雲原生|新東方在有狀態服務 In K8s 的實踐
有狀態服務建設一直以來都是 K8s 中非常具有挑戰性的工作,新東方在有狀態服務雲化過程中,採用定製化 Operator 與自研本地存儲服務結合的模式,增強了 K8s 原生本地存儲方案的能力,在摸索中穩步推進企業的容器化建設。
新東方有狀態服務 In K8s 的現狀
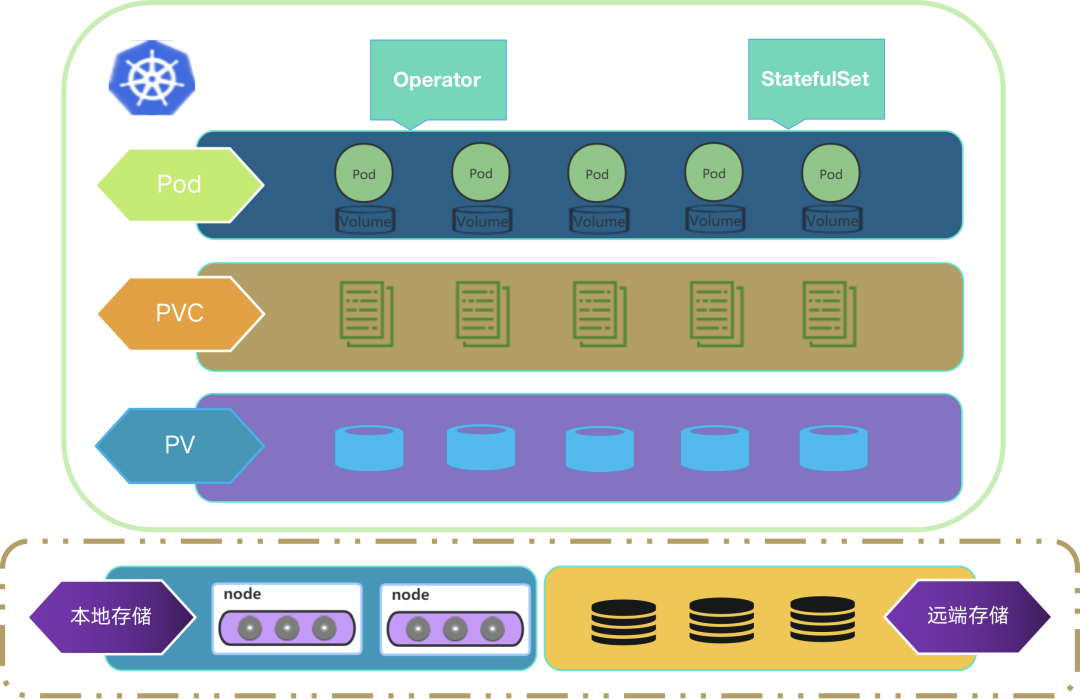
<center><b/>新東方有狀態服務現狀示意圖</center>
如上圖所示,上層 Pod 由自定義的 Operator 和 StatefulSet 控制器來託管,Pod 關聯 PVC,PVC 綁定 PV,最下層是存儲服務。
最下層的存儲服務包含本地存儲和遠端存儲兩類,對於一般的存儲需求,首選是遠端存儲服務;而對於高性能 IO 的存儲需求,那就要選擇本地存儲服務。目前,本地存儲服務包含 K8s 原生 local 存儲服務和自研的 xlss 存儲服務 2 種。
原生 K8s 支撐有狀態服務的能力
原生 K8s 支撐有狀態服務的能力是有狀態服務建設的基礎,其管理模式是:StatefulSet 控制器 + 存儲服務。
StatefulSet 控制器
StatefulSet 控制器:
用來管理有狀態應用的工作負載 API 對象的控制器。管理某 Pod 集合的部署和擴縮,併為這些 Pod 提供持久存儲和持久標識符。
StatefulSet 資源的特點:
-
穩定的、唯一的網絡標識
-
穩定的、持久的存儲
-
有序的、優雅的部署和縮放
-
有序的、自動的滾動更新
StatefulSet 資源的侷限:
-
關於存儲,StatefulSet 控制器是不提供存儲供給的。
-
刪除或者縮容時,StatefulSet 控制器只負責 Pod。
-
人工要建一個無頭服務,提供每個 Pod 創建唯一的名稱。
-
優雅刪除 StatefulSet,建議先縮放至 0 再刪除。
-
有序性也導致依賴性,比如編號大的 pod 依賴前面 pod 的運行情況,前面 pod 無法啟動,後面 pod 就不會啟動。
這 5 點侷限可進一步概括為:StatefulSet 控制器管理 Pod 和部分存儲服務(比如擴容時 pvc 的創建),其它的就無能為力。有序性引起的依賴性也會帶來負面影響的,需要人工干預治癒。
存儲服務
Cloud Native Storage
<center>CNS Of CNCF</center>
這是 CNCF 官網關於雲原生存儲的一副截圖。截圖時間是 2021 年 7 月初,有 50 多種存儲產品,接近半數屬於商業產品,開源產品多數都是遠端存儲類型,有支持文件系統的、有支持對象存儲的、還有支持塊存儲的。
K8s PV 類型
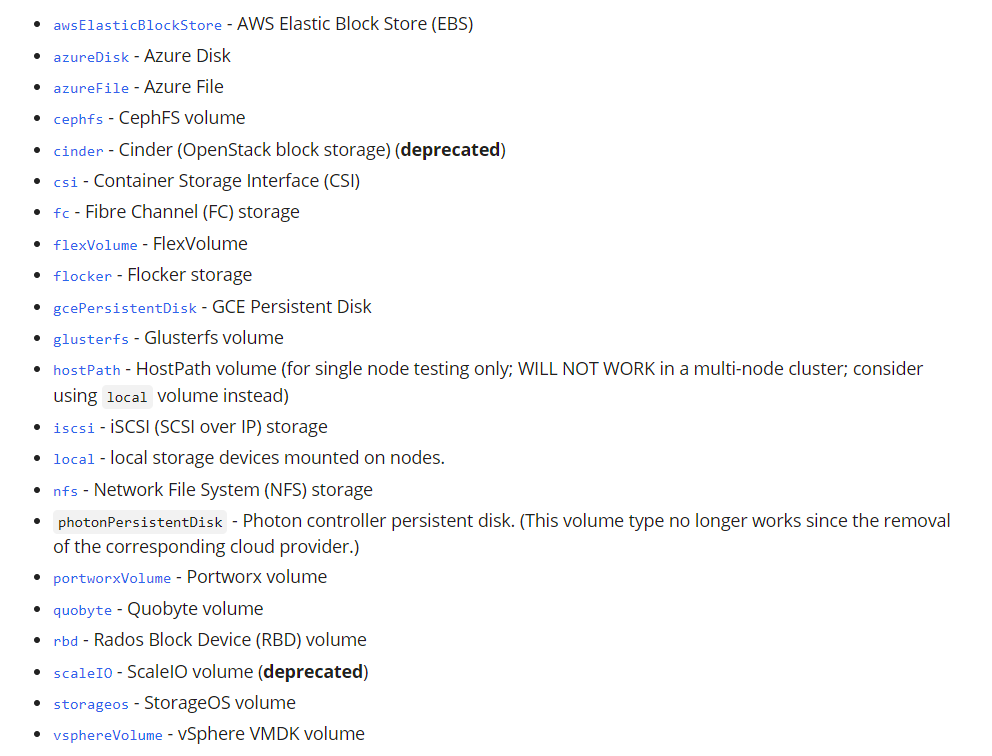
<center>PV Type Defined by K8s</center>
數據來源於官網,原生 K8s 支持的 PV 類型,有常用的 rbd、hostpath、local 等類型。
如何選擇?
控制器只有 StatefulSet 控制器可使用,存儲產品很多,PV 類型也不少,該怎麼選擇呢?
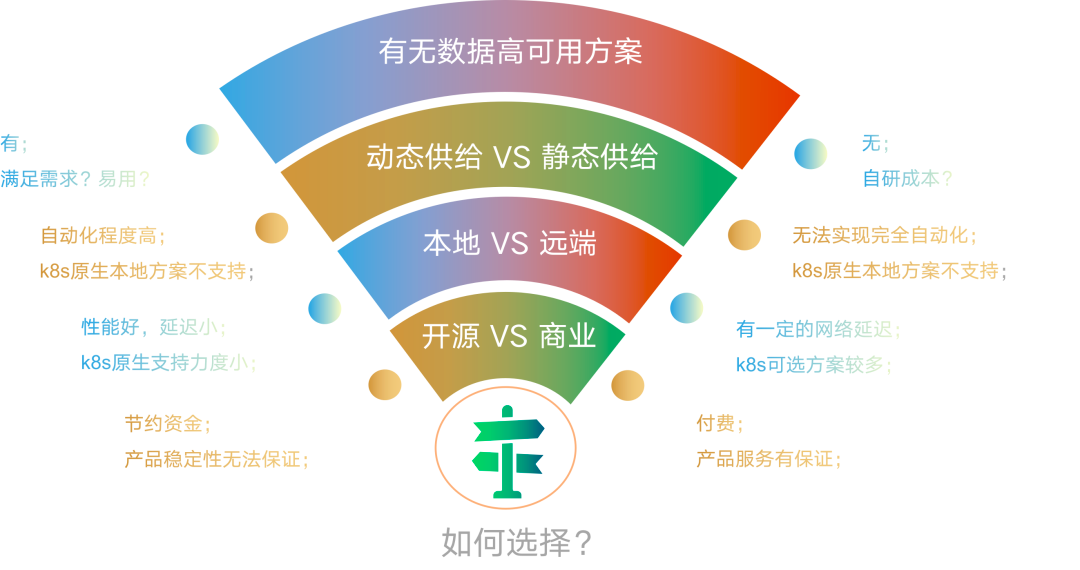
<center>存儲服務考慮因素示意圖</center>
選擇存儲產品,需要考慮哪些因素呢?新東方在選擇存儲產品時考慮了以下一些因素:
-
開源 VS 商業
-
本地 VS 遠端
-
動態供給 VS 靜態供給
-
數據高可用方案
做選擇是令人頭疼的事情,比如選擇開源,好處是不用花錢,但穩定性就很難保證,甚至提供的能力也有限;商業產品能力和穩定性有保證,但要付費。在這裏先不下結論,最終還是要看需求。
自研存儲產品 XLSS
關鍵需求
新東方有狀態服務建設的關鍵需求:良好的性能,支持 IO 密集型應用;數據可用性,具有一定的容災能力;動態供給,實現有狀態服務的完全自動化管理。
XLSS 介紹

<center>XLSS</center>
XLSS(XDF Local Storage Service)中文全稱:新東方本地存儲服務產品,是一種基於本地存儲的高性能、高可用存儲方案。可以解決 K8s 中本地存儲方案的不足之處:localpv 只能靜態供給;使用 localpv 時,pod 與 node 的親和性綁定造成的可用性降低;本地存儲存在數據丟失的風險。
應用場景
-
高性能應用,IO 密集型的應用軟件,比如 Kafka
-
本地存儲的動態化管理
-
數據安全,應用數據定期備份,備份數據加密保護
-
存儲資源監控吿警,比如 K8s Pv 資源的使用量監控吿警
XLSS In K8s
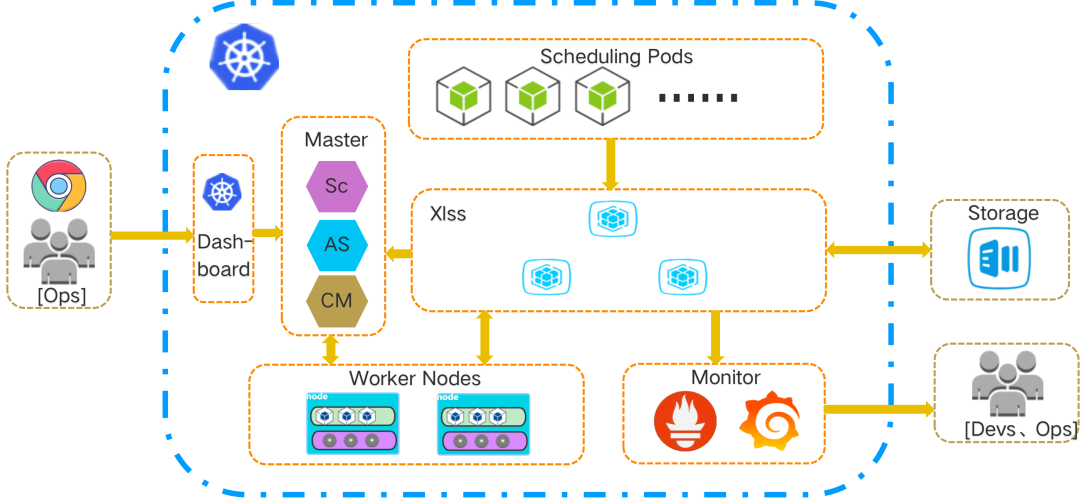
<center>XLSS In K8s</center>
如上圖所示,XLSS 在 K8s 中的運行狀態是 Xlss 的 3 個組件以容器形式運行在 K8s 集羣中,使用本地存儲為有狀態服務提供存儲服務,並定期執行數據的備份作業,Xlss 會提供有關存儲和相關作業的 metrics 數據。
XLSS 核心組件介紹
Xlss 主要組件包含:
<b/>xlss-scheduler
-
基於 kube-scheduler 的自定義調度器
-
對於有狀態服務的 pod 的調度,自動識別 xlss localpv 的使用身份,智能干預 pod 調度,消除 pod 與 node 的親和性綁定造成的可用性降低
<b/>xlss-rescuer
-
以 DaemonSet 資源類型運行在 k8s 集羣中
-
按照數據備份策略,執行數據備份作業
-
監視數據恢復請求,執行數據恢復作業
-
提供 metrics 數據
<b/>xlss-localpv-provisioner
- 動態供給本地存儲
xlss-scheduler 關鍵邏輯實現思路
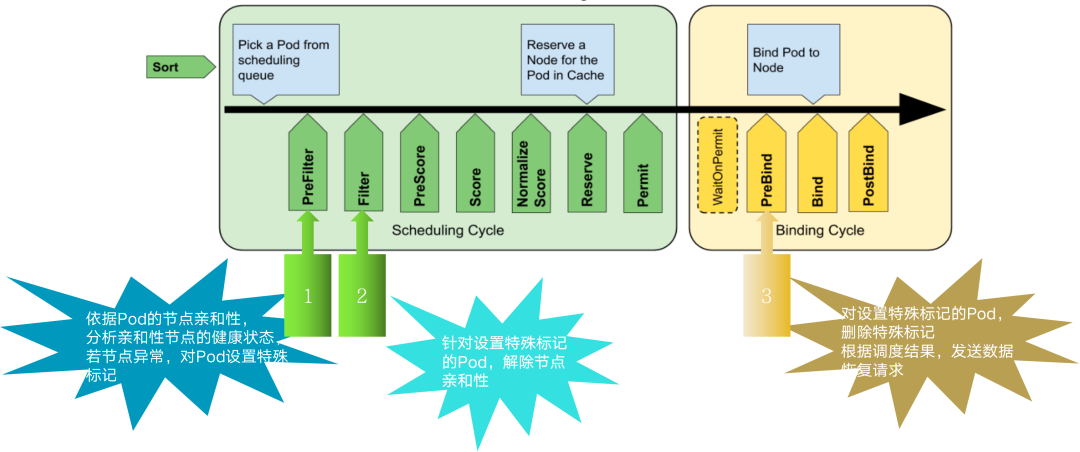
<center>K8s 調度框架模型</center>
如上圖,這是 K8s 調度器的調度框架模型,在調度流程中包含了許多擴展點。xlss-scheduler 就是基於該調度框架模型,通過編寫自定義的插件實現,主要在 3 個擴展點上做了增強:
-
Prefilter:依據 Pod 的節點親和性,分析親和性節點的健康狀態,若節點異常,對 Pod 設置特殊標記。
-
Filter:針對設置特殊標記的 Pod,解除節點親和性。
-
Prebind:對設置特殊標記的 Pod,刪除特殊標記,根據調度結果,發送數據恢復請求。
xlss-rescuer 數據備份作業實現邏輯
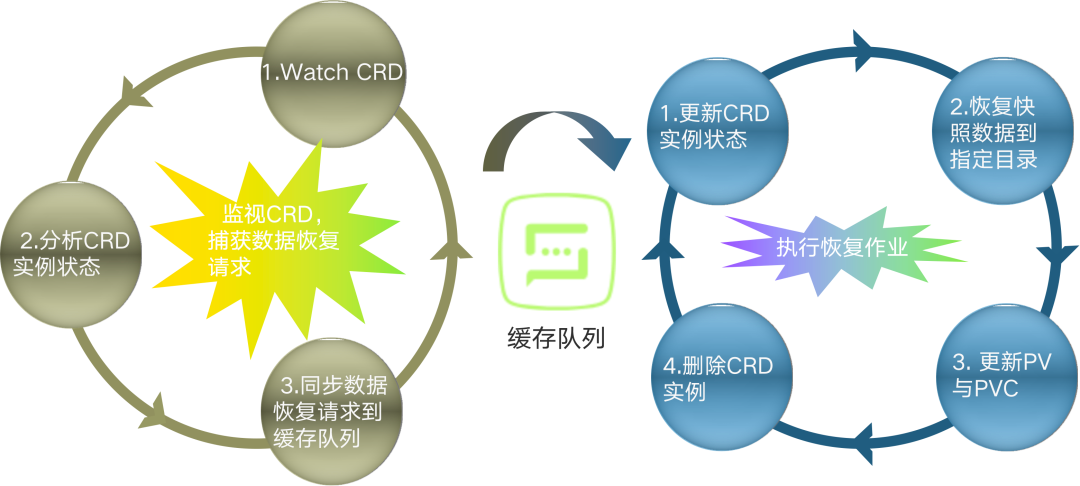
<center>數據備份作業實現邏輯</center>
圖中 3 個部分,左右各一個循環邏輯,中間通過一個緩存隊列實現通信。左邊的循環實現的功能:收集備份作業策略,並更新到緩存隊列中。主要 3 步:
-
watch pod 事件
-
從 pod 註解當中獲取備份策略,備份作業的配置信息是通過 pod 註解實現的
-
同步備份策略到緩存隊列
右邊的循環實現的功能:執行備份作業。也是 3 步:
-
對緩存隊列元素排序,排序按照下次備份作業的執行時間點進行升序排列
-
休眠等待,若當前時間還沒有到最近的一個備份作業執行時間,就會進行休眠等待
-
執行備份作業
xlss-rescuer 數據恢復作業實現邏輯
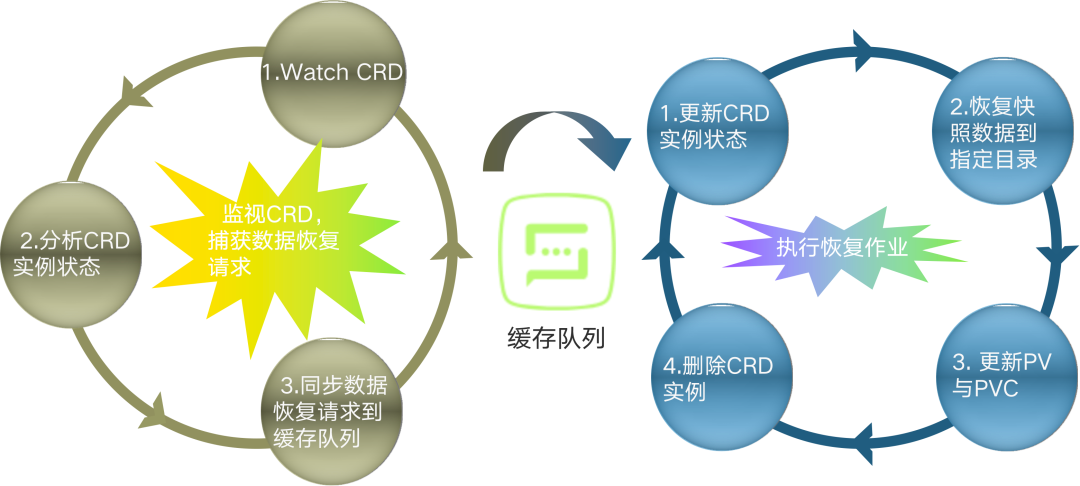
<center>數據恢復作業實現邏輯</center>
數據恢復作業流程和數據備份作業流程實現思路是類似的,但在具體實現邏輯上有所不同。
左邊的循環實現的功能:監視恢復作業請求,並更新到緩存隊列中。主要 3 步:
-
watch CRD,監視數據恢復請求,接收 xlss-scheduler 發出的數據恢復請求(數據恢復請求以 CRD 方式實現)
-
分析 CRD 狀態,避免重複處理
-
同步恢復請求到緩存隊列
右邊的循環實現的功能:執行恢復作業。這裏是 4 步:
-
更新 CRD 實例狀態
-
恢復快照數據到指定目錄
-
更新 PV 與 PVC
-
刪除 CRD 實例
xlss-localpv-provisioner 存儲創建實現思路
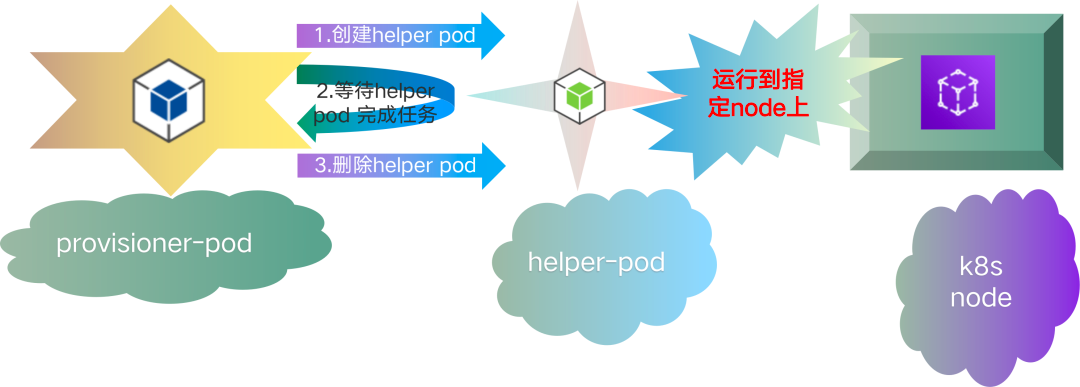
<center>本地存儲動態創建示意圖</center>
xlss-localpv-provisioner 組件,其功能比較專一,實現本地存儲的動態創建。其工作流程當 provisioner pod 獲取到創建存儲的請求時,首先會創建一個臨時的 helper pod,這個 helper pod 會被調度到指定的 node 上面,創建文件目錄作為本地存儲使用,這就完成了 pv 實際後端存儲的創建,當存儲創建完畢,provisioner pod 會將這個 helper pod 刪除。至此,一次本地存儲的動態創建完成。
xlss 自動災難恢復工作流程
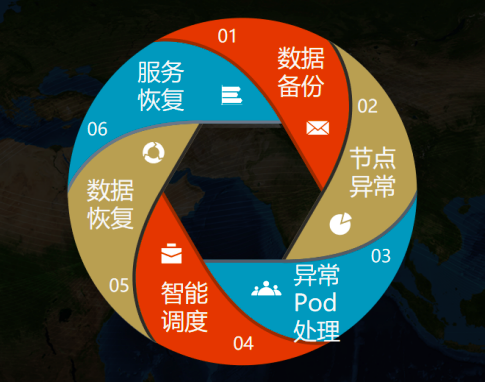
<center>xlss 自動災難恢復工作流程</center>
完整的自動災難恢復工作流程要經歷 6 個階段:
-
數據備份:以 pod 為粒度,對 pv 數據進行備份。
-
節點異常:此時集羣出現異常情況,某一節點發生異常,比如服務器損壞,引起在其上面的 pod 工作異常,最後有狀態服務的 pod 就會一直處於 Terminating 狀態。
-
異常 pod 處理:當有狀態服務的 pod 處於 Terminating 狀態時,要清理掉這些 pod,可以手動刪除,也可藉助工具,讓這些有狀態的 pod 有重新創建的機會。
-
智能調度 :解除親和性,將新 pod 調度到健康的節點上。
-
數據恢復:拉取該 pod 對應的最新的快照數據進行數據恢復。
-
服務恢復:啟動應用,對外提供服務。
至此,一個完整的自動災難恢復工作流程結束,最後又回到起點。
大規模存儲型中間件服務
存儲問題基本解決了,那該怎麼落地呢?答案就是建設存儲型中間件服務。
Kafka Cluster In K8s
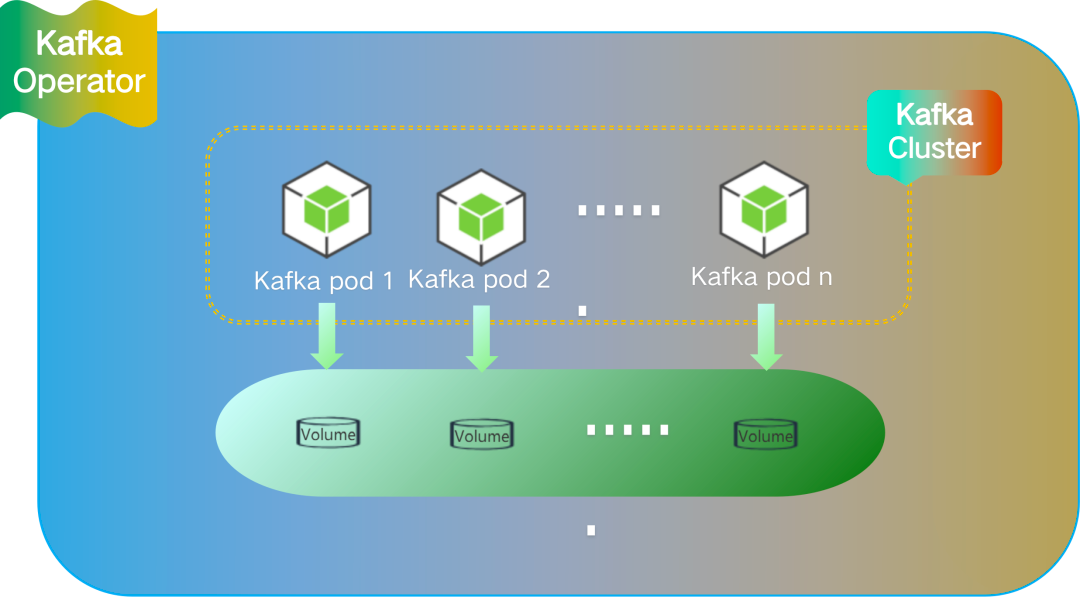
<center>Kafka Cluster In K8s</center>
以 kafka 集羣為例,通過定製化的 kafka operator 來部署 kafka 集羣,指定存儲服務使用 xlss 存儲。採取定製化 Operator + xlss 模式去建設存儲型中間件服務。
有狀態中間件服務 In K8s
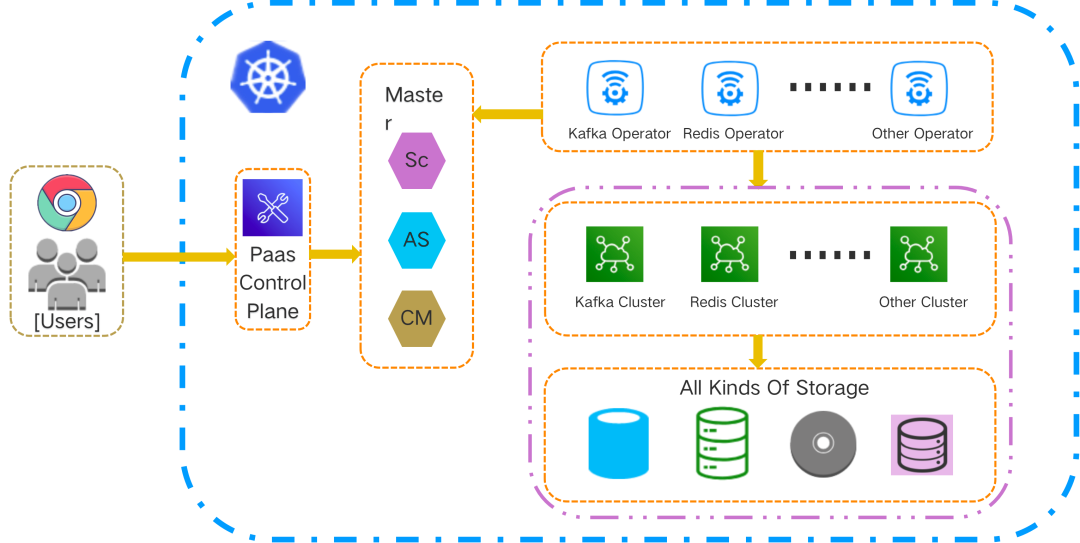
<center>Stateful Apps In K8s</center>
有狀態中間件服務在 K8s 中的運行狀態如上圖所示,這些存儲型中間件服務集羣託管於對應的 Operator,底層存儲根據業務需要適配各類存儲。隨着中間件服務集羣規模的日益擴大,我們建設了 PaaS 控制面,用户可以通過該控制面來管理運行在 K8s 中的各類中間件服務集羣。控制面可以直接和 apiserver 交互,用户通過控制面增刪改 CRD 資源,Operator 根據 CRD 資源的最新狀態,調和中間件服務集羣的狀態。
用户申請中間件服務示例
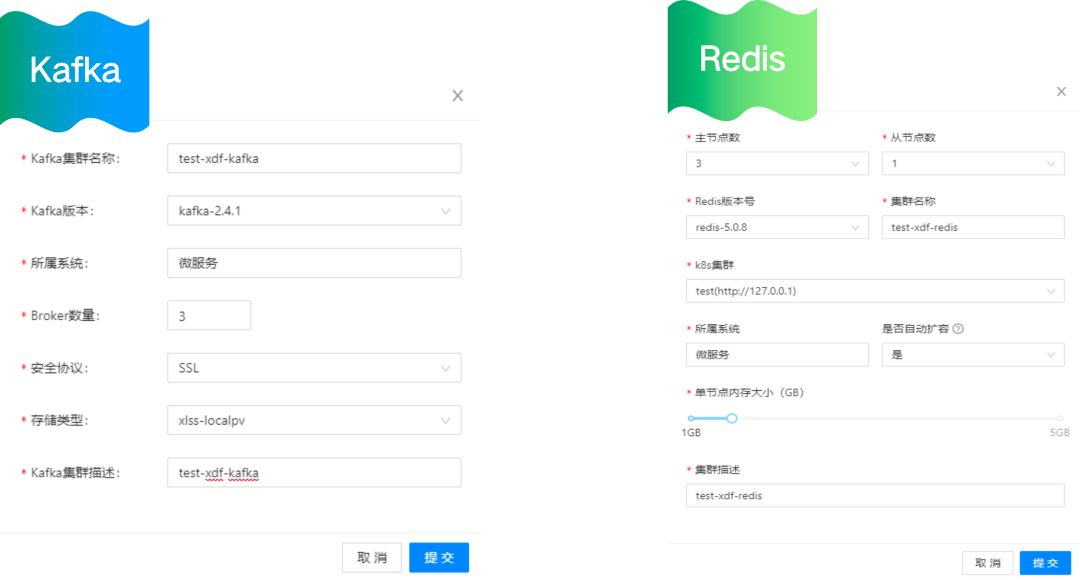
<center>用户申請中間件服務示例</center>
這是用户申請中間件服務的示例:用户通過管理台申請服務,填寫相關的配置信息後,申請通過後,就可以在 K8s 集羣裏面創建相應的服務了。
基於 KubeSphere 部署 XLSS
<b/>如果希望使用 xlss 存儲,那該怎麼部署呢?
若是首次部署,首先要做好本地磁盤的規劃,創建好提供給 xlss 使用的存儲空間。然後,就是將 xlss 的各個組件運行到 K8s 集羣中。將 xlss 組件部署到 K8s 集羣中,我們藉助了 KubeSphere 的 CI/CD 流水線。自定義流水線一共 5 步,實現將 xlss 組件從靜態代碼到運行在 K8s 中的容器的轉換,高度自動化維護。
<b/>CI/CD 流水線如下圖所示:
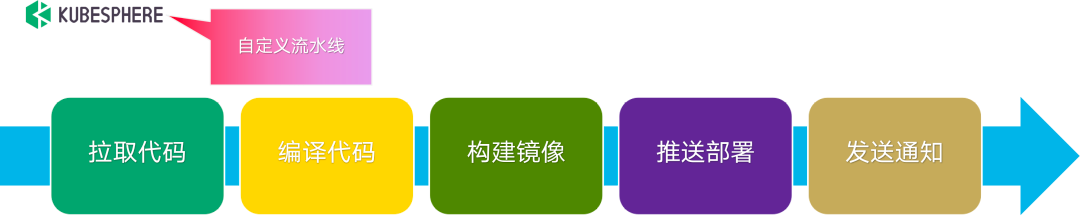
<center>CI/CD 流水線</center>
Road Map
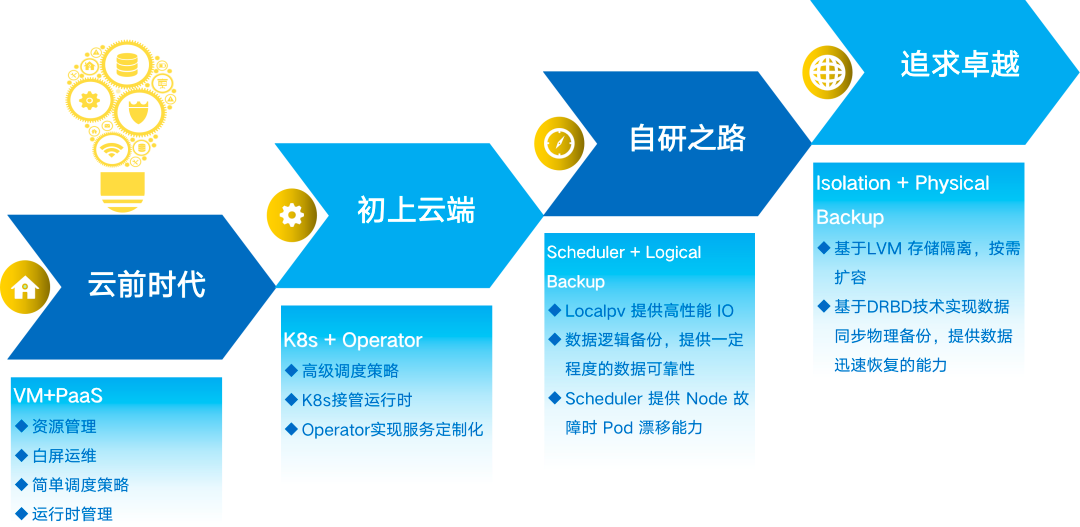
<center>Road Map</center>
目前,新東方的有狀態服務容器化建設大致可分成 4 階段。
<b/>第一階段:“雲前時代”。
有狀態服務容器化的起點,確定了容器化的目標。這個階段有狀態服務主要特徵是 VM+PaaS 組合的模式管理有狀態服務。實現的主要功能:資源管理、白屏運維、簡單調度策略、運行時管理。
<b/>第二階段:“初上雲端”。
從這個階段開始,嘗試將有狀態服務從 VM 中解脱出來,遷移到 K8s 平台。這個階段有狀態服務主要特徵是 K8s+Operator 組合的模式管理有狀態服務。
這時,運行時被託管到 K8s,有狀態服務由 Opeartor 接管,自動化程度顯著提高。此時也暴露出一些不足:比如遠端存儲的性能不夠好,本地存儲的可用性不能保證。
<b/>第三階段:“自研之路”。
主要是新東方自研 xlss 的實踐階段,前面章節已有涉及。此階段有狀態服務建設的典型特徵:Scheduler + Logical Backup 組合模式。這基本達到了我們期望的:本地存儲 + 動態供給 + 數據可用性保證。但事情永遠都不會那麼完美,那還有那些瑕疵呢?
-
數據恢復時長取決於數據量大小,如果數據量很大,恢復時間也會增大,在 node 異常發生的情況下,這就增大了有狀態服務的不可用時間。
-
現在 PV 數據還沒能做到存儲隔離,無法約束應用對存儲的使用量,會存在一定的風險。
瑕不掩瑜,在小規模存儲場景:如 redis、kafka 等還是有用武之地的,但是對於大數據量的服務,目前 xlss 的能力還有些勉強。
<b/>第四階段:“追求卓越”。
在這個階段,有狀態服務建設的典型特徵:Isolation + Physical Backup 組合模式。重點會解決第三階段發現的瑕疵。大致的解決思路是:利用 LVM 技術實現存儲的隔離;利用 DRBD 技術,增加 DRBD 同步物理備份能力,實現應用數據的同步實時備份,解決由於數據量大導致恢復時間增長的問題。
在使用 DRBD 技術時,有一個需要權衡的地方,那就是副本數量的設置。若副本數量設置多些,則會增大存儲資源使用量;若副本數量設置少些,在 K8s 集羣 node 異常情況下,有狀態服務 Pod 漂移可選擇的 node 數量就會減少。最終需要根據業務場景做出合理選擇。
本文由博客一文多發平台 OpenWrite 發佈!
- Kubernetes CRI 分析 - kubelet 創建 Pod 分析
- 終於有人把 ZFS 文件系統講明白了
- KVSSD: 結合 LSM 與 FTL 以實現寫入優化的 KV 存儲
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 以 Serverless 的方式實現 Kubernetes 日誌吿警
- Knative Autoscaler 自定義彈性伸縮
- 科技熱點週刊|Zoom 1 億美元、Docker 收費、380 億美元 Databricks
- 科技熱點週刊|Linux 30 週年、Horizon Workroom 發佈、Humanoid Robot、元宇宙
- KubeSphere 核心架構淺析
- Go 語言實現 WebSocket 推送
- 基於 SDN 編排的雲安全服務
- 複雜應用開發測試的 ChatOps 實踐
- 基於 Formily 的表單設計器實現原理分析
- SegmentFault 基於 Kubernetes 的容器化與持續交付實踐
- 基於 Kubernetes 的雲原生 AI 平台建設
- 雲原生|新東方在有狀態服務 In K8s 的實踐
- 在線教育平台青椒課堂:使用 KubeSphere QKE 輕鬆實現容器多集羣管理
- 人均雲原生2.0,容器的圈子內卷嗎?
- 存儲大師班:NFS 的誕生與成長