Kafka為什麼吞吐量大、速度快?

Kafka是大資料領域無處不在的訊息中介軟體,目前廣泛使用在企業內部的實時資料管道,並幫助企業構建自己的流計算應用程式。
Kafka雖然是基於磁碟做的資料儲存,但卻具有高效能、高吞吐、低延時的特點,其吞吐量動輒幾萬、幾十上百萬。
但是很多使用過Kafka的人,經常會被問到這樣一個問題,Kafka為什麼速度快,吞吐量大;大部分被問的人都是一下子就懵了,或者是隻知道一些簡單的點,本文就簡單的介紹一下Kafka為什麼吞吐量大,速度快。
一、順序讀寫
眾所周知Kafka是將訊息記錄持久化到本地磁碟中的,一般人會認為磁碟讀寫效能差,可能會對Kafka效能如何保證提出質疑。實際上不管是記憶體還是磁碟,快或慢關鍵在於定址的方式,磁碟分為順序讀寫與隨機讀寫,記憶體也一樣分為順序讀寫與隨機讀寫。基於磁碟的隨機讀寫確實很慢,但磁碟的順序讀寫效能卻很高,一般而言要高出磁碟隨機讀寫三個數量級,一些情況下磁碟順序讀寫效能甚至要高於記憶體隨機讀寫。
這裡給出著名學術期刊 ACM Queue 上的效能對比圖: http://queue.acm.org/detail.cfm?id=1563874
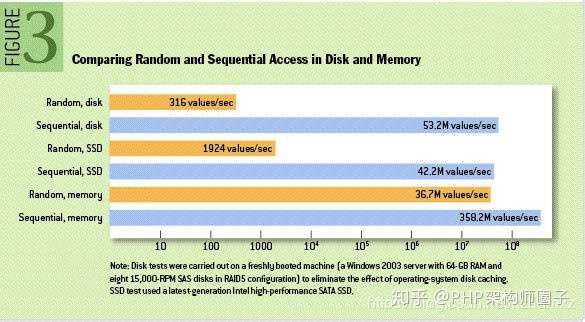
磁碟的順序讀寫是磁碟使用模式中最有規律的,並且作業系統也對這種模式做了大量優化,Kafka就是使用了磁碟順序讀寫來提升的效能。Kafka的message是不斷追加到本地磁碟檔案末尾的,而不是隨機的寫入,這使得Kafka寫入吞吐量得到了顯著提升 。
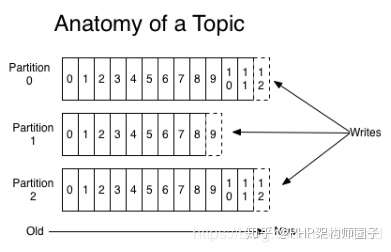
上圖就展示了Kafka是如何寫入資料的, 每一個Partition其實都是一個檔案 ,收到訊息後Kafka會把資料插入到檔案末尾(虛框部分)。
這種方法有一個缺陷—— 沒有辦法刪除資料 ,所以Kafka是不會刪除資料的,它會把所有的資料都保留下來,每個消費者(Consumer)對每個Topic都有一個offset用來表示 讀取到了第幾條資料 。
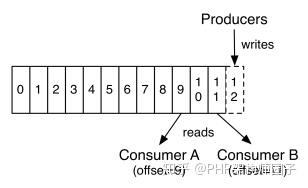
兩個消費者,Consumer1有兩個offset分別對應Partition0、Partition1(假設每一個Topic一個Partition);Consumer2有一個offset對應Partition2。這個offset是由客戶端SDK負責儲存的,Kafka的Broker完全無視這個東西的存在;一般情況下SDK會把它儲存到zookeeper裡面。(所以需要給Consumer提供zookeeper的地址)。
如果不刪除硬碟肯定會被撐滿,所以Kakfa提供了兩種策略來刪除資料。一是基於時間,二是基於partition檔案大小。具體配置可以參看它的配置文件。
二、Page Cache
為了優化讀寫效能,Kafka利用了作業系統本身的Page Cache,就是利用作業系統自身的記憶體而不是JVM空間記憶體。這樣做的好處有:
1避免Object消耗:如果是使用 Java 堆,Java物件的記憶體消耗比較大,通常是所儲存資料的兩倍甚至更多。
2避免GC問題:隨著JVM中資料不斷增多,垃圾回收將會變得複雜與緩慢,使用系統快取就不會存在GC問題
相比於使用JVM或in-memory cache等資料結構,利用作業系統的Page Cache更加簡單可靠。首先,作業系統層面的快取利用率會更高,因為儲存的都是緊湊的位元組結構而不是獨立的物件。其次,作業系統本身也對於Page Cache做了大量優化,提供了 write-behind、read-ahead以及flush等多種機制。再者,即使服務程序重啟,系統快取依然不會消失,避免了in-process cache重建快取的過程。
通過作業系統的Page Cache,Kafka的讀寫操作基本上是基於記憶體的,讀寫速度得到了極大的提升。
三、零拷貝
linux作業系統 “零拷貝” 機制使用了sendfile方法, 允許作業系統將資料從Page Cache 直接傳送到網路,只需要最後一步的copy操作將資料複製到 NIC 緩衝區, 這樣避免重新複製資料 。示意圖如下:
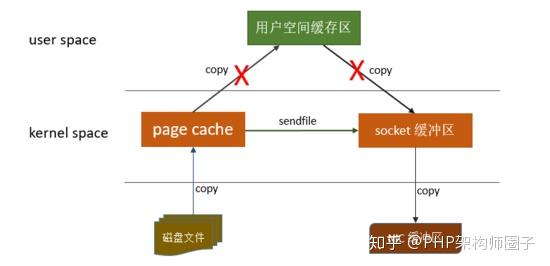
通過這種 “零拷貝” 的機制,Page Cache 結合 sendfile 方法,Kafka消費端的效能也大幅提升。這也是為什麼有時候消費端在不斷消費資料時,我們並沒有看到磁碟io比較高,此刻正是作業系統快取在提供資料。
當Kafka客戶端從伺服器讀取資料時,如果不使用零拷貝技術,那麼大致需要經歷這樣的一個過程:
1.作業系統將資料從磁碟上讀入到核心空間的讀緩衝區中。
2.應用程式(也就是Kafka)從核心空間的讀緩衝區將資料拷貝到使用者空間的緩衝區中。
3.應用程式將資料從使用者空間的緩衝區再寫回到核心空間的socket緩衝區中。
4.作業系統將socket緩衝區中的資料拷貝到NIC緩衝區中,然後通過網路傳送給客戶端。
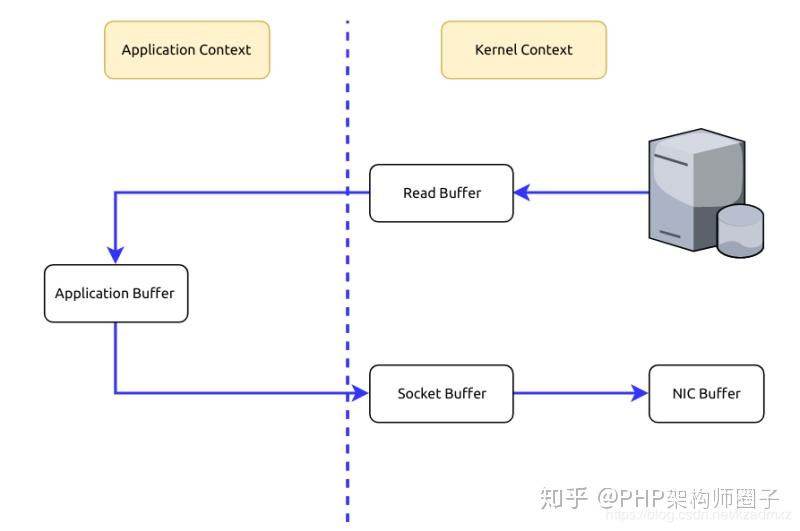
no zero cop
從圖中可以看到,資料在核心空間和使用者空間之間穿梭了兩次,那麼能否避免這個多餘的過程呢?當然可以,Kafka使用了零拷貝技術,也就是直接將資料從核心空間的讀緩衝區直接拷貝到核心空間的socket緩衝區,然後再寫入到NIC緩衝區,避免了在核心空間和使用者空間之間穿梭。
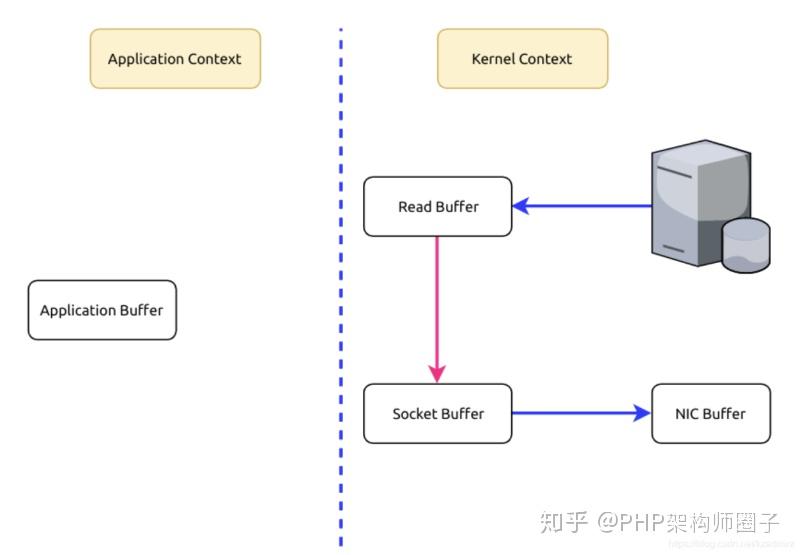
zero copy
可見,這裡的零拷貝並非指一次拷貝都沒有,而是避免了在核心空間和使用者空間之間的拷貝。如果真是一次拷貝都沒有,那麼資料發給客戶端就沒了不是?不過,光是省下了這一步就可以帶來效能上的極大提升。
四、分割槽分段+索引
Kafka的message是按topic分類儲存的,topic中的資料又是按照一個一個的partition即分割槽儲存到不同broker節點。每個partition對應了作業系統上的一個資料夾,partition實際上又是按照segment分段儲存的。這也非常符合分散式系統分割槽分桶的設計思想。
通過這種分割槽分段的設計,Kafka的message訊息實際上是分散式儲存在一個一個小的segment中的,每次檔案操作也是直接操作的segment。為了進一步的查詢優化,Kafka又預設為分段後的資料檔案建立了索引檔案,就是檔案系統上的.index檔案。這種分割槽分段+索引的設計,不僅提升了資料讀取的效率,同時也提高了資料操作的並行度。
五、批量讀寫
Kafka資料讀寫也是批量的而不是單條的。
除了利用底層的技術外,Kafka還在應用程式層面提供了一些手段來提升效能。最明顯的就是使用批次。在向Kafka寫入資料時,可以啟用批次寫入,這樣可以避免在網路上頻繁傳輸單個訊息帶來的延遲和頻寬開銷。假設網路頻寬為10MB/S,一次性傳輸10MB的訊息比傳輸1KB的訊息10000萬次顯然要快得多。
六、批量壓縮
在很多情況下,系統的瓶頸不是CPU或磁碟,而是網路IO,對於需要在廣域網上的資料中心之間傳送訊息的資料流水線尤其如此。進行資料壓縮會消耗少量的CPU資源,不過對於kafka而言,網路IO更應該需要考慮。
1>如果每個訊息都壓縮,但是壓縮率相對很低,所以Kafka使用了批量壓縮,即將多個訊息一起壓縮而不是單個訊息壓縮
2>Kafka允許使用遞迴的訊息集合,批量的訊息可以通過壓縮的形式傳輸並且在日誌中也可以保持壓縮格式,直到被消費者解壓縮
3>Kafka支援多種壓縮協議,包括Gzip和Snappy壓縮協議
Kafka速度的祕訣在於,它把所有的訊息都變成一個批量的檔案,並且進行合理的批量壓縮,減少網路IO損耗,通過mmap提高I/O速度,寫入資料的時候由於單個Partion是末尾新增所以速度最優;讀取資料的時候配合sendfile直接暴力輸出。
以上內容希望幫助到大家,很多PHPer在進階的時候總會遇到一些問題和瓶頸,業務程式碼寫多了沒有方向感,更多PHP大廠PDF面試文件,PHP進階架構視訊資料,PHP精彩好文免費獲取可以關注公眾號:PHP開源社群,或者訪問:
- Swoole協程與傳統fpm同步模式區別
- php-parser在Aop程式設計中的使用
- socket程式設計之認識常用協議
- mysql讀寫分離在專案實踐中的應用
- linux下檢視php-fpm是否開啟
- Nginx優化詳解
- PHP 怎麼快速讀取大檔案
- php redis實現訊息佇列
- PHP-FPM程序模型詳解
- 究竟什麼是RPC,你知道嘛?
- mysql 的讀寫鎖與併發控制
- 整理一下PHP的註釋標記
- redis快取穿透和快取失效的預防和解決
- php laravel依賴注入淺析
- php中Session的使用方法
- Kafka為什麼吞吐量大、速度快?
- redis 快取鎖的實現方法
- mysql讀寫分離在專案實踐中的應用
- PHP控制反轉(IOC)和依賴注入(DI)
- Mysql效能優化:為什麼要用覆蓋索引?