Pulsar vs Kafka?一文掌握高性能消息组件Pulsar基础知识
什么是Pulsar?
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代 云原生 分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐以及低延时的高可扩展流数据存储特性。
Pulsar 的关键特性
- Pulsar 的单个实例原生支持多个集群,可跨机房在集群间无缝地完成消息复制。
- 极低的发布延迟和端到端延迟。
- 可无缝扩展到超过 一百万 个 topic。
- 简单的客户端 API,支持 Java、Go、Python 和 C++。
- 支持多种 topic 订阅模式(独占订阅、共享订阅、故障转移订阅)。
- 通过 Apache BookKeeper 提供的持久化消息存储机制保证消息传递 。
- 由轻量级的 serverless 计算框架 Pulsar Functions 实现流原生的数据处理。
- 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
- 分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如S3、GCS)中。
Pulsar vs Kafka
下方链接为 Pulsar与 Kafka详细对比报告,可自行下载查看
http://streamnative.io/en/blog/tech/2020-07-08-pulsar-vs-kafka-part-1
http://streamnative.io/zh/blog/tech/2020-07-22-pulsar-vs-kafka-part-2
-
性能与可用性
基准测试(StreamNative)
数据来源
http://mp.weixin.qq.com/s/UZJTOEpzX8foUJv9XMJxOw
http://streamnative.io/en/blog/tech/2020-11-09-benchmark-pulsar-kafka-performance
http://streamnative.io/whitepaper/benchmark-pulsar-vs-kafka
- 吞吐量(Throughput)
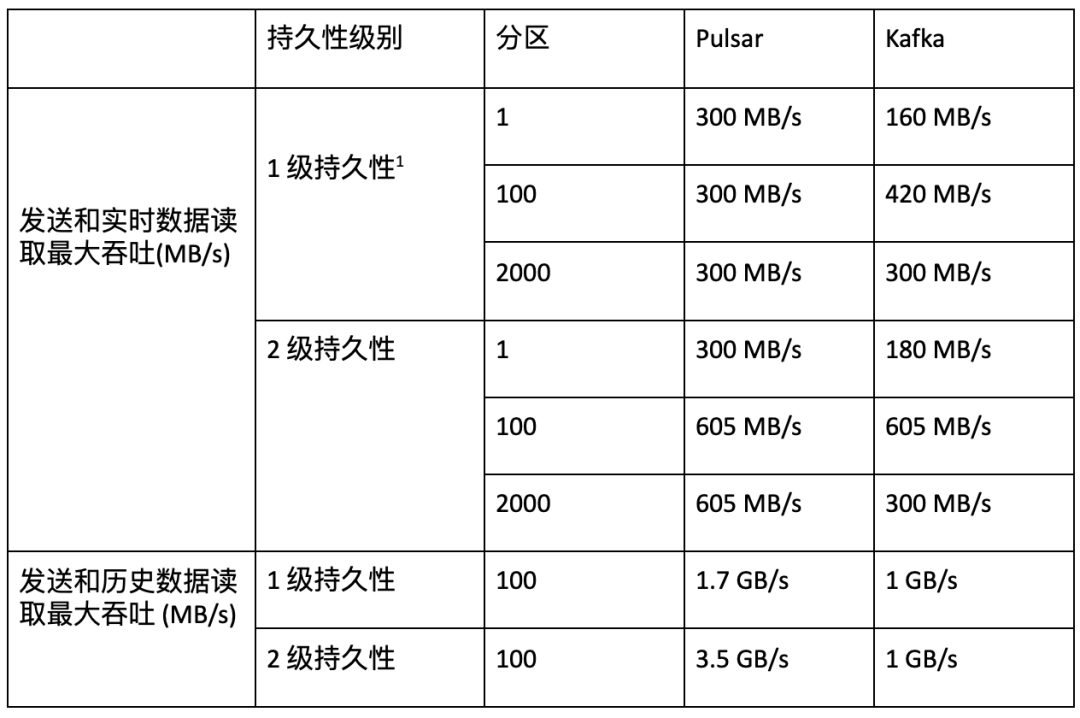
在与 Kafka 的持久性保证相同的情况下, Pulsar 可达到 605 MB /s 的发布和端到端 吞吐量 (与 Kafka 相同)以及 3.5 GB/s 的 catch-up read 吞吐量(比 Kafka 高 3.5 倍)。Pulsar 的吞吐量不会因分区数量的增加和持久性级别的改变而受到影响,而 Kafka 的吞吐量会因分区数量或持久性级别的改变而受到严重影响。
- 延迟性(Latency)
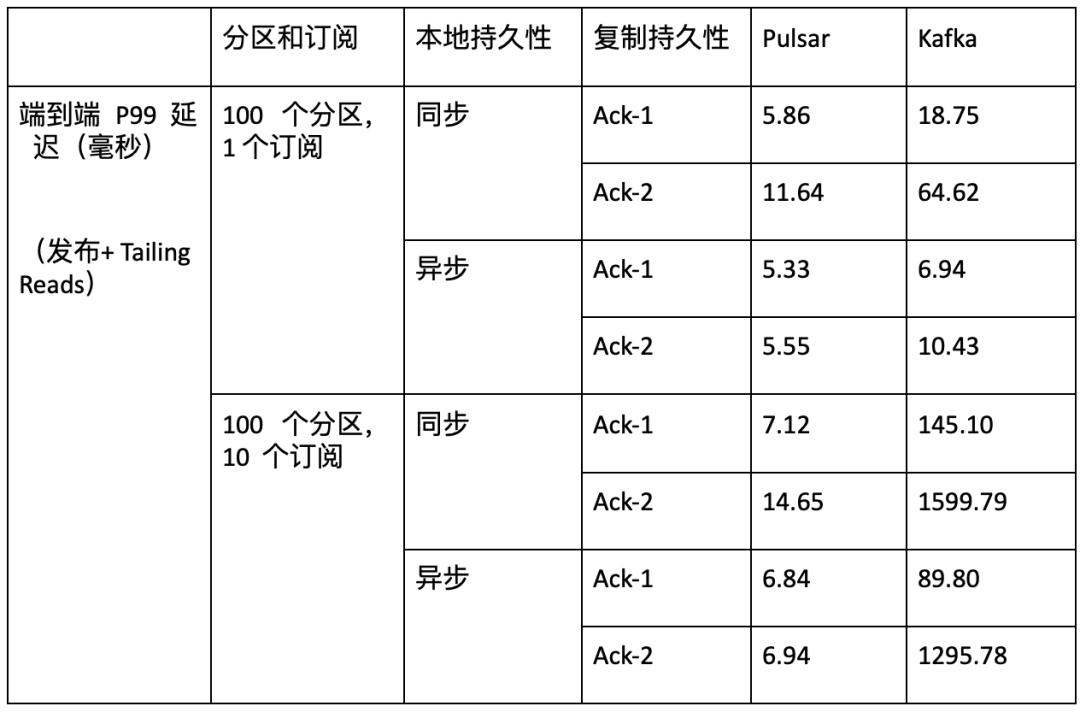
在不同的测试实例(包括不同订阅数量、不同主题数量和不同持久性保证)中,Pulsar 的延迟显著低于 Kafka。Pulsar P99 延迟在 5 到 15 毫秒之间。Kafka P99 延迟可能长达数秒,并且会因主题数量、订阅数量和不同持久性保证而受到巨大影响。
-
功能性
- 多语言客户端(C/C++、Python、Java、Go ...)
- 管理工具(Pulsar Manager vs Kafka Manager)
- 内置流处理Built-In Stream Processing(Pulsar Function vs Kafka Streams)
- Rich Integrations (Pulsar Connectors)
- Exactly-Once Processing
- 日志压缩
- 多租户(Pulsar)
- 安全管理(Pulsar)
架构设计
Pulsar 采用存储和计算分离的软件架构。 在消息领域,Pulsar 是第一个将存储计算分离 云原生 架构落地的 开源 项目 。由于在 Broker 层不存储任何数据,这种架构为用户带来了更高的可用性、更灵活的扩容和管理、避免数据的 reblance 和 catch-up。
在 Apache Pulsar 的分层架构中,服务层 Broker 和存储层 BookKeeper 的每个节点都是对等的。Broker 仅仅负责消息的服务支持,不存储数据。这为服务层和存储层提供了瞬时的节点扩展和无缝的失效恢复。
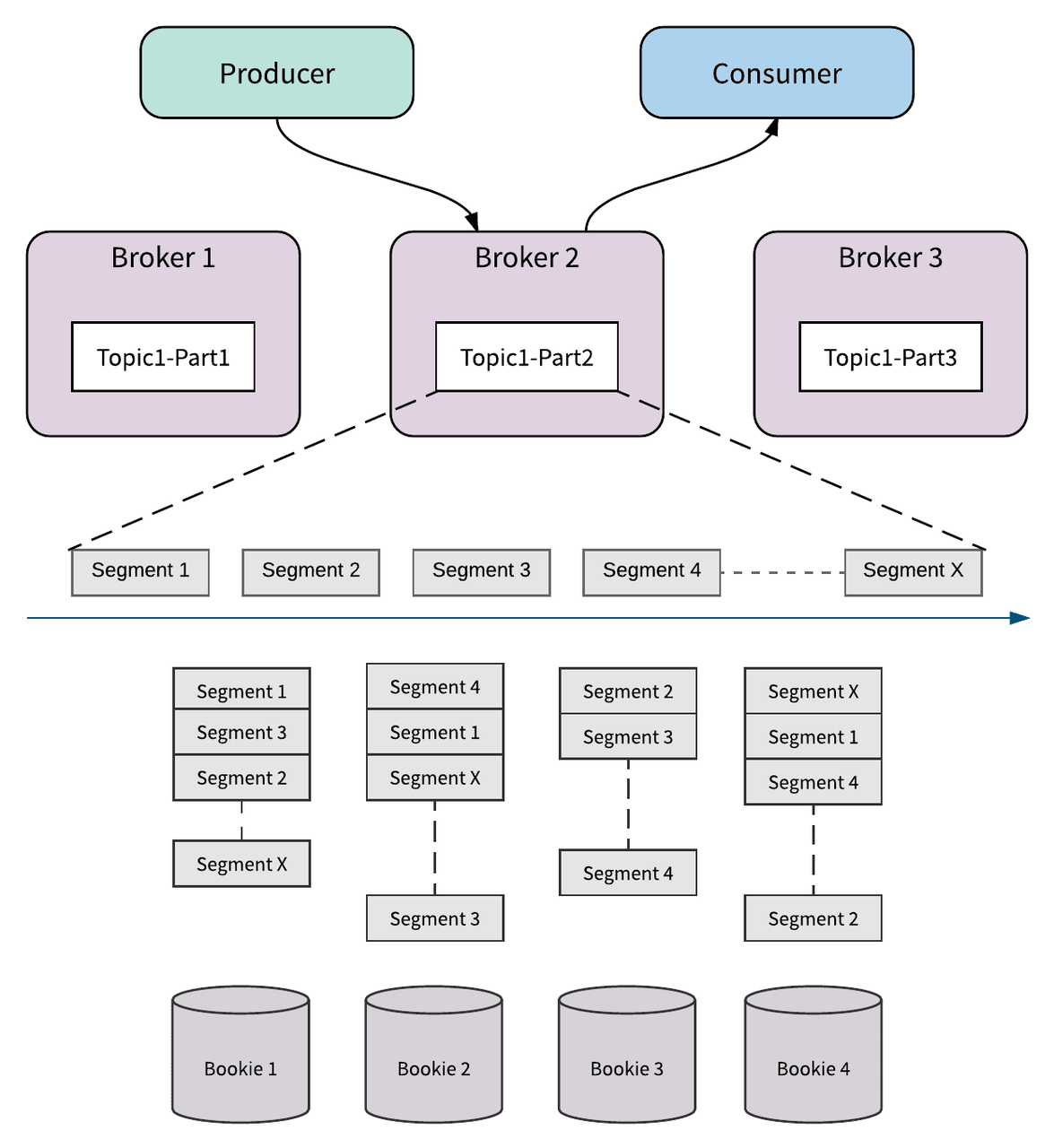
持久化存储(Persistent storage)
Pulsar 使用 BookKeeper 分布式日志存储数据库作为存储组件,在底层使用日志作为存储模型。
Pulsar 将所有未确认消息(即未处理消息)存储在 BookKeeper 中的多个“bookie”服务器上。
BookKeeper 通过 Quorum Vote 的方式来实现数据的一致性,跟 Master/Slave 模式不同,BookKeeper 中每个节点也是对等的,对一份数据会 并发 地同时写入指定数目的存储节点。
一个Topic实际上是一个ledgers流。Ledger本身就是一个日志。所以一系列的子日志(Ledgers)组成了一个父日志(Topic)。
Ledgers追加到一个Topic,条目(消息或者一组消息)追加到Ledgers。Ledger一旦关闭是不可变的。Ledger作为最小的删除单元,也就是说我们不能删除单个条目而是去删除整个Ledger。
Ledgers本身也被分解为多个Fragment。Fragment是BookKeeper集群中最小的分布单元。
每个Ledger(由一个或多个Fragment组成)可以跨多个BookKeeper节点(Bookies)进行复制,以实现数据容灾和提升读取性能。每个Fragment都在一组不同的Bookies中复制(存在足够的Bookies)。
conf/bookkeeper.conf
#############################################################################
## Server parameters
#############################################################################
# Directories BookKeeper outputs its write ahead log.
# Could define multi directories to store write head logs, separated by ','.
journalDirectories=/data/appData/pulsar/bookkeeper/journal
#############################################################################
## Ledger storage settings
#############################################################################
# Directory Bookkeeper outputs ledger snapshots
# could define multi directories to store snapshots, separated by ','
ledgerDirectories=/data/appData/pulsar/bookkeeper/ledgers
conf/broker.conf
### --- Managed Ledger --- ###
# Number of bookies to use when creating a ledger
managedLedgerDefaultEnsembleSize=2
# Number of copies to store for each message
managedLedgerDefaultWriteQuorum=2
# Number of guaranteed copies (acks to wait before write is complete)
managedLedgerDefaultAckQuorum=2
元数据存储(Metadata storage)
Pulsar 和BookKeeper都使用Apache Zookeeper 来存储元数据和监控节点健康状况。
$ $PULSAR_HOME/bin/pulsar zookeeper-shell
> ls /
[admin, bookies, counters, ledgers, loadbalance, managed-ledgers, namespace, pulsar, schemas, stream, zookeeper]
更多福利
云智慧已开源集轻量级、聚合型、智能运维为一体的综合运维管理平台OMP(Operation Management Platform) ,具备 纳管、部署、监控、巡检、自愈、备份、恢复 等功能,可为用户提供便捷的运维能力和业务管理,在提高运维人员等工作效率的同时,极大提升了业务的连续性和安全性。点击下方地址链接,欢迎大家给OMP点赞送star,了解更多相关内容~
GitHub地址: http://github.com/CloudWise-OpenSource/OMP
Gitee地址:http://gitee.com/CloudWise/OMP
微信扫描识别下方二维码,备注【OMP】加入AIOps社区运维管理平台OMP开发者交流群,与更多行业大佬一起交流学习~

- FlyFish2.0版本后端源码学习笔记
- AIOps场景下,指标预测算法基础知识全面总结
- 根因分析思路与方法看这一篇就够了!
- 智能运维应用之道,告别企业数字化转型危机
- 多场景下时序序列分类算法基础知识全面总结
- 多场景下时序序列分类算法基础知识全面总结
- 告警风暴来袭,智能运维应如何化解?
- 智能运维 VS 传统运维|AIOps服务管理解决方案全面梳理
- 智能运维(AIOps)实践|日志语义异常检测全面解读
- 数字化时代,企业运维面临现状及挑战分析解读
- 大咖实战|Kubernetes自动伸缩实现指南分享
- 10分钟学会如何在智能运维中进行日志分析
- 深度学习—人工智能的第三次热潮
- 结合机器学习的多指标异常检测方法总结分析
- Android C/C 层hook和java层hook原理以及比较
- 分布迁移下的深度学习时间序列异常检测方法探究
- 快速了解日志概貌,详细解读13种日志模式解析算法
- 分布迁移下的深度学习时间序列异常检测方法探究
- 算法实践|如何根据各类指标数据选择合适算法?
- 如何在智能运维中进行指标异常检测与分类?