KVSSD: 結合 LSM 與 FTL 以實現寫入優化的 KV 存儲
本次分享的 Paper[1]:《 KVSSD:Close integration of LSM trees and flash translation layer for write-efficient KV store 》是在 18 年的 Design, Automation & Test in Europe Conference & Exhibition (DATE) 會議上出現的 KVSSD,作者為:Sung-Ming Wu[2]、Kai-Hsiang Lin[3]、 Li-Pin Chang[4]。
這篇 Paper 主要思路是在 SSD 上直接提供 KV 接口,將 LSM Tree 與 FTL 深度結合,從而避免從 LSM Tree,主機文件系統到 FTL 多個軟件層的寫入放大。跟大家分享這篇 Paper ,一方面是蹭一蹭 KV 接口已經成功進入 NVMe 2.0 規範被標準化的熱點,另一方面是為了和 TiKV / TiDB 的同學探討未來存儲硬件的更多可能性,希望能帶來一些啟發。
本文將首先介紹問題的背景,什麼是寫放大,哪裏產生了寫放大,然後引出解決方案,介紹 KVSSD 做了哪些優化,之後再介紹 KVSSD 的性能評估數據,以及工業上的進展。

背景
首先我們來聊聊背景。這是一個 TiKV 的架構圖:
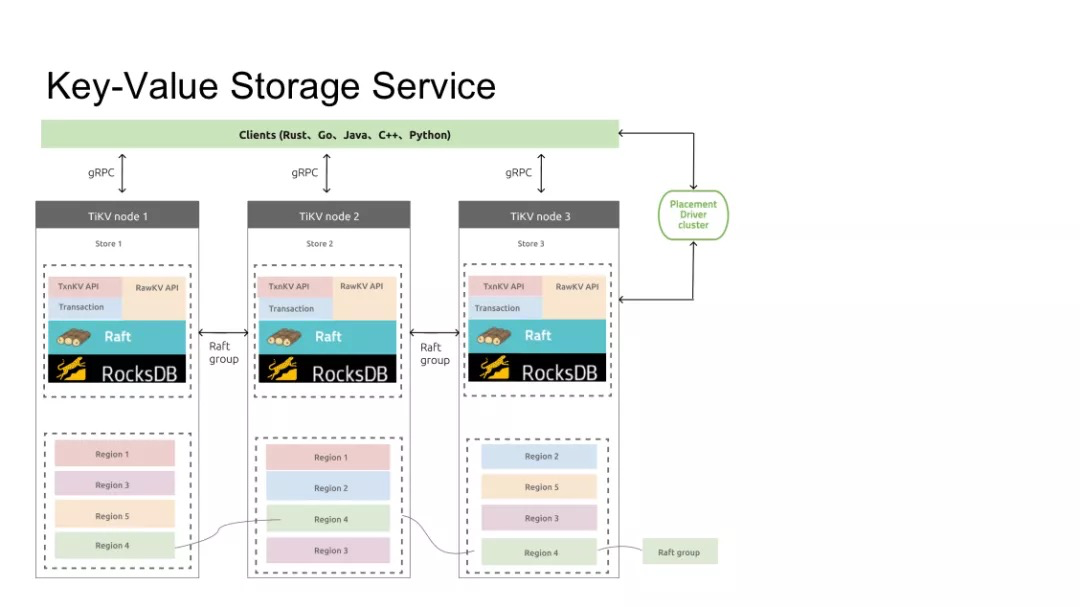
我們都知道 TiKV 是一個分佈式的 Key-Value 數據庫,TiKV 的每一個節點都運行着一個 RocksDB 的實例,就像是這樣:
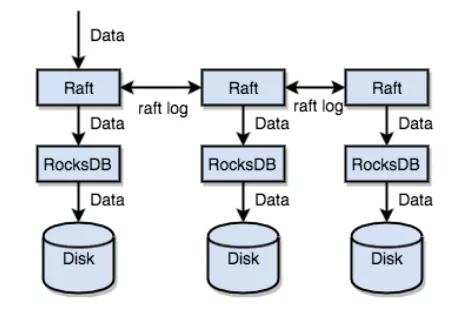
RocksDB 基於 Log-structed merge-tree (LSM) 開發的,LSM tree 是目前業界運用最為廣泛的持久化數據結構之一。我們要討論的問題就是 LSM tree 在 SSD 上遇到的寫入放大問題及其解決方案。
KV 存儲系統中的寫放大
從存儲的視角來看,一個 KV 存儲的軟件堆棧大概是這樣的:
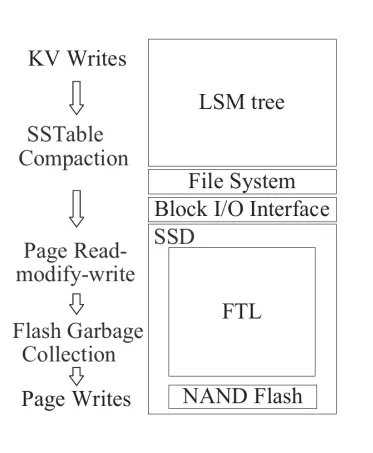
最頂層是一顆 LSM tree,具體的實現就不展開了。大體的思路是在內存中維護可變的 Memtable,在 SSD 上維護不可變的 SSTable。Memtable 寫滿後會作為 SSTable 輸入存儲,而所有的 SSTable 會組合成一顆分層的樹,每一層寫滿後就會向下一層做 compaction。LSM tree 維護過程中產生的 IO 會通過文件系統與 BIO 層的轉換落到 SSD 上。
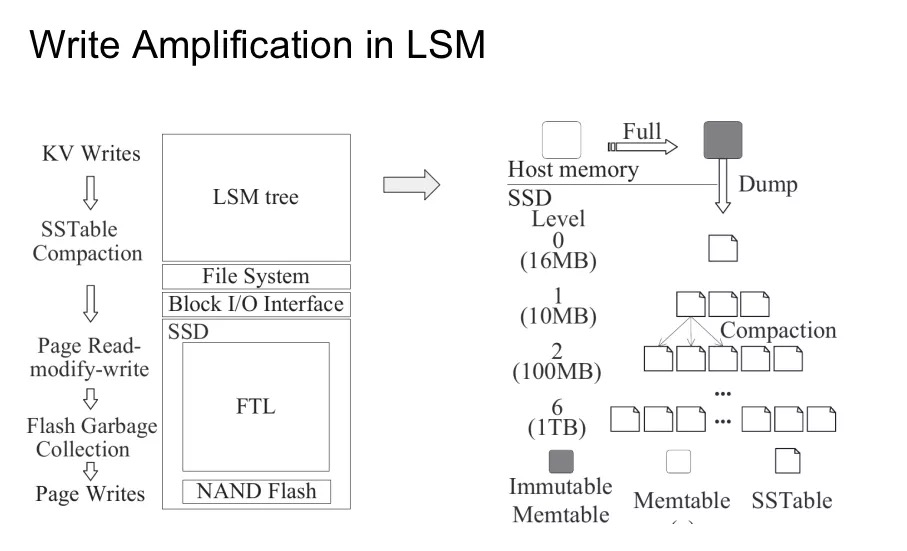
然後看一下文件系統。顯然的,文件落到文件系統上必然會有一些額外的開銷,比如説我們需要維護文件的 Metadata。inode、大小、修改時間、訪問時間等都需要持久化。此外,文件系統需要能夠保證在 crash 的時候不丟失已經寫入的數據,所以還需要引入日誌,寫時複製這樣的技術。
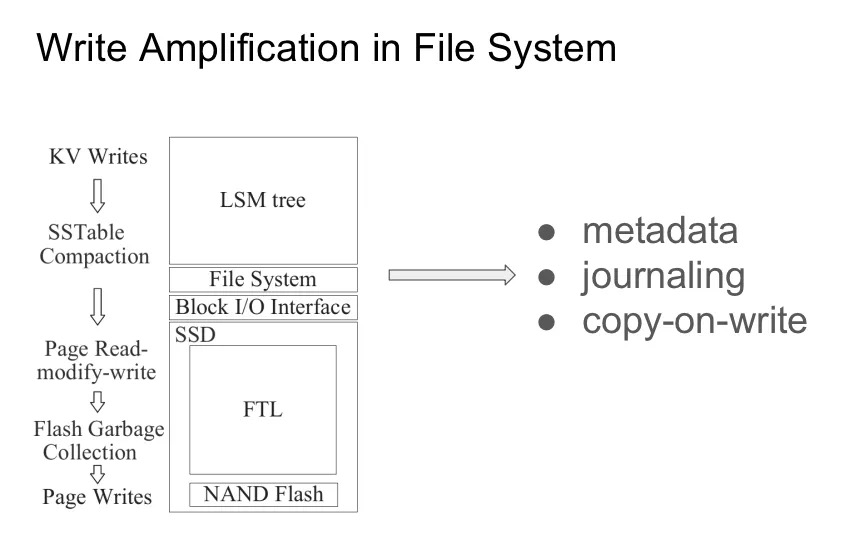
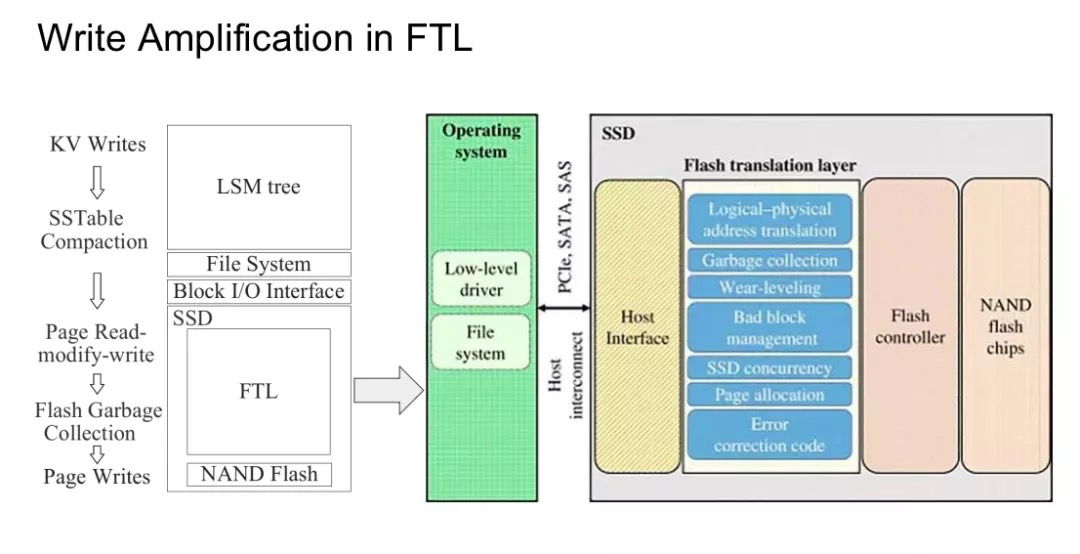
然後再來看看 SSD 這一層。一個典型的 NAND Flash 芯片通常由 package、die、plane、block 和 page 組成。package,又叫做 chips,就是我們能在 SSD 上看到的顆粒。一個 pakage 通常由多層堆疊而成,每一層就叫做一顆 die。一顆 die 裏面會被劃分為多個 plane,而每個 plane 裏面會包括一組 Block,每個 Block 又可以進一步細化為 Page。其中 Block 是擦除動作的最小單位,通常是 128KB 到 256KB 不等,而 Page 是讀取和寫入的最小單位,通常為 2KB 到 32KB 不等。為了維護邏輯地址到物理地址的轉換,SSD 中引入了 FTL。此外,FTL 還需要承擔垃圾回收,壞塊回收,磨損均衡等職責。
我們知道 SSD 設備的特性決定了它在寫之前必須要進行擦除操作,設備需要將數據全部讀到內存中修改並寫回。為了均衡芯片損耗與性能,SSD 通常會選擇標記當前 block ,尋找新的可用 block 來寫入,由 FTL 來執行垃圾回收,這也就是我們常説的 SSD Trim 過程。
從上面的分析我們不難觀察到嚴重的寫放大問題:
-
LSM tree 的 compaction 過程
-
文件系統自身
-
塊請求落到 FTL 上會出現的 read-modify-write 過程
-
FTL 的垃圾回收
-
Paper 中沒有考慮文件系統本身的寫放大,只取了剩下三點的乘積作為總體的寫入放大率。寫入放大顯然是個壞東西,既加大了存儲設備的磨損,又降低了寫入的吞吐,這些因素最終都會反映到用户的總體持有成本上。
如何緩解寫放大?
為了解決或者説緩解這個問題,大家提出過很多不同方向的方案。

比如説我們可以對算法做一些改造,比如 LSM-trie[5]、PebblesDB[6] 或者 WiscKey[7]。WiscKey 大家可能比較熟悉一點,將 LSM tree 中的 Key 和 Value 分開存儲,犧牲範圍查詢的性能,來降低寫放大。TiKV 的 titan 存儲引擎、dgraph 開源的 badger[8]還有 TiKV 社區孵化中的 Agatedb[9] 都是基於這個思路設計的。
或者我們也能在文件系統這一層做些事情,比如説專門開發一個面向寫方法優化的文件系統,減少在日誌等環節的寫入 IO,比如説開啟壓縮比更高的透明壓縮算法,或者面向 KV 的典型負載做一些優化和調參。
但是算法上和軟件上的優化終究還是有極限的,想要突破就只能不做人啦,直接對硬件下手,從固件的層面進行優化。一般的來説,系統優化都有拆抽象和加抽象兩個方向的優化。拆抽象是指我們去掉現有的抽象,將更多的底層細節暴露出來,這樣用户可以更自由的根據自己的負載進行鍼對性優化。加抽象是指我們增加新的抽象,屏蔽更多的底層細節,這樣可以針對硬件特點做優化。
存儲系統的優化也不例外。

拆抽象思路的先驅者是 Open-Channel SSD,它的思路是把固件裏的 FTL 揚了,讓用户自己來實現。這個思路是好的,但是 Open-Channel Spec 只定義了最通用的一部分,具體到廠商而言,他們考慮到自己 SSD 的產品特性和商業機密,往往選擇在兼容 Open-Channel Spec 的同時,再加入一些自己的定義。這就導致至今都沒有出現通用的 Open-Channel SSD 和針對業務的通用 FTL。對用户來説,並不通用的 Open-Channel SSD 帶來了更嚴重的 vendor-lock 問題。所以 Open-Channel SSD 遲遲無法得到大規模應用。
NVMe 工作組也看到了這樣的問題,所以他們消化吸收了 Open-Channel 的精髓,提出了 Zoned Namespace (ZNS) 的新特性。ZNS 將一個 namespace 下的邏輯空間地址劃分為一個個的 zone,zone 當中只能進行順序寫,需要顯式的擦除操作才能再次進行覆蓋寫。通過這種方式 SSD 將內部結構的邊界透露給外界,讓用户來實現具體的地址映射,垃圾回收等邏輯。
另一個思路是加抽象,既然上層業務做不好這個事情,那就把它加到固件裏面,硬件自己做。比如説在固件中直接實現 Key-Value 接口,或者使用計算型 SSD 將更多的計算任務下推到 SSD 上來做。
這裏額外插一句感慨,三國演義開篇的“天下大勢,分久必合,合久必分”真是太對了。軟件定義存儲發展到現在,硬件廠商也不甘於成為純粹的供貨商,他們也想加入到產業鏈上游,獲取更多的利潤。所以在存算分離已經成為大勢所趨的時候,業界還孕育着一股存算融合的潮流:通過更合理更規範的抽象,充分利用自己軟硬一體的優勢,提供在延遲和吞吐上更具優勢的產品。比如有消息稱三星開發中的 KVSSD 上搭載的芯片計算能力相當於兩三年前的手機芯片。考慮到 FPGA 和 ARM 這樣精簡指令集的芯片的持續發展,相信這股潮流會帶來更多系統架構上的可能性。
KVSSD 設計
好的,迴歸正題。這篇 Paper 就是採用了加抽象的路線,在固件中直接實現 Key-Value 接口。
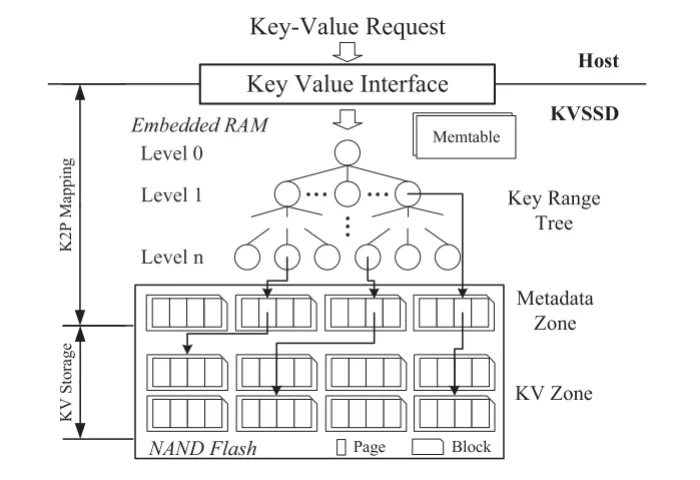
KVSSD 採用了閃存原生的 LSM tree 實現,叫做 nLSM (NAND-flash-LSM)。nLSM tree 把 FTL 的 L2P(Logical To Physic) 層轉換為了 K2P ( Key To Physic) 映射,每個樹節點都代表一個 SSTable 的 Key 範圍。nLSM tree 將整個閃存花費為元數據區和 KV 區,KV 區中存儲排序後的 KV 對,元數據區中的每一頁叫做元數據頁,只包含指向 KV 頁和鍵範圍的指針。
nLSM 運用瞭如下設計來優化寫放大:
K2P Mapping
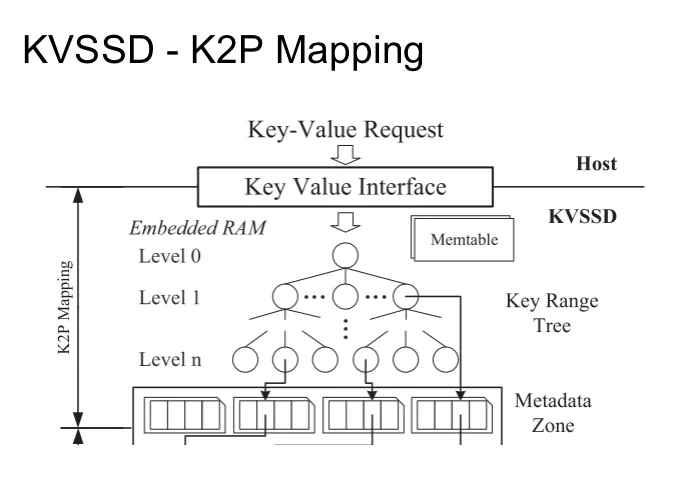
首先我們來看一下 K2P 映射的設計。顯然的,K2P 的抽象層次比 L2P 高很多,不可能在 SSD 的內存中直接存儲所有 Key 對應的物理 Page。所以作者選擇了在 K2P 中使用 Key Range Tree 來存儲 彼此不相交的 key-range 到 SSTable 的映射。nLSM tree 使用 Key Range Tree 來找到一個元數據頁,然後使用元數據頁中的 key range 信息來找到一個 KV 頁,然後再從 KV 頁中檢索目標 KV 對。nLSM tree 給每個 SSTable 分配了一個閃存塊,閃存塊的大小是 4MB 跟 SSTable 的大小一樣大,保證 SSTable 物理上連續且跟頁面邊界對齊。在 compaction 的時候,nLSM tree 會對舊的 SSTable 進行多向合併排序,並寫入新的 SSTable,並丟棄舊的 SSTbale。之後的垃圾回收過程可以直接擦除這些塊,不需要進行任何的數據複製。
Remapping Compaction
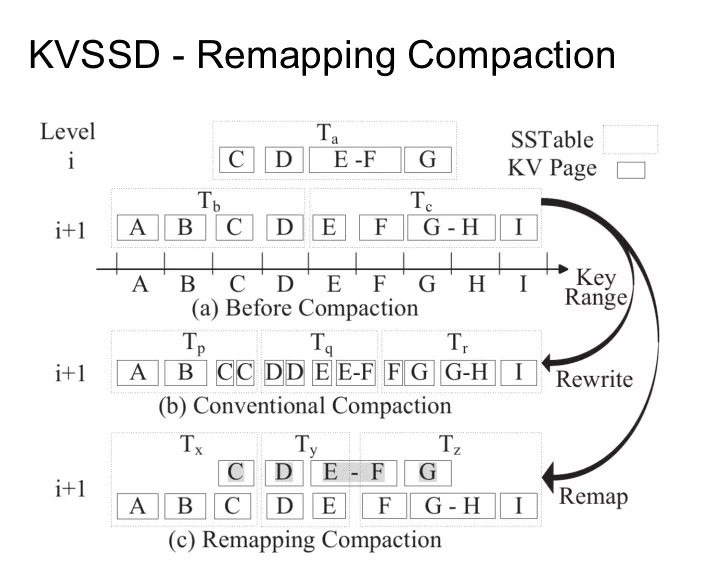
其次是 Remapping Compaction。
假設我們現在 Key Range 被劃分為 A 到 I 這幾個區間。Ta 表示的是 Level i 層的數據,Tb 和 Tc 表示 Level i+1 層的數據,現在我們要進行 Compaction 的話,就需要以某種形式將 Ta 中的數據塞進 Tb 和 Tc。Tb 和 Tc 組成一一組區間連續的 Key,而 Ta 跟他們都有一些重疊的地方。如果按照傳統的方式重寫這些 Page 的話,我們需要寫 12 個 KV page,再加上 3 個 metadata page。但是在 Remapping Compaction 中,會選擇重新寫 Tx、Ty、Tz 三個 metadata page 分別指向已經存在的 KV Page。這樣就把重寫 page 的代價從 15 降低到了 3。
Hot-cold Separation
最後是冷熱分離。顯然的,高效的垃圾回收依賴數據分佈的特徵。假如相對較冷的數據能分佈在一起,避免重複的 gc 熱數據,可以極大的降低 gc 的寫入放大。在 LSM tree 的寫入模型當中,上層總是比下層的數據要小,換句話來説,上層的數據參與 gc 更多、更頻繁。不同層次的數據有着不同的生命週期。基於這樣的特性,有一個可能優化是在垃圾回收遷移數據的時候,儘可能的在同一級別的 KV 頁中寫入數據,這樣能保證相似壽命的頁面能被分組到相似的區塊中。
KVSSD 性能分析
接下來我們看看 Paper 的性能分析環節。這篇 Paper 主要涉及三個性能方面的因素:寫放大、吞吐和讀放大。實驗中使用的 SSD 設備是 15GB,5% 是保留空間,page size 是 32KB,block size 是 4MB。實驗的方法是使用 blktrace 記錄 leveldb 的 block I/O trace 然後在 SSD 模擬器上重放來收集閃存的操作數據。分別對比了
-
LSM: 基於 leveldb
-
dLSM: 一種 delay compaction 的優化
-
lLSM: 一種輕量級 compaction 的優化
-
nLSM
-
rLSM(-): nLSM with remapping compaction
-
rLSM: nLSM with remapping compaction and hot-cold sparation
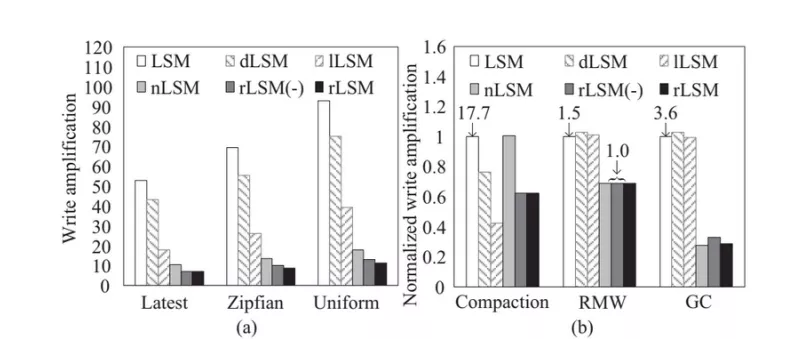
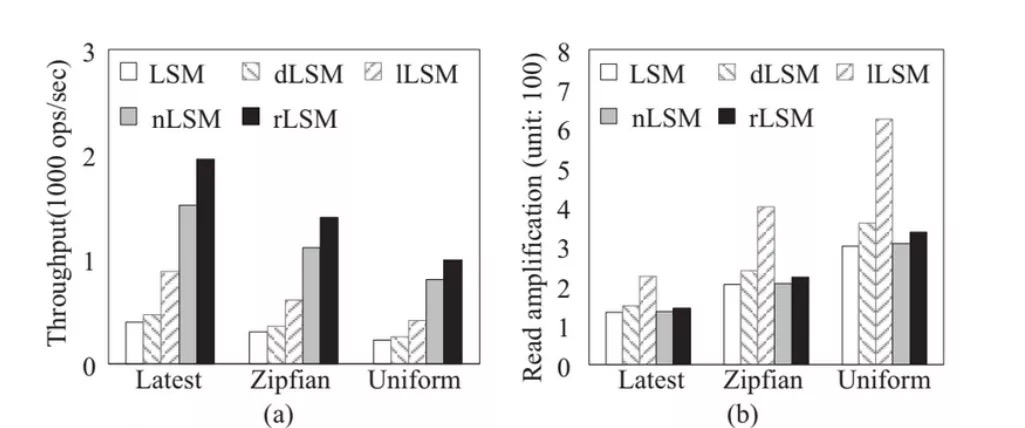
根據這一組圖可以看到,在給定的測試條件下 rLSM 能將寫放大降低至原來的 12%,同時將吞吐提升了 4.47 倍,但是帶來了 11% 的讀放大。
好,到這裏我們這篇 paper 的整體思路就已經介紹完了。我們來回顧一下 KVSSD 的價值,首先最明顯的是 KVSSD 能帶來更小寫入放大,可以提高吞吐,進而降低 TCO,符合現在業界降本增效的潮流。其次從系統架構設計的角度上來看,KVSSD 能夠進一步的將 I/O Offload 到 SSD 設備上。以 rocksdb 為例,使用 KVSSD 能降低 rocksdb 的 compaction 和 log 開銷。此外,SSD 的計算能力實際上是在逐步提升的,未來可以在 SSD 中進行壓縮,加密,校驗等一系列重計算的任務。這些都為架構提供了新的可能性。
KVSSD 在工業上的進展
最後我們來看看業界的跟進情況。
在 2019 的 SYSTOR 會議上,三星沿用這一思路,發表了論文 Towards building a high-performance, scale-in key-value storage system[10],在論文中提到三星與 SNIA 聯手製定了 Key Value Storage API 規範,基於現有的 Block SSD 實現了 KV-SSD 的原型:
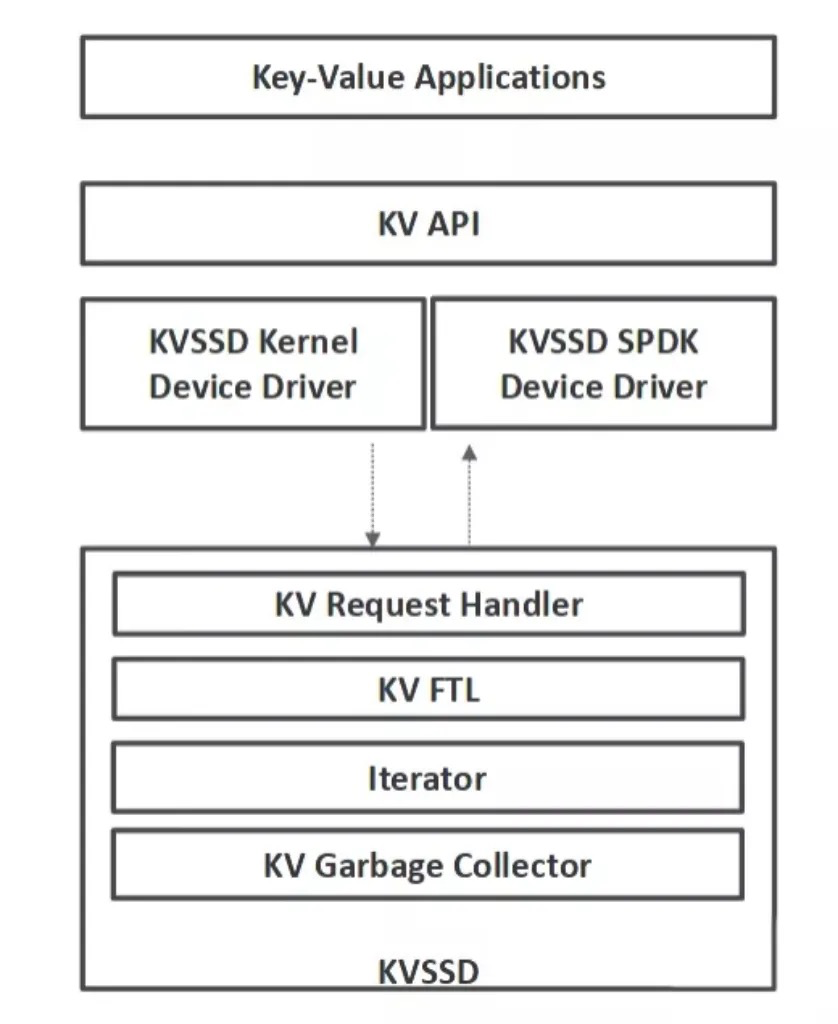
還發表了公開的 KVSSD 相關的 API 與驅動:
http://github.com/OpenMPDK/KVSSD
根據三星論文中的分析來看,KV-SSD 展現了非常強的線性擴展能力,隨着設備數量的增加,系統整體的 TPS 成線性增長,基本不受 CPU 的限制,感興趣的同學可以找來看看。
這裏我補充一下,三星的 KV-SSD 跟本次分享的論文只是大體思路相同,具體的設計和實現上還是有很大差異。
在 2021 年 6 月發佈的 NVMe 2.0 規範中,KVSSD 相關的指令集已經被規範化為 NVMe-KV 指令集,成為新的 I/O 命令集之一,允許使用 Key 而不是 Block 地址來訪問數據。考慮到業界對 NVMe 規範的廣泛支持,預計完全支持 NVMe 2.0 的 SSD 很快就有商用的產品上市,希望大家保持關注。
Q&A
業界更關心 ZNS 還是 KVSSD?
ZNS 實現上要比 KVSSD 容易的多,成本也比 KVSSD 更好控制,所以目前業界對 ZNS 還是更熱心一點。
KVSSD 冷熱分離的設計是不是會導致 Block 擦寫不均衡?
是的,論文裏面沒有展開論述相關的細節。按照目前這樣的設計確實會導致這個問題,需要在實現的時候講磨損均衡的問題也考慮進來。
KVSSD 需要佔用宿主機的內存和 CPU 嗎?
不需要,KVSSD 自帶獨立的內存和處理芯片,不依賴宿主機的資源。這也是使用 KVSSD 的意義之一:我們可以將這部分的負載 Offload 到 SSD 上,使得單一宿主機上可以接入更多的設備。
引用鏈接
[1] IEEE: http://ieeexplore.ieee.org/document/8342070
[2] Sung-Ming Wu: http://ieeexplore.ieee.org/author/37086370119
[3] Kai-Hsiang Lin: http://ieeexplore.ieee.org/author/37086098744
[4] Li-Pin Chang: http://ieeexplore.ieee.org/author/37733936200
[5] LSM-trie: http://www.usenix.org/conference/atc15/technical-session/presentation/wu
[6] PebblesDB: http://www.cs.utexas.edu/~vijay/papers/sosp17-pebblesdb.pdf
[7] WiscKey: http://www.usenix.org/conference/fast16/technical-sessions/presentation/lu
[8] badger: http://github.com/dgraph-io/badger
[9] Agatedb: http://github.com/tikv/agatedb
[10] Towards building a high-performance, scale-in key-value storage system: http://dl.acm.org/doi/10.1145/3319647.3325831
作者
丁皓 青雲科技存儲工程師
本文由博客一文多發平台 OpenWrite 發佈!
- Kubernetes CRI 分析 - kubelet 創建 Pod 分析
- 終於有人把 ZFS 文件系統講明白了
- KVSSD: 結合 LSM 與 FTL 以實現寫入優化的 KV 存儲
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 以 Serverless 的方式實現 Kubernetes 日誌吿警
- Knative Autoscaler 自定義彈性伸縮
- 科技熱點週刊|Zoom 1 億美元、Docker 收費、380 億美元 Databricks
- 科技熱點週刊|Linux 30 週年、Horizon Workroom 發佈、Humanoid Robot、元宇宙
- KubeSphere 核心架構淺析
- Go 語言實現 WebSocket 推送
- 基於 SDN 編排的雲安全服務
- 複雜應用開發測試的 ChatOps 實踐
- 基於 Formily 的表單設計器實現原理分析
- SegmentFault 基於 Kubernetes 的容器化與持續交付實踐
- 基於 Kubernetes 的雲原生 AI 平台建設
- 雲原生|新東方在有狀態服務 In K8s 的實踐
- 在線教育平台青椒課堂:使用 KubeSphere QKE 輕鬆實現容器多集羣管理
- 人均雲原生2.0,容器的圈子內卷嗎?
- 存儲大師班:NFS 的誕生與成長