SegmentFault 基於 Kubernetes 的容器化與持續交付實踐

SegmentFault[1] 是一家綜合性技術社群,由於它的內容跟程式設計技術緊密相關,因此訪問量的波動也和這一群體的作息時間深度繫結。通常情況下 web 頁面的請求量峰值在 800 QPS 左右,但我們還做了前後端分離,所以 API 閘道器的峰值 QPS 是請求量峰值的好幾倍。
SegmentFault 架構演變
SegmentFault 作為一家技術社群, 它的系統架構演變過程是很有意思的。
-
2012 年,我還在北京的一家公司工作,我在出租屋裡寫下 SegmentFault 的第一行程式碼時,根本沒有想到它未來會成為我的事業。當時我的想法很簡單,就是想幫助中文開發者用母語在像 Stack Overflow 這樣的網站上提問,因此它的第一個版本非常簡陋,考慮到它的訪問量很少,以及我自己的經濟能力不足,於是將它放在了國外的 VPS 託管商 Linode 上,所有的應用、資料庫、快取都擠在一個例項上。
-
2013-2014 年,我單獨出來創業,SegmentFault 的業務也逐漸步入正軌。我們選擇了自己購買伺服器去機房託管,當然伺服器也是從淘寶上購買的二手伺服器,出現問題的時候,我們的團隊在外地又去不了機房,只能等管理員去機房幫我們解決。在 2014 年的時候,SegmentFault 網站被 DDos 攻擊,機房為了不連累其他伺服器,直接把我們的網線拔掉了。
-
2014-2019 年,國內雲端計算技術從起步到逐漸成熟,於是我們把整個網站從物理伺服器遷移到了雲服務上。當然使用上並沒有什麼不同,只是把物理機器替換成了虛擬主機。
-
2020 年至今,隨著雲原生理念的興起,我們的業務模式也發生了很大變化,為了讓系統架構適應這些變化,我們把網站的主要業務都遷移到了 KubeSphere 上。
為什麼選擇 Kubernetes ?
SegmentFault 的系統架構發展遇到不少挑戰,促使我們不得不往 K8s 架構上遷移。
-
首先,雖然我們是一家小公司,但業務線非常複雜。思否整個公司在 30 人左右,技術人員大約只佔其中三分之一,所以承載這麼大的業務量,負擔還是很重的。而且創業公司的業務線調整非常頻繁,臨時性工作也比較多,傳統的系統架構,在應對這種伸縮性要求比較高的場景是比較吃力的。
-
其次,複雜的場景引發了複雜的配置管理,不同的業務要用到不同的服務、不同的版本,即使用自動化指令碼,效率也不高。
-
另外,我們的工作人員不足,所以沒有專職運維,現在 OPS 的工作是由後端開發人員輪值的。但後端開發人員還有自己本職工作要做,所以我們期待最理想的場景是能把運維工作全部自動化。
-
最後也是最重要的一點,就是我們要控制成本,這是高情商的說法,低情商就是一個字“窮”。當然,如果資金充足,以上的問題都不是問題,但是對於創業公司(特別是像我們這種訪問量比較大,但是又不像電商、金融等收益好的公司)來說,我們必將且長期處於這個階段。因此能否控制好成本,是一個非常重要的問題。
前後端分離
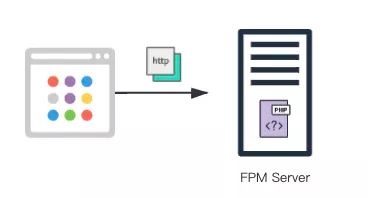
2020 年以前,SegmentFault 的網站還是非常傳統的後端渲染頁面的方法,所以服務端的架構也非常簡單。服務端將瀏覽器的 http 請求轉發到後端的 php 服務,php 服務渲染好頁面後再返回給瀏覽器。這種架構用原有的部署方法還能支撐,也就是在各個例項上部署 php 服務,再加一層負載均衡就基本滿足需求了。
然而隨著業務的持續發展,後端渲染的方式已經不適合我們的專案規模了,因此我們在 2020 年做了架構調整,準備將前後端分離。前後端分離的技術特點我在這裡就不贅述了,這裡主要講它給我們帶來了哪些系統架構上的挑戰。一個是入口增多,因為前後端分離不僅涉及到客戶端渲染 (CSR),還涉及到服務端渲染 (SSR),所以響應請求的服務就從單一的服務變成了兩類服務,一類是基於 node.js 的 react server 服務(用來做服務端渲染),另一類是 基於 php 寫的 API 服務(用來給客戶端渲染提供資料)。而服務端渲染本身還要呼叫 API,而我們為了優化服務端渲染的連線和請求響應速度,還專門啟用了使用專有通訊協議的內部 API 服務。
所以實際上我們的 WEB SERVER 有三類服務,每種服務的環境各不相同,所需的資源不同、協議不同,各自之間可能還有相互連線的關係,還需要負載均衡來保障高可用。在快速迭代的開發節奏下,使用傳統的系統架構很難再去適應這樣的結構。
我們迫切需要一種能夠快速應用、方便部署各種異構服務的成熟解決方案。
Kubernetes 帶來了什麼?
開箱即用
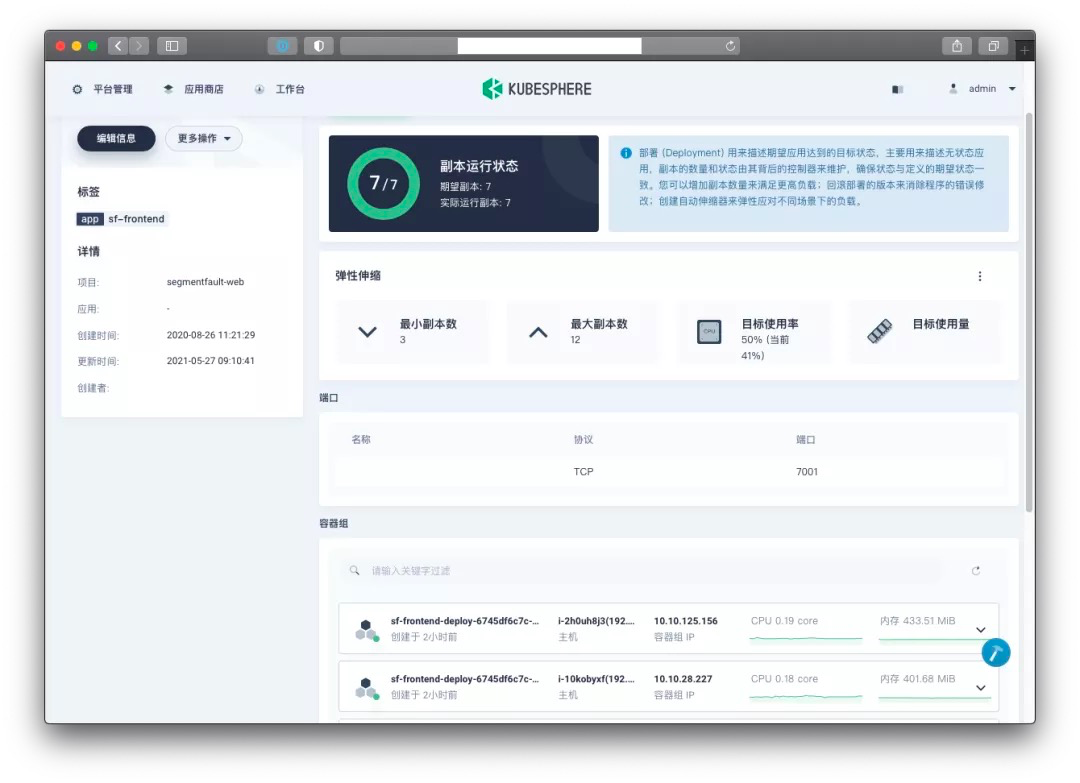
首先是開箱即用,理論上來說,這應該是 KubeSphere 的優點,我們直接點一點滑鼠就可以打造一個高可用的 K8s 叢集。這一點對我們這種沒有專職運維的中小團隊來說很重要。根據我的親身經歷,要從 0 到 1 搭建一個高可用的 K8s 叢集,還是有門檻的,沒有接觸過這方面的運維人員,一時半會搞不定,其中的坑也非常多。
如果雲廠商能提供這種服務是最好的,我們不用在服務搭建與系統優化上花費太多時間,可以把更多的精力放到業務上去。之前我們還自己搭建資料庫、快取、搜尋叢集,後來全部都使用雲服務。這也讓我們的觀念有所轉變,雲時代的基礎服務,應該把它視為基礎設施的一部分加以利用。
用程式碼管理部署
如果能把運維工作全部用程式碼來管理,那就再理想不過了。目前 K8s 確實給我們提供了這樣一個能力,現在我們每個專案都有一個 Docker 目錄,裡面放置了不同環境下的 Dockerfile、K8s 配置檔案等。不同的專案、不同的環境、不同的部署,一切都可以在程式碼中描述出來加以管理。 比如我們之前提到同樣的 API 服務,使用兩種協議,變成了兩個服務。在現在的架構下,就可以實現後端程式碼一次書寫、分開部署。其實這些檔案就代替了很多部署操作,我們需要做的只是定義好以後執行命令把它們推送到叢集。
而一旦將這些運維工作程式碼化以後,我們就可以利用現有的程式碼管理工具,像寫程式碼一樣來調整線上服務。更關鍵的一點是,程式碼化之後無形中又增加了版本管理功能,這離我們理想中的全自動化運維又更近了一步。
持續整合,快速迭代
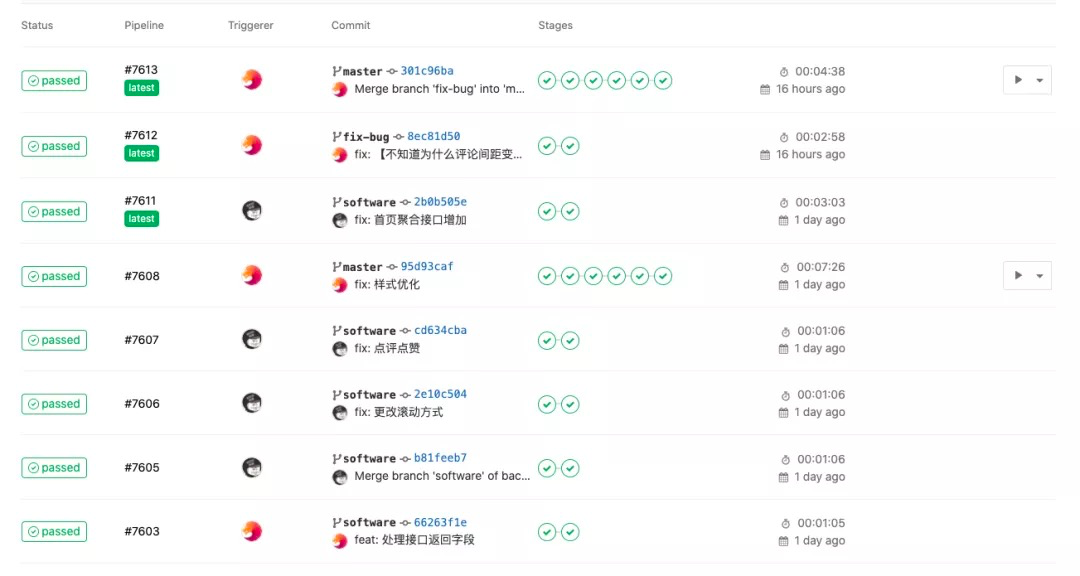
持續整合標準化了程式碼釋出流程,如果能夠將持續整合和 K8s 的部署能力結合起來,無疑能大大加快專案迭代速度。而在使用 K8s 之前,我們就一直用 GitLab 作為版本管理工具,它的持續整合功能對我們來說也比較適用。在做了一些指令碼改造之後,我們發現它也能很好地服務於現有的 K8s 架構,所以也沒有使用 K8s 上諸如 Jenkins 這樣的服務來做持續整合。
步驟其實也很簡單,做好安全配置就沒什麼問題。我們本地跑完單元測試之後,會自動上線到本地的測試環境。在程式碼合併到上線分支後,由管理員點選確認進行上線步驟。然後在本地 build 一個映象推送到映象伺服器,通知 K8s 叢集去拉取這個映象執行上線,最後執行一個指令碼來檢查上線結果。整個流程都是視覺化可追蹤的,而且在程式碼管理介面就可以完成,方便開發者檢視上線進度。
總結經驗
管理好基礎映象
目前我們用一個專門的倉庫來管理這些基礎映象,這可以使開發人員擁有與線上一致的開發環境,而且後續的版本升級也可以在基礎映象中統一完成。 除了將 Dockerfile 檔案統一管理以外,我們還將映象 build 服務與持續整合結合起來。每個 Dockerfile 檔案都有一個所屬的 VERSION 檔案,每次修改裡面的版本號並提交,系統都會自動 build 一個相應的映象並推送到倉庫。基礎映象的管理工作完全自動化了,大大減少了人為操作帶來的錯誤與混亂。
KubeSphere 使用經驗
-
不要把日誌服務放到叢集裡。這一點在 KubeSphere 文件中就有提及。具體到日誌服務,主要就是一個 Elastic 搜尋服務,自建一個Elastic 叢集即可。因為日誌服務本身負載比較大,而且對硬碟的持續性需求高,如果你發現日誌服務本身就佔據了叢集裡相當大的資源,就得不償失了。
-
如果生產環境要保證高可用,還是要部署 3 個或以上的節點。從我們使用的經驗來看,主節點偶爾會出現問題。特別是遇到節點機器要維護或者升級的時候,多個主節點可以保證業務的正常執行。
-
如果你本身不是專門提供資料庫或快取的服務商,這類高可用服務就不要上 K8s,因為要保證這類服務高可用本身就要耗費你大量的精力。我建議還是儘量用雲廠商的服務。
-
副本的規模和叢集的規模要匹配。如果你的容器只有幾個節點,但一個服務裡面擴充套件了上百個副本,系統的排程會過於頻繁從而把資源耗盡。所以這兩者要相匹配,在系統設計的時候就要考慮到。
最後一點感想:當做完容器化後,會發現應用在叢集裡執行的時候並不需要佔用那麼多臺伺服器。這是因為降低了資源的粒度,所以可以做更多的精細化規劃,因此使用效率也提高了。
腳註
[1] SegmentFault: http://segmentfault.com/
作者
祈寧 SegmentFault CTO & 聯合創始人
- Kubernetes CRI 分析 - kubelet 建立 Pod 分析
- 終於有人把 ZFS 檔案系統講明白了
- KVSSD: 結合 LSM 與 FTL 以實現寫入優化的 KV 儲存
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 以 Serverless 的方式實現 Kubernetes 日誌告警
- Knative Autoscaler 自定義彈性伸縮
- 科技熱點週刊|Zoom 1 億美元、Docker 收費、380 億美元 Databricks
- 科技熱點週刊|Linux 30 週年、Horizon Workroom 釋出、Humanoid Robot、元宇宙
- KubeSphere 核心架構淺析
- Go 語言實現 WebSocket 推送
- 基於 SDN 編排的雲安全服務
- 複雜應用開發測試的 ChatOps 實踐
- 基於 Formily 的表單設計器實現原理分析
- SegmentFault 基於 Kubernetes 的容器化與持續交付實踐
- 基於 Kubernetes 的雲原生 AI 平臺建設
- 雲原生|新東方在有狀態服務 In K8s 的實踐
- 線上教育平臺青椒課堂:使用 KubeSphere QKE 輕鬆實現容器多叢集管理
- 人均雲原生2.0,容器的圈子內卷嗎?
- 儲存大師班:NFS 的誕生與成長