机器学习算法整理(三)
逻辑回归
什么是逻辑回归(Logistic Regression)
逻辑回归是解决分类问题的,那回归问题怎么解决分类问题呢?将样本的特征和样本发生的概率联系起来,概率是一个数。
对于机器学习的本质就是![]() ,进来一个x,经过f(x)的运算,就得到一个预测值
,进来一个x,经过f(x)的运算,就得到一个预测值![]() ,对于之前无论是线性回归也好,多项式回归也好,看我们要预测的是什么,如果我们要预测的是房价,那么
,对于之前无论是线性回归也好,多项式回归也好,看我们要预测的是什么,如果我们要预测的是房价,那么![]() 的值就是房价。如果我们要预测成绩,那么
的值就是房价。如果我们要预测成绩,那么![]() 的值就是成绩。但是在逻辑回归中,这个
的值就是成绩。但是在逻辑回归中,这个![]() 的值是一个概率值。
的值是一个概率值。
![]() ,进来一个x,经过f(x)的运算,会得到一个概率值
,进来一个x,经过f(x)的运算,会得到一个概率值![]() 。之后我们根据这个概率值
。之后我们根据这个概率值![]() 来进行分类
来进行分类
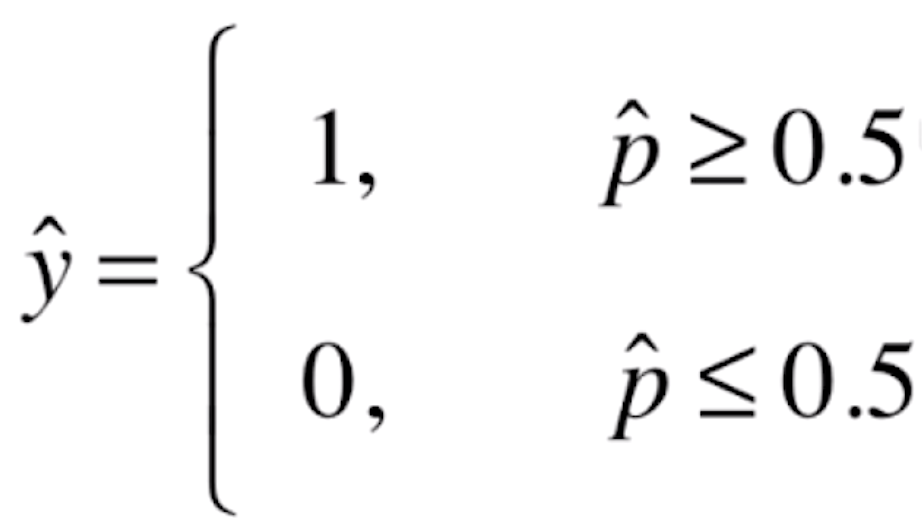
如果![]() 有50%以上的概率,我们就让
有50%以上的概率,我们就让![]() 的值为1;如果
的值为1;如果![]() 在50%以下概率的话,我们就让
在50%以下概率的话,我们就让![]() 的值为0。这里的1和0在实际的场景中可能代表不同的意思,比如说1代表恶性的肿瘤患者,0代表良性的肿瘤患者;或者说1代表银行发给某人信用卡有一定的风险,0代表没有风险等等。
的值为0。这里的1和0在实际的场景中可能代表不同的意思,比如说1代表恶性的肿瘤患者,0代表良性的肿瘤患者;或者说1代表银行发给某人信用卡有一定的风险,0代表没有风险等等。
逻辑回归既可以看作是回归算法,也可以看作是分类算法。如果我们不进行最后的一步根据![]() 的值进行分类的操作,那么它就是一个回归算法。我们计算的是根据样本的特征来拟合计算出一个事件发生的概率。比如给我一个病人的信息,我计算出他患有恶性肿瘤的概率。给我一个客户的信息,我计算出发给他信用卡产生风险的概率。我们根据这个概率进一步就可以进行分类。不过通常我们使用逻辑回归还是当作分类算法用,只可以解决二分类问题。如果对于多分类问题,逻辑回归本身是不支持的。当然我们可以使用一些其他的技巧进行改进,使得我们用逻辑回归的方法,也可以解决多分类的问题。但是对于KNN算法来说,它天生就可以支持多分类的问题。
的值进行分类的操作,那么它就是一个回归算法。我们计算的是根据样本的特征来拟合计算出一个事件发生的概率。比如给我一个病人的信息,我计算出他患有恶性肿瘤的概率。给我一个客户的信息,我计算出发给他信用卡产生风险的概率。我们根据这个概率进一步就可以进行分类。不过通常我们使用逻辑回归还是当作分类算法用,只可以解决二分类问题。如果对于多分类问题,逻辑回归本身是不支持的。当然我们可以使用一些其他的技巧进行改进,使得我们用逻辑回归的方法,也可以解决多分类的问题。但是对于KNN算法来说,它天生就可以支持多分类的问题。
逻辑回归使用一种什么方式可以得到一个事件概率的值?对于线性回归来说, 它的
它的![]() 值域是(-∞,+∞)的。对于线性回归来说它可以求得一个任意的值。但是对于概率来说,它的值域只能是[0,1],所以我们直接使用线性回归的方式,没办法在这个值域内。为此,我们的解决方案就是将线性回归的预测值,放入一个函数内
值域是(-∞,+∞)的。对于线性回归来说它可以求得一个任意的值。但是对于概率来说,它的值域只能是[0,1],所以我们直接使用线性回归的方式,没办法在这个值域内。为此,我们的解决方案就是将线性回归的预测值,放入一个函数内![]() ,使得其值域在[0,1]之间,这样就获得了我们需要的概率
,使得其值域在[0,1]之间,这样就获得了我们需要的概率![]() 。
。
那么我们的![]() 函数是什么呢?
函数是什么呢?
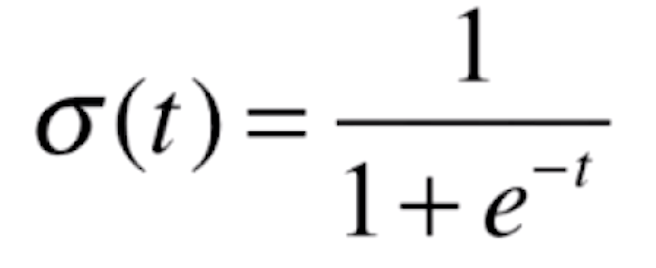
现在我们用代码来看一下这个函数的图像
import numpy as np import matplotlib.pyplot as plt if __name__ == "__main__": def sigmoid(t): return 1 / (1 + np.exp(-t)) x = np.linspace(-10, 10, 500) y = sigmoid(x) plt.plot(x, y) plt.show()
运行结果
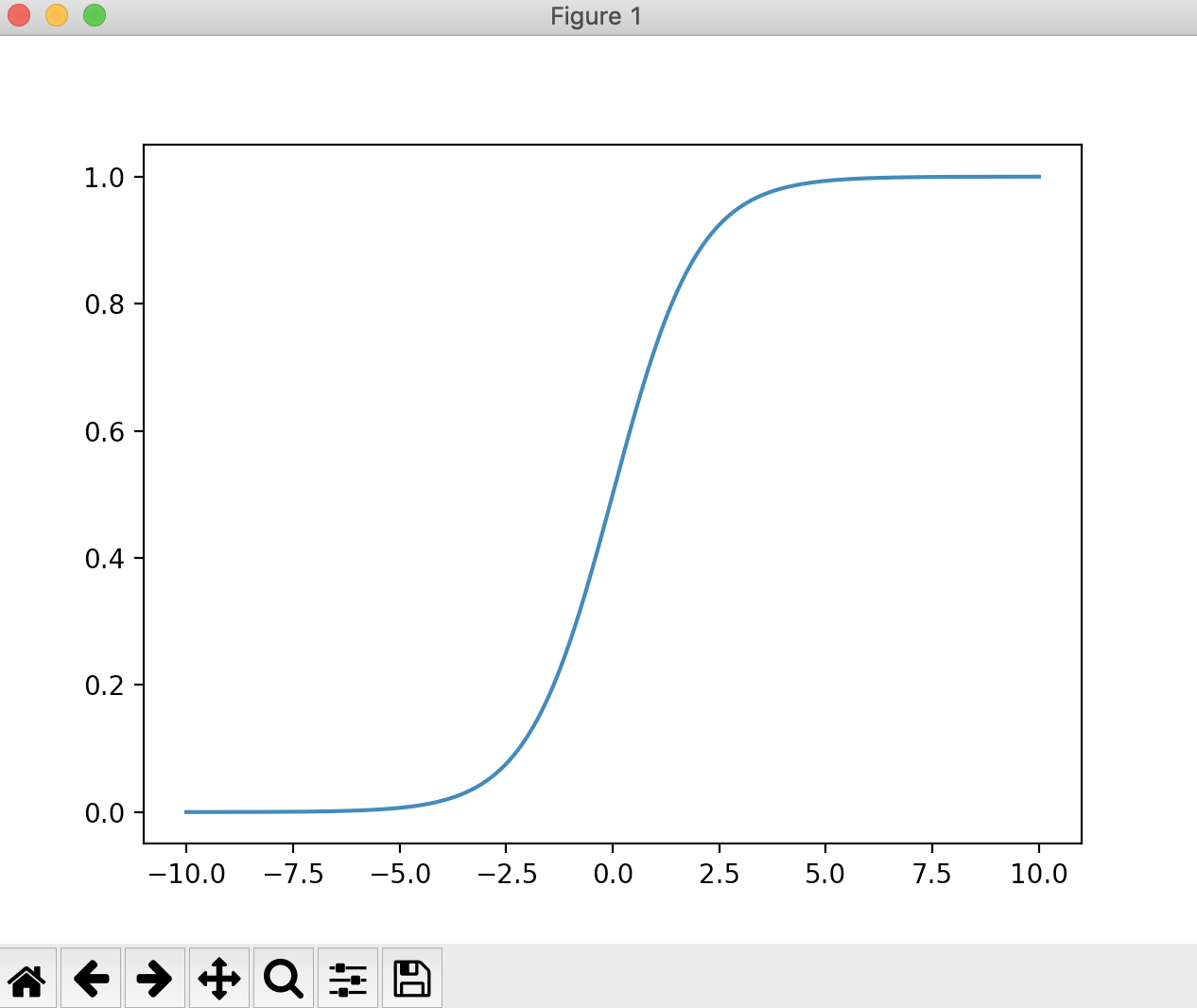
根据这根曲线,我们可以看到它的最左端趋近于0,但是达不到0,最右端趋近于1,但是达不到1。说明这根曲线的值域是(0,1),这是因为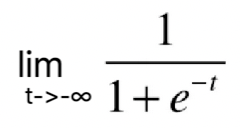 =0,
=0,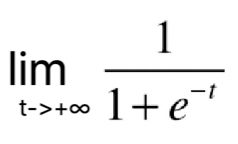 =1。当我们画上纵轴
=1。当我们画上纵轴
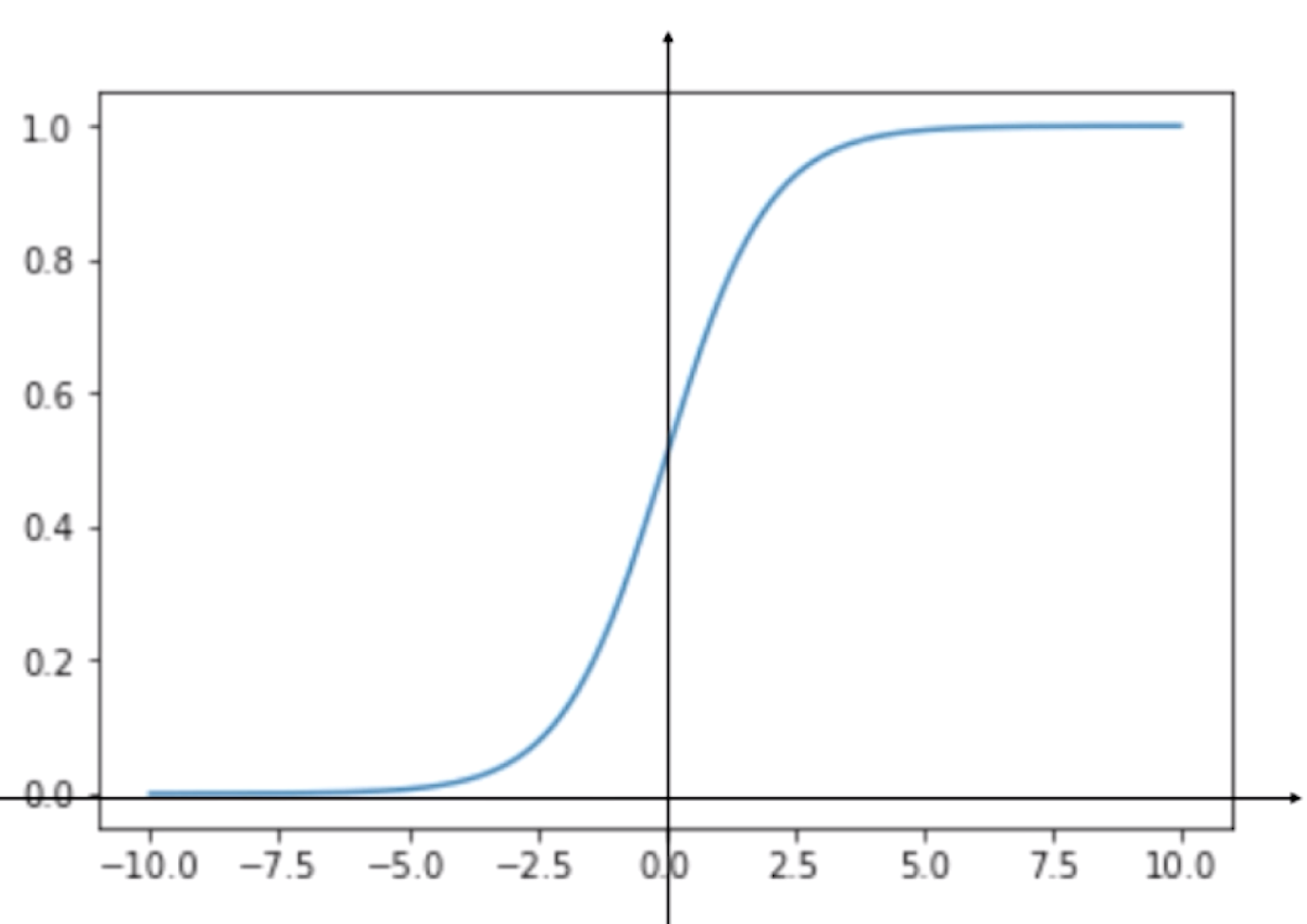
我们可以看到,当t>0时,p>0.5;t<0时,p<0.5。
那么将我们线性回归的预测值代入该函数后就变成了
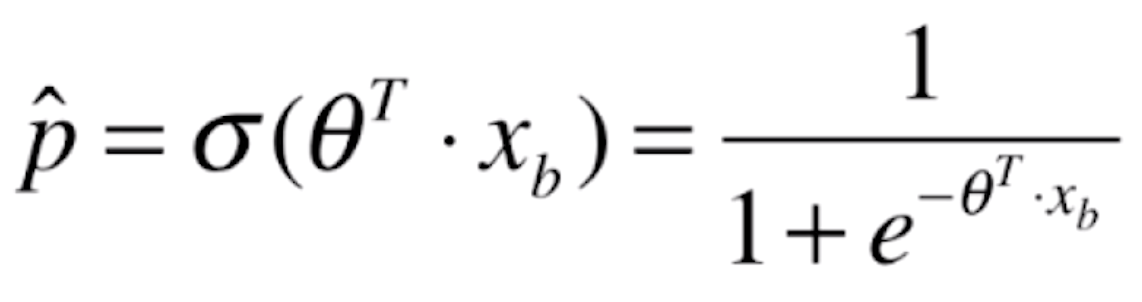 ,
,
现在我们已经知道了逻辑回归的基本原理,现在的问题就是:对于给定的样本数据集X,y,我们如何找到参数θ,使得用这样的方式,可以最大程度获得样本数据集X,对应分类出y?