抓取了1400家科技公司的招聘資訊,我發現數據工程師比資料科學家更有市場 - 知乎
「作為資料科學家,我還有機會嗎?」不,你更應該成為資料工程師。
選自Medium,作者:Mihail Eric,機器之心編譯,編輯:小舟。

資料無處不在,而且只會越來越多。在過去的 5-10 年內,資料科學已經吸引了越來越多的新人投身於此。
但如今資料科學的招聘狀況如何?亞馬遜 Alxea 團隊的機器學習科學家 Mihail Eric 收集了多家公司的招聘資訊後,在個人部落格中撰寫了一篇分析文章,闡述自己的思考。

資料勝於雄辯,他對自 2012 年以來 Y-Combinator 孵化的每家公司釋出的資料領域職位進行了分析,研究問題包括:
- 在資料領域,公司最常招聘的職位是什麼?
- 人們常討論的資料科學家的需求究竟有多大?
- 公司看重的這些技能是引發當今資料革命的技能嗎?
以下是部落格文章的主要內容:
方法
我選擇對 YC 風投公司進行分析,這些公司聲稱將某種資料作為其價值主張的一部分。
主要關注 YC 是因為其提供了易於搜尋(可抓取)的公司目錄。此外,作為一個特別有遠見的孵化器,它已經為全球眾多領域的公司提供投資長達十年之久,我覺得他們為本次分析研究提供了一個具有代表性的市場樣本。但請注意,我沒有分析超大型科技公司。
我抓取了自 2012 年以來每家 YC 公司的首頁網址,建立起一個包含 1400 家公司的初始池。
為什麼是從 2012 年開始呢?2012 年,AlexNet 在 ImageNet 競賽中獲獎,掀起了如今機器學習和資料建模的熱潮,最早的一批資料優先(data-first)公司由此誕生。
我對初始池執行了關鍵詞過濾,以減少需要瀏覽的公司量。具體而言,我只考慮了其網站至少包含以下術語之一的公司:AI、CV、NLP、自然語言處理、計算機視覺、人工智慧、機器、ML、資料。同時不考慮那些網站連結故障的公司。
這樣的操作應該會產生大量錯誤的結果,我意識到將對各個網站進行更細粒度的手動檢查以瞭解相關角色,因此我儘可能地優先考慮高召回率。
在這個篩選過的資源池中,我遍歷了每個網站,找到了他們釋出招聘資訊的位置,並記下了標題中包含資料、機器學習、NLP 或 CV 的所有職位。這讓我建立了一個來自大約 70 個不同公司的招聘職位的資源池。
也有點小失誤:其中我錯過了一些公司,有些網站雖然招聘資訊很少,但是其實正在招聘。此外,有些公司沒有正式的招聘頁面,但而是要求應聘者直接通過電子郵件與他們聯絡。我忽略了這兩種型別的公司,它們不在本次分析研究中。
另一件事是,這項研究的大部分都是在 2020 年的最後幾個星期內完成的。隨著公司定期更新招聘頁面,開放的職位可能已經改變,但我認為這對得出的結論影響不大。
資料從業者應該負責什麼?
在深入研究結果之前,值得花一些時間來搞清楚每種資料領域職位通常負責什麼。我將花時間介紹以下四個職位:
- 資料科學家負責在統計和機器學習中使用各種技術來處理和分析資料,通常負責構建模型以探究從某些資料來源中能夠學到的內容,但模型通常是原型級別而非生產級別;
- 資料工程師負責開發一套強大且可擴充套件的資料處理工具 / 平臺,必須熟悉 SQL / NoSQL 資料庫的整理和構建 / 維護 ETL 流水線;
- 機器學習(ML)工程師通常既負責訓練模型,又負責生產模型,他們需要熟悉一些高階 ML 框架,還必須能夠輕鬆構建模型的可擴充套件訓練,推理和部署流水線;
- 機器學習(ML)科學家致力於前沿研究,他們通常負責探索可以在學術會議上發表的新想法。在移交給 ML 工程師進行生產之前,機器學習科學家通常只需要對新的 SOTA 模型進行原型製作。
值得一提的是,與傳統資料科學家相比,開放資料工程師的職位增加了不少,在這種情況下,在公司僱用的原始量上,資料工程師比資料科學家多了大約 55%,而機器學習工程師的數量與資料科學家的數量大致相同。但如果檢視各個職位的名稱,就會發現似乎有些重複。
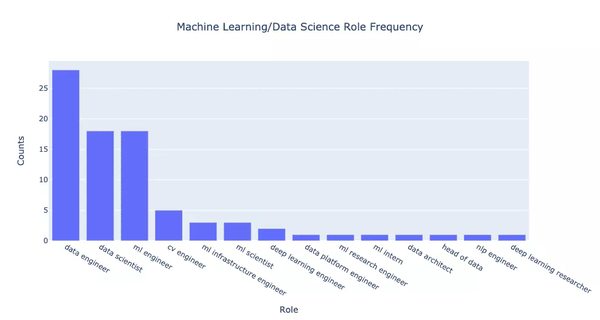
我只通過合併職位來提供粗略的分類即在不同職位角色負責的內容大致相同的情況下將其合併為一個名稱。其中包括以下等價關係集:
- NLP 工程師≈CV 工程師≈ML 工程師≈深度學習工程師(儘管領域可能不同,但職責大致相同)
- ML 科學家≈深度學習≈ML 實習生
- 資料工程師≈資料架構師≈資料主管≈資料平臺工程師
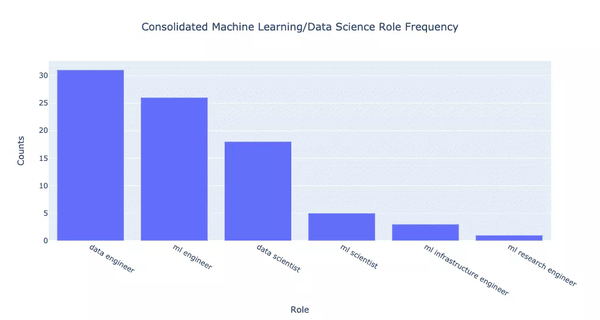
按百分比描述的話是:
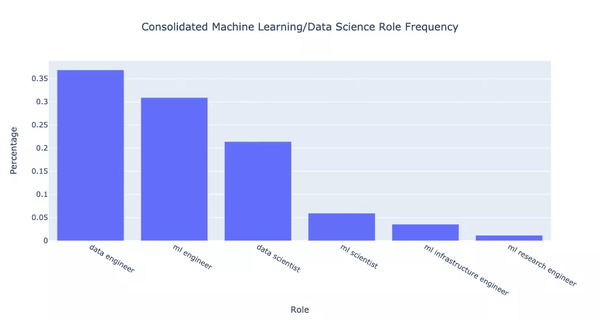
總體而言,合併會使差異更加明顯。開放資料工程師比資料科學家多大約 70%。此外,開放 ML 工程師比資料科學家多大約 40%。機器學習科學家的數量也只有資料科學家的大約 30%。
結論
與其他資料驅動型職位相比,資料工程師的需求越來越高。從某種意義上說,這代表了該方向正朝著更廣闊的領域發展。
5 到 8 年前,機器學習變得炙手可熱,各個公司需要的是能夠對資料進行分類的人才。但是之後 Tensorflow 和 PyTorch 等框架發展得很好,使得著手開始進行深度學習和機器學習的能力大眾化,隨之而來的是資料建模技能商品化。如今,發展瓶頸在於幫助公司獲得有關生產級別資料問題的機器學習和建模的意見。比如要考慮以下問題:
- 如何註釋資料?
- 如何處理和清理資料?
- 如何將其從 A 移到 B?
- 如何儘快完成這些任務?

所有的這些都意味著,職位要求具有良好的工程技能,偏向於資料的傳統軟體工程可能是我們目前真正需要的。但是否意味著您不應該學習資料科學?並不是。而是意味著競爭將更加艱難。對於正準備訓練成為資料科學人才的初學者來說,可用的職位將會越來越少。當然,有效地分析資料並從資料中提取可行見解的人一直需要,但這些見解必須是優秀的。
很明顯,公司經常需要混合型資料從業者,即可以構建和部署模型的人。或者更簡潔地說,可以使用 Tensorflow,但也可以從原始碼構建它的人。
本研究的另一個發現是 ML 研究職位非常少。機器學習研究傾向於獲得相當大的資源支援,因為這是頂尖級的研究,例如 AlphaGo 和 GPT-3。但是對於許多公司,尤其是早期公司而言,頂尖的 SOTA 技術可能不再是必需的。達到最佳模型效能的 90%,同時擴充套件到 1000 個以上的使用者,通常對他們來說更有價值。
但你可能會在工業界的研究實驗室裡找到很多這樣的角色,他們可以在很長一段時間裡承受資本密集型賭注,而不是在種子輪就開始做產業 demo 準備接 A 輪融資。
如果沒有其他問題,我認為最重要的是讓新來者對資料欄位的期望合理並經過校準。我們必須承認,資料科學現在已經今非昔比,只有當我們知道自己身處何處時,我們才知道要去到哪裡。
- 疫情催化下的全球遠端工作調查報告
- 給產品經理的9千字總結:系統間資料傳輸關注這些就夠了:介面、otter、log4j、SFTP、MQ……
- 安全新手入坑——如何在虛擬機器中安裝作業系統 VMware Tools(T)的安裝
- 王者連跪是什麼感覺?
- 抓取了1400家科技公司的招聘資訊,我發現數據工程師比資料科學家更有市場 - 知乎
- 21中國礦業大學北京\礦大北京計算機考研複試經驗
- Hyperledger Fabric學習筆記(二)- Fabric 2.2.1環境搭建
- 以向量運算為例,總結運算子過載
- svn認證失敗,解決方案
- Cryptographie
- 跟我學Android之七 資原始檔
- 當檔案記憶體使用量並列印檔案超過100k自動結束程式
- R語言 lightgbm 演算法優化:不平衡二分類問題(附程式碼)
- 2021年軟體開發的七大趨勢
- 實現微服務會帶來哪些挑戰?
- 【重點】初窺Linux 之 我最常用的20多條命令
- 如何使用這個 KDE Plasma 文字編輯器?
- SCRIPT7002: XMLHttpRequest: 網路錯誤 0x2ef3的解決方法
- 程式設計師漫畫:終極廣告攔截器
- 猜數字遊戲,遊戲介面