀尾CRC校驗4位元組(共佔18位元組),剩下承載上層協議的地方也就是Data域最大就只剩1500位元組. 這個值我們就把它稱之為MTU。
- 為了達到最佳的傳輸效能TCP協議在建立連線的時候通常要協商雙方的MSS值,這個值TCP協議在實現的時候往往用MTU值代替,MSS一般在1420~1460,1460是由1500 - 20(IP頭)- 20/60(TCP頭)計算出的。
- 視窗擴大選項:TCP首部中視窗欄位長度是16位,因此最大的視窗大小為64K位元組。可以將視窗最大值增大到2^(16+14)-1=2^30-1
- 最大報文段長度MSS:
三次握手
原理
所有TCP連線一開始都要經過三次握手,如下圖所示:

- SYN: 客戶端選擇一個隨機序列號x,併發送一個SYN分組,其中可能還包括其他TCP標誌和選項。
- SYN ACK: 伺服器給x加1,並選擇自己的一個隨機序列號y,追加自己的標誌和選項,然後返回響應。
- ACK: 客戶端給x和y加1併發送握手期間的最後一個ACK分組。
上面的內容我們在書上看過多次,這次我們用wireshark抓包看一下詳情:
本機ip為192.168.1.102,伺服器ip為122.51.162
sync
sync ack
ack
三次握手完成後,客戶端與伺服器之間就可以通訊了。
這個啟動通訊的過程適用於所有TCP連線,因此對所有使用TCP的應用具有非常大的效能影響,因為每次傳輸應用資料之前,都必須經歷一次完整的往返。
優化
三次握手帶來的延遲使得每建立一個新TCP連線都要付出很大代價。而這也決定了提高TCP應用效能的關鍵,在於想辦法重用連線。
TCP快速開啟
TFO(TCP fast open)允許伺服器和客戶端在連線建立握手階段交換資料,從而使應用節省了一個RTT的時延。
但是TFO會引起一些問題,因此協議要求TCP實現必須預設禁止TFO。需要在某個服務埠上啟用TFO功能的時候需要應用程式顯示啟用。
設定:sysctl -n net.ipv4.tcp_fastopen = 0x203
限制:並不能解決所有問題,它雖然有助於減少三次握手的往返時間,但卻只能在某些情況下有效,如隨同SYN分組一起傳送的資料淨荷有最大尺寸限制、只能傳送某些型別的HTTP請求,以及由於依賴加密cookie,只能應用於重複的連線。
效果:經過流量分析和網路模擬,谷歌研究人員發現TFO平均可以降低HTTP事務網路延遲15%、整個頁面載入時間10%以上。在某些延遲很長的情況下,降低幅度甚至可達40%。
盡最大可能重用已經建立的TCP連線
長連結(Keep-Alive)
Keep-Alive,HTTP 1.1 之後預設開啟,指在一個 TCP 連線中可以持續傳送多份資料而不會斷開連線
Keep-Alive能夠實現,需要服務端支援:
Httpd守護程序,如nginx需要設定keepalive_timeout
- keepalive_timeout=0:建立tcp連線 + 傳送http請求 + 執行時間 + 傳送http響應 + 關閉tcp連線 + 2MSL
- keepalive_timeout>0:建立tcp連線 + (最後一個響應時間 – 第一個請求時間) + 關閉tcp連線 + 2MSL
另外TCP自身也有Keep-Alive,是檢測TCP連線狀況的保鮮機制
-
net.ipv4.tcpkeepalivetime:表示TCP連結在多少秒之後沒有資料報文傳輸啟動探測報文
-
net.ipv4.tcpkeepaliveintvl:前一個探測報文和後一個探測報文之間的時間間隔
-
net.ipv4.tcpkeepaliveprobes:探測的次數
負載均衡
基本原理:客戶端(如:ClientA)與負載均衡裝置之間進行三次握手併發送 HTTP 請求。負載均衡裝置收到請求後,會檢測伺服器是否存在空閒的長連結,如果不存在,伺服器將建立一個新連線。當 HTTP 請求響應完成後,客戶端與負載均衡裝置協商關閉連線,而負載均衡則保持與伺服器之間的這個連線。當有其他客戶端(如:ClientB)需要傳送 HTTP 請求時,負載均衡裝置會直接向伺服器之間保持的這個空閒連線傳送 HTTP 請求,避免來由於新建 TCP 連線造成的延時和伺服器資源耗費。
接收視窗rwnd
流量控制是一種預防傳送端過多向接收端傳送資料的機制。否則,接收端可能因為忙碌、負載重或緩衝區容量有限而無法處理。為實現流量控制,
TCP連線的每一方都要通告自己的接收視窗(rwnd),其中包含能夠儲存資料的緩衝區空間大小資訊。

第一次建立連線時,兩端都會使用自身系統的預設設定來發送rwnd。每個ACK分組都會攜帶相應的最新rwnd值,以便兩端動態調整資料流速,使之適應傳送端和接收端的容量及處理能力。
最初的TCP規範分配給通告視窗大小的欄位是16位的,這相當於設定了傳送端和接收端視窗的最大值(2的16次方即65 535位元組)。為解決這個問題,RFC 1323提供了“TCP視窗縮放”(TCPWindow Scaling)選項,可以把接收視窗大小由65 535位元組提高到1G位元組!
縮放TCP視窗是在三次握手期間完成的,其中有一個值表示在將來的ACK中左移16位視窗欄位的位數。
優化
客戶端與伺服器之間最大可以傳輸資料量取rwnd和cwnd變數中的最小值。
開啟視窗縮放
開啟視窗縮放,能使接收視窗大小從2^16升級到2^30,可以獲得更好的傳輸效能。
檢視:sysctl net.ipv4.tcp_window_scaling
設定:sysctl -w net.ipv4.tcp_window_scaling=1
效果:比起不開啟視窗縮放,能夠充分利用頻寬
這裡講述一下頻寬延遲積。BDP(Bandwidth-delay product,頻寬延遲積)資料鏈路的容量與其端到端延遲的乘積。這個結果就是任意時刻處於在途未確認狀態的最大資料量。
傳送端或接收端無論誰被迫頻繁地停止等待之前分組的ACK,都會造成資料缺口,從而必然限制連線的最大吞吐量。
無論實際或通告的頻寬是多大,視窗過小都會限制連線的吞吐量。
知道往返時間和兩端的實際頻寬也可以計算最優視窗大小。這一次我們假設往返時間為100 ms,傳送端的可用頻寬為10 Mbps,接收端則為100 Mbps+。還假設兩端之間沒有網路擁塞,我們的目標就是充分利用客戶端的10 Mbps頻寬:

視窗至少需要122.1 KB才能充分利用10 Mbps頻寬!如果沒“視窗縮放,TCP接收視窗最大隻有64 KB,無論網路效能有多好,永遠無法充分利用頻寬。
慢啟動與擁塞避免
接收視窗對效能很重要,但擁塞視窗比接收視窗更重要。
客戶端與伺服器之間最大可以傳輸(未經ACK確認的)資料量取rwnd和cwnd變數中的最小值,而一開始的cwnd很小,通過慢啟動演算法不斷增大。
慢啟動和擁塞避免的演算法有很多,這裡使用Tahoe版本的TCP版本進行展示,這個也是帶有擁塞控制功能的第一個TCP版本,使用的擁塞避免演算法為AIMD(Multiplicative Decrease and Additive Increase,倍減加增)。
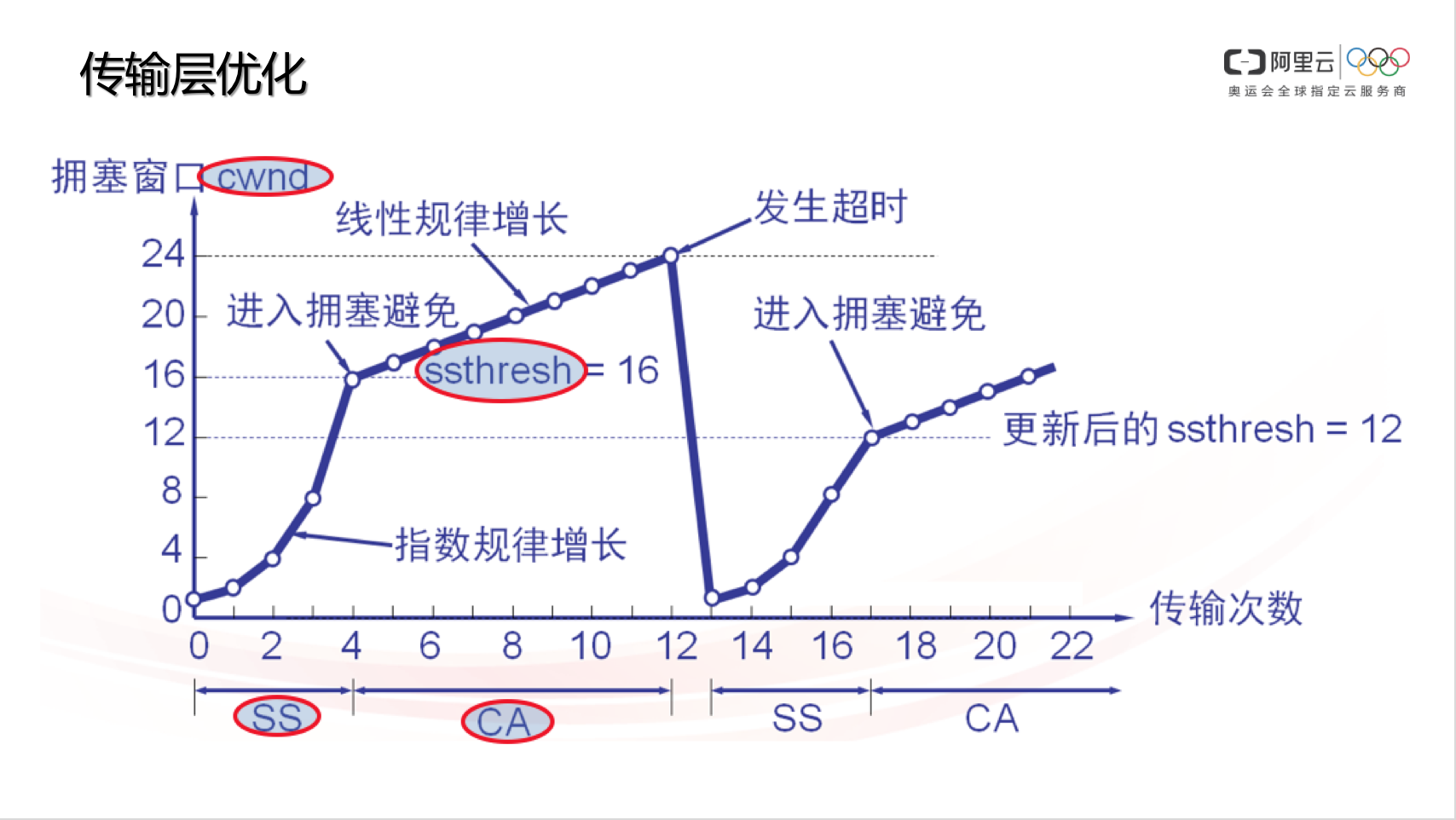
- SS:Slow Start,慢啟動階段。TCP 剛開始傳輸的時候,速度是慢慢漲起來的,除非遇到丟包,否則速度會一直指數性增長。
- CA:Congestion Avoid,擁塞避免階段。當擁塞視窗大於ssthresh後, CWND增長速度會下降,不再像 SS 那樣指數增,而是線性增。
- 超時:當資料傳送方感知到丟包時,會記錄此時的 CWND,並計算合理的 ssthresh 值,一般ssthresh會置為超時時CWND的一半,傳送端會驟降 CWND 到最初始的狀態,當 CWND 重新由小至大增長,直到 sshtresh 時,不再 SS 而是 CA
伺服器會有一個預設cwnd初始值。最初,cwnd的值只有1個TCP段。1999年4月,RFC 2581將其增加到了4個TCP段。2013年4月,RFC 6928再次將其提高到10個TCP段。
計算題
問題:cwnd大小達到N所需的時間
解:
下面我們就來看一個例子,假設:
• 客戶端和伺服器的接收視窗為65535位元組(64 KB);
• 初始的擁塞視窗:4段(RFC 2581);
• 往返時間是56 ms(倫敦到紐約);
這個例子說明網路正常情況下,要達到最大傳輸量,需要224ms。因為慢啟動限制了可用的吞吐量,而這對於小檔案傳輸非常不利,因為擁塞控制尚處於slowstart階段,傳輸就完畢了。
優化
確保cwnd大小為10
檢視:
-
寫指令碼
probe kernel.function("tcp_init_cwnd").return
{
printf("tcp_init_cwnd return: %d\n", $return)
}
-
把伺服器核心升級到最新版本(Linux:3.2+)
增大TCP的初始擁塞視窗
設定:在核心中增加一個控制initcwnd的proc引數,/proc/sys/net/ipv4/tcp_initcwnd。該方法對所有的TCP連線有效。
限制:初始擁塞視窗不能設定特別大,否則會導致交換節點的緩衝區被填滿,多出來的分組必須刪掉,相應的主機會在網路中製造越來越多的資料報副本,使得整個網路陷入癱瘓。行業內各大cdn廠商都調整過init_cwnd值,普遍取值在10-20之間
效果:
禁用慢啟動重啟
名詞解釋:SSR(Slow-Start Restart,慢啟動重啟)會在連線空閒一定時間後重置連線的擁塞視窗。
原因:在連線空閒的同時,網路狀況也可能發生了變化,為了避免擁塞,理應將擁塞視窗重置回“安全的”預設值。
檢視: sysctl net.ipv4.tcp_slow_start_after_idle
設定: sysctl -w net.ipv4.tcp_slow_start_after_idle=0
效果:對於那些會出現突發空閒的長週期TCP連線(比如HTTP的keep-alive連線)有很大的影響,具體提升效能根據網路效能和資料量大小不同而不同
更改擁塞避免演算法
擁塞控制演算法對TCP效能影響很大,除了上面提到的AIMD演算法,還有眾多其他演算法。
PRR(Proportional Rate Reduction,比例降速)就是RFC 6937規定的一個新演算法,其目標就是改進丟包後的恢復速度。
效果:根據谷歌的測量,實現新演算法後,因丟包造成的平均連線延遲減少了3%~10%。
設定:升級伺服器。PRR現在是Linux 3.2+核心預設的擁塞預防演算法。
減少傳輸資料量
方案:
-
減少傳輸冗餘資料
-
壓縮要傳輸的資料:gzip、protobuf、webp等
-
再快也快不過什麼也不用傳送
減少往返時間
方案:
- 多機房部署伺服器
- 使用CDN
隊首阻塞
隊首(HOL,Head of Line)阻塞:如果中途有一個分組沒能到達接收端,那麼後續分組必須儲存在接收端的TCP緩衝區,等待丟失的分組重發併到達接收端。這一切都發生在TCP層,應用程式對TCP重發和緩衝區中排隊的分組一無所知,必須等待分組全部到達才能訪問資料。在此之前,應用程式只能在通過套接字讀資料時感覺到延遲交付。

優點:應用程式不用關心分組重排和重組,從而讓程式碼保持簡潔。
缺點:分組到達時間會存在無法預知的延遲變化。這個時間變化通常被稱為抖動,也是影響應用程式效能的一個主要因素。
優化
UDP
無法優化,這是TCP的基礎邏輯,目前沒有優化的可能。
無需按序交付資料或能夠處理分組丟失的應用程式,以及對延遲或抖動要求很高的應用程式,最好選擇UDP等協議。
一般的音訊或者遊戲等應用,可以選擇使用UDP協議
總結
針對TCP的優化建議
- 伺服器配置調優
- 伺服器使用最新版本
- 增大TCP的初始擁塞視窗
- 慢啟動重啟
- 視窗縮放(RFC 1323)
- TCP快速開啟
- 可用ss命令或sysctl -a | grep tcp檢視相關配置
- 應用程式行為調優
- 再快也快不過什麼也不用傳送,能少發就少發
- 我們不能讓資料傳輸得更快,但可以讓它們傳輸的距離更短
- 重用TCP連線是提升效能的關鍵
- 效能檢查清單
- 把伺服器核心升級到最新版本(Linux:3.2+);
- 確保cwnd大小為10;
- 禁用空閒後的慢啟動;
- 確保啟動視窗縮放;
- 減少傳輸冗餘資料;
- 壓縮要傳輸的資料;
- 把伺服器放到離使用者近的地方以減少往返時間;
- 盡最大可能重用已經建立的TCP連線。
資料
- Web權威效能指南
- TCP 滑動視窗 與視窗縮放因子
- TCP的滑動視窗與擁塞視窗
- Web 效能優化 - TCP
- 就是要你懂TCP--效能優化大全
- TCP報文段的首部格式
- TCP Socket通訊詳細過程
- TCP三次握手以及SYN,ACK,Seq的不詳細解釋
- Wireshark資料包分析
- Wireshark網路分析就這麼簡單
- TCP-fastopen(TFO)
- TCP系列40—擁塞控制—3、慢啟動和擁塞避免概述
- TCP系列41—擁塞控制—4、Linux中的慢啟動和擁塞避免(一)
- HTTP Keep-Alive是什麼?如何工作?(理解TCP生命週期)
- nginx - KeepAlive詳細解釋
最後
大家如果喜歡我的文章,可以關注我的公眾號(程式設計師麻辣燙)
往期文章回顧:
技術
- TCP效能優化
- 限流實現1
- Redis實現分散式鎖
- Golang原始碼BUG追查
- 事務原子性、一致性、永續性的實現原理
- CDN請求過程詳解
- 記部落格服務被壓垮的歷程
- 常用快取技巧
- 如何高效對接第三方支付
- Gin框架簡潔版
- InnoDB鎖與事務簡析
讀書筆記
思考