儲存大師班:NFS 的誕生與成長

作者| QingStor 黃蒙
我們為什麼需要 “網路檔案協議”
儲存檔案是大家日常工作生活中最常見的需求,隨著檔案數量和佔用儲存空間的上升,以及在一定範圍內共享訪問檔案的需求產生,我們自然需要把儲存檔案的工作從單個計算機裝置中剝離出來,作為一個單獨的服務資源(或物理硬體)來對外提供儲存功能,提供更大的容量的同時,為多個終端通過網路共享訪問。
這裡提到的儲存裝置就是我們常說的 NAS(Network Attached Storage:網路附屬儲存)。
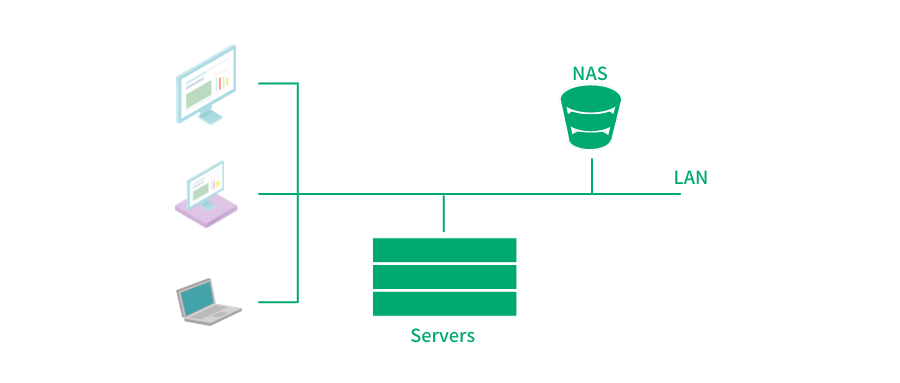 常見 NAS 架構
常見 NAS 架構
而終端通過網路來共享訪問 NAS,需要標準的協議規範。NFS 就是其中最重要也是應用最廣泛的協議標準之一(其它流行的網路檔案協議還有 SMB[1] 協議,後續會有專門的文章進行介紹,盡請期待)。今天我們就來聊聊 NFS 協議。
不斷髮展的 NFS
1. 簡單好用的無狀態協議誕生
NFS 第一次出現在我們的視野中,是在 1985 年。NFS version2 作為 SunOS 2.0 的元件正式釋出。所以在當時把它叫做 “Sun 網路檔案系統” 可能更為貼切。另外,你沒有看錯,第一個正式對外發布的版本就是 v2 版本(v1 版本從未對外正式釋出,這也是我們從不討論 NFS v1 的原因)。
不過 NFS 並不是最早的網路檔案系統,彼時已經有一些更早的網路檔案系統存在,比如 UNIX SVR3 系統中包含的 RFS(Remote File System)[2] RFS 已經引入了 RPC(Remote Procedure Call)概念,併成為 NFS v2 的借鑑的範本。但 RFS 也有自己明顯的問題,比如其為每個客戶端開啟檔案記錄狀態(即有狀態協議),所以很難應對服務端宕機或重啟的情況。NFS v2 為了在設計層面很好的解決 RFS 的缺陷,設計成了一個完全無狀態的協議。
1995 年,NFS v3 正式釋出。此時 NFS 協議的開發已經不再完全依賴 Sun 公司,而是多家公司共同主導完成. NFS v3 包含眾多優化,但大多數可以認為是效能層面的優化。總體看來,NFS v3 仍然遵循無狀態協議的設計。
無狀態協議的設計,自然是降低了應對服務端宕機重啟情況的處理難度。但想要徹底掙脫“有狀態資訊”的束縛並不容易。比如,作為網路檔案協議,就需要支援 “檔案鎖” 操作,但鎖資訊天然就是一種“狀態資訊”。所以在 NFS v2/v3 執行的環境中,NFS 將這部分負擔 “外包給”了 NLM(Network Lock Manager)。當 NFS Client 接收到一個檔案鎖請求時,會產生一個 NLM 協議的 RPC 呼叫,而不是產生一個 NFS 協議的 RPC 呼叫。但這樣 NLM 就成為了一個 “有狀態” 協議。所以它需要處理出現服務端崩潰、客戶端崩潰、網路分割槽出現後的故障恢復問題。NFS v2/v3 協議與 NLM 的配合工作總體來說不夠協調(比如 NLM 協議本身會標記和識別每把鎖由哪個程序申請和持有,但 NFS server 處理讀寫請求時,卻無法區分請求來自於哪個遠端程序),這也導致了難以完美的實現鎖邏輯。
即便拋開檔案鎖的問題不談,無狀態協議設計本身也帶來了新的問題。NFS 服務作為“無狀態服務”,無法記錄各個 NFS 協議客戶端開啟檔案的狀態,也就沒有簡單直接的辦法判斷檔案內容是否已經被其它客戶端修改,即 cache 是否還有效。在 NFS v2/v3 協議中,NFS 協議客戶端通常將檔案的修改時間和檔案大小儲存在 cache 詳細資訊中,以一個時間間隔,定期對 cache 進行有效性驗證:NFS 協議客戶端獲取當前的檔案屬性,和 cache 中的修改時間及檔案大小做比較,如果仍一致,則假定檔案沒有修改過,cache 仍然有效;如果不匹配,則認為檔案發生了了變化,cahce 不再有效。這樣的方式顯然是低效的。而更不幸運的是,由於很多檔案系統儲存時間戳的精度不足,NFS 協議客戶端無法探測出那些在一個較粗精度的時間單位(秒)中連續的修改,比如剛校驗過 cache 有效性後,同一秒內又發生了更改(覆蓋寫),那麼從修改時間和檔案大小都觀察不出需要重新更新cache。這種情況下,只有該 cache 被 lru 驅逐,或者檔案後續被再次修改,否則 NFS 協議客戶端無法感知到檔案的最新變化。
2. 無狀態到有狀態,進化為成熟單機網路檔案系統
2002 年 NFS v4.0 版本釋出。此時 NFS 協議的開發完全由 IETF 主導,最大的一個變化就是 NFS 協議的設計從無狀態協議變為有狀態協議。
從無狀態協議再次演變為有狀態協議,並不是追求一種 old fasion,而是因為當前已經具備了更好的工程能力,來設計開發出足以應對有狀態協議設計下複雜問題的機制(當然,這背後的動力顯然也是拜常年忍受無狀態設計中的種種缺陷之苦所賜)。
NFS v4.0 的有狀態設計主要體現在如下幾個方面:
a. 協議自身加入了檔案鎖功能,會維護鎖資訊這樣的狀態資訊,不需要 NLM 協助。
b.在 cache 一致性問題的處理上,NFSv4 支援了 delegation 機制。由於多個客戶端可以掛載同一個檔案系統,為了保持檔案同步,NFSv4可以依靠 delegation 實現檔案同步。當客戶端 A 開啟一個檔案時,NFS 服務端會分配給客戶端 A 一個 delegation。只要客戶端 A 持有 delegation,就可以認為與服務端保持了一致,可以放心的的在 NFS 協議客戶端側做快取等處理。如果另外一個客戶端 B 訪問同一個檔案,則服務端會暫緩處理(即短暫阻塞)客戶端 B 的訪問請求,並向客戶端 A 傳送 RECALL 請求。當客戶端 A 接收到 RECALL 請求後,會將本地快取重新整理到服務端中,然後將 delegation 歸還給服務端,這時服務端開始繼續處理客戶端 B 的請求。
當然,delegation 機制僅能理解為在考慮快取一致性的情況,以一種更加激進的方式進行讀寫處理,所以該機制更應該被理解為是一種效能效率優化,而不是完全解決 cache 一致性問題的方案,因為當 NFS 服務端發現多個客戶端對同一檔案的競爭出現,並回收之前發放的授權後,又會回退到跟 v2/v3 版本中相似的機制去判斷 cache 的有效性。 除了上述兩點,v4.0 版本相較之前的版本還有以下優化:
a. NFSv4 增加了安全性設計,開始支援 RPC SEC-GSS[3] 身份認證。
b.NFSv4 只提供了兩個請求 NULL 和 COMPOUND,所有的操作都整合進了 COMPOUND 中,客戶端可以根據實際請求將多個操作封裝到一個 COMPOUND 請求中,增加了靈活性的同時減少了互動次數,大大提高了效能。
c.NFSv4 版本中修改了檔案屬性的表示方法,顯著增強對 Windows 系統的相容性,而幾乎同時,微軟開始把 SMB 協議重塑成 CIFS(Common Internet FileSystem),這看起來絕非巧合,可見兩者的競爭意味。 經過上面這些改進,可以說 NFS 已經進化成為了成熟高效的單機網路檔案系統,但是軟體的世界已經慢慢向檔案系統提出了更多擴充套件性的需求和更多的企業級特性需求,NFS v4.0 版本對此還未給出答案。
3. 具備更強擴充套件性,企業級叢集檔案系統雛形已現
2010 年及 2016 年, NFS v4 的演進版本 v4.1 和 v4.2 陸續釋出。
2010 年,NFS v4.1 的問世,讓 NFS 向叢集檔案系統的方向邁出了重要一步 --- 因為其引入了並行檔案系統的概念(Parallel NFS/pNFS):即在協議層面將元資料與資料分離,創造出元資料節點和資料節點的角色,對資料的訪問具備了一定擴充套件性。並行訪問資料的設計也讓整體吞吐提升到新的高度,這與很多現代分散式檔案系統思路相似。
但需要指出的是,在此設計中,元資料的處理擴充套件性仍未得到解決。另外作為有狀態協議,在用來保證高可用性的主備架構中,由於備節點中並沒有主節點中維護的狀態資訊,所以故障切換過程很難做到足夠平滑。
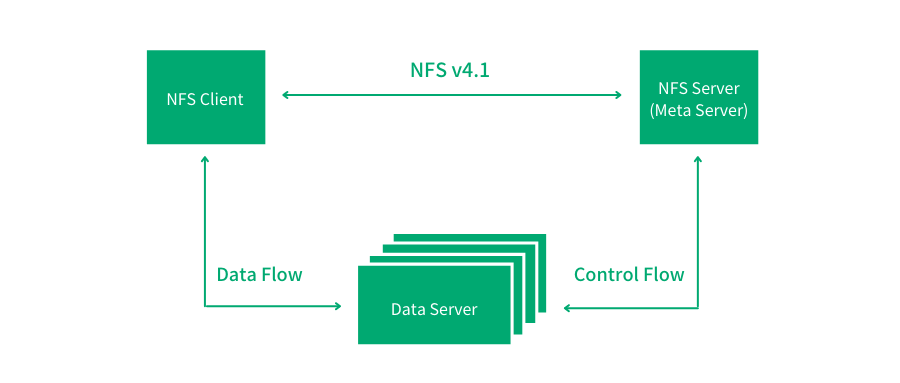 Parallel NFS基本架構圖
Parallel NFS基本架構圖
除此之外,NFS 協議開始加入了更多的資料中心級企業級特性:
NFSv4.1 開始支援 RDMA(Remote Direct Memory Access)[4],並在 NFS v4.2 中開始支援稀疏檔案(sparse file)以及支援 server 側拷貝(Server-Side Copy)。
這都幫助 NFS 協議可以更好地支撐更加嚴肅的資料中心/企業級應用。
4. NFS 的繼續進化和工程層面的探索:核心態 vs 使用者態
NFS 協議不斷的發展,在複雜性不斷提高的同時,也在叢集擴充套件性/可用性方面不斷探索,但這無疑也給工程實現層面提出了新的挑戰。在 Linux 世界中,最常使用的就是核心態的 nfsd 服務,但是隨著機制和架構的複雜性的增加,在使用者態去實現一個 NFS 服務似乎成為了一個工程更合理的方案。作為 NFS 在 Linux 世界中的競爭對手,Samba[5] 服務就是基於使用者態打造了一套較為完整的叢集方案。
針對這一問題,開源社群也給出了一些探索,其中最具影響力同時也是應用最廣泛的要數 nfs-ganesha[6] 專案,該專案目前由 RedHat 維護,其在使用者態實現了完整的 NFS 服務功能。
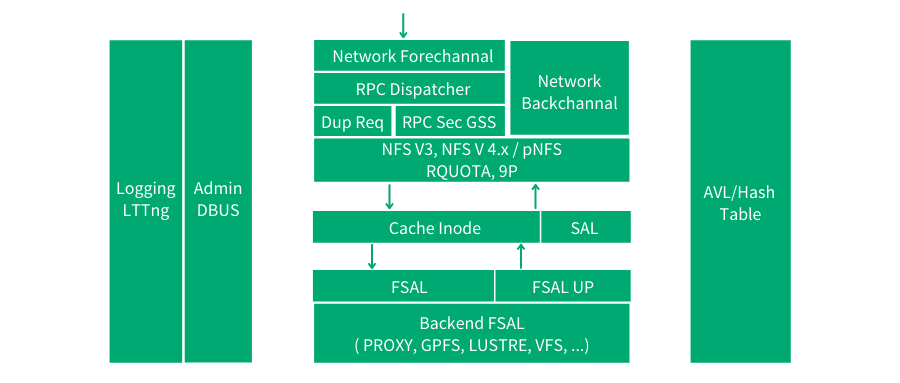 NFS Ganesha 架構圖
NFS Ganesha 架構圖
如圖 nfs-ganesha 架構圖所示,該專案本身專注於協議處理邏輯(支援所有的 NFS 協議版本),同時設計獨立的 SAL(State abstraction layer)抽象層,和 FSAL(File-System abstraction layer)抽象層。前者有助於在處理有狀態協議的“狀態”時擴充套件一些叢集邏輯,而後者方便接入包括本地 VFS 檔案系統和各種開源/商業分散式儲存。這樣的設計有利於藉助外部中介軟體和服務來打造更好的叢集邏輯,為更多開放性的設計提供了空間,同時也通過對接更多的後端儲存系統來保證社群活力和擴大應用範圍。
在未來相當長的一段時間裡,NFS 協議仍會承擔重要的角色,而 NFS 的工程實踐想要進一步獲得發展,滿足日漸膨脹及複雜的需求,仍需要在使用者態繼續探索。
結束語
NFS 協議不但是我們平時共享檔案的背後功臣,也在超算和廣電等行業支撐著各類核心業務。 作為一個有多年曆史的網路檔案協議,NFS 有其歷史侷限性,甚至每次迭代都有其沉重的歷史包袱捆綁手腳,但它仍可以被當作檔案系統的經典範例去研究。可以說對 NFS 協議瞭解逐步深入的過程,也是對現代分散式檔案系統重新理解的過程。
參考資料
1 . Why NFS Sucks (Olaf KirchSUSE/Novell, Inc)
http://www.kernel.org/doc/ols/2006/ols2006v2-pages-59-72.pdf
2.Review of "Why NFS Sucks" Paper from the 2006 Linux Symposium
http://nfsworld.blogspot.com/2006/10/review-of-why-nfs-sucks-paper-from.html
3.NFS and file locking
http://docstore.mik.ua/orelly/networking_2ndEd/nfs/ch11_02.htm
4.. NFS各個版本之間的比較(ycnian)
http://blog.csdn.net/ycnian/article/details/8515517
5.. NFS Ganesha Architecture http://github.com/nfs-ganesha/nfs-ganesha/wiki/NFS-Ganesha-Architecture
引用連結
[1] SMB http://en.wikipedia.org/wiki/Server_Message_Block
[2] RFS (Remote File System) http://en.wikipedia.org/wiki/Remote_File_Sharing
[3] RPC SEC-GSS http://en.wikipedia.org/wiki/RPC_SEC-GSS
[4] RDMA http://en.wikipedia.org/wiki/Remote_direct_memory_access
[5] Samba http://en.wikipedia.org/wiki/Samba_(software)
[6] nfs-ganesha http://github.com/nfs-ganesha/nfs-ganesha
- Kubernetes CRI 分析 - kubelet 建立 Pod 分析
- 終於有人把 ZFS 檔案系統講明白了
- KVSSD: 結合 LSM 與 FTL 以實現寫入優化的 KV 儲存
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 雲戰略現狀調查: 歡迎來到多雲時代!
- 以 Serverless 的方式實現 Kubernetes 日誌告警
- Knative Autoscaler 自定義彈性伸縮
- 科技熱點週刊|Zoom 1 億美元、Docker 收費、380 億美元 Databricks
- 科技熱點週刊|Linux 30 週年、Horizon Workroom 釋出、Humanoid Robot、元宇宙
- KubeSphere 核心架構淺析
- Go 語言實現 WebSocket 推送
- 基於 SDN 編排的雲安全服務
- 複雜應用開發測試的 ChatOps 實踐
- 基於 Formily 的表單設計器實現原理分析
- SegmentFault 基於 Kubernetes 的容器化與持續交付實踐
- 基於 Kubernetes 的雲原生 AI 平臺建設
- 雲原生|新東方在有狀態服務 In K8s 的實踐
- 線上教育平臺青椒課堂:使用 KubeSphere QKE 輕鬆實現容器多叢集管理
- 人均雲原生2.0,容器的圈子內卷嗎?
- 儲存大師班:NFS 的誕生與成長