詳解分析 | ViT如何在醫療影象領域替代CNNs?



1簡介
在自動醫學影象診斷的領域中卷積神經網路(CNN)方法已經統治了將近十年之久。最近,vision transformers(ViTs)作為CNN的一個有競爭力的替代方法出現了,它具有差不多的效能,同時還具有一些有趣的特性,同時也已經被證明對醫學成像任務有益。
在這項工作中,作者探討了是時候用基於transformer的模型了?還是應該繼續使用CNN,還是可以簡單地切換到transformer?
如果是,那麼切換到vit進行醫學影像診斷有哪些優點和缺點?作者在3種主流醫學影象資料集上進行了一系列實驗來考慮這些問題。
研究結果表明,雖然CNN在從頭開始訓練時表現更好,但在ImageNet上預訓練時,使用預設超引數的vision transformer與CNN相當,而在使用自監督預訓練時vision transformer則優於CNN。
2介紹
對於vision transformer來說,注意力機制提供了幾個關鍵的優勢:
-
它捕獲了long-range relationships; -
它具有通過動態進行自適應建模的能力; -
它提供了一種內建的顯著性,可以洞察模型關注於的是什麼。
然而,有證據表明,vision transformer需要非常大的資料集才能超過CNN,ViT的效能只有在谷歌私有影象資料集JFT-300M進行預訓練才能夠得到體現。這個問題在醫學成像領域尤其嚴重,因為該領域的資料集更小,往往伴有不太可靠的標籤。
與ViT一樣,當資料匱乏時,CNN的效能會更差。標準的解決方案是使用遷移學習:通常,模型在ImageNet等較大的資料集上進行預訓練,然後使用較小的專門資料集對特定任務進行微調。
在醫學領域,在ImageNet進行預訓練的模型在最終表現和減少的訓練時間方面都優於從零開始訓練的模型。
自監督是一種處理未標記資料的學習方法,近年來受到了廣泛關注。已有研究表明,在進行微調之前,在目標域進行自監督預訓練可以提高CNN的效能。同時從ImageNet初始化有助於自監督CNN收斂更快,通常也具有更好的預測效能。
這些處理醫學影象領域資料匱乏的技術已被證明對CNN有效,但目前尚不清楚vision transformer是否同樣受益。一些研究表明,使用ImageNet進行醫學影象分析的預訓練CNN並不依賴於特徵重用,而是由於更好的初始化和權重縮放。那麼vision transformer是否能從這些技術中獲益?如果可以,就沒有什麼能阻止vit成為醫學影象的主導架構。
在這項工作中,作者探索了vit是否可以替代CNNs,同時考慮到易用性、資料集限制以及計算限制,作者著眼於“即插即用”解決方案。為此,作者在3個主流的公開資料集上進行了實驗。通過這些實驗發現:
-
在資料有限時,CNNs與ViTs在ImageNet上預訓練的效能差不多; -
遷移學習有利於ViTs; -
當使用自監督預訓練之後再用有監督的微調時,ViTs比CNNs表現更好。
這些發現表明,醫學影象分析可以從CNN無縫過渡到ViTs,同時獲得更好的可解釋性。
3本文方法
作者研究的主題是,ViTs是否可以直接替代CNNs用於醫療診斷任務。為此,作者進行了一系列實驗,在類似條件下比較ViTs和CNNs,保持超引數調優到最小。為了確保比較的公平性和可解釋性,作者選擇ResNet50作為CNN模型,使用 token作為ViT的DEIT-S。之所以選擇這些模型,是因為它們在引數數量、記憶體需求和計算方面具有可比性。
如上所述,當資料不夠豐富時,CNNs依賴於初始化策略來提高效能,醫學影象就是如此。標準的方法是使用遷移學習(用ImageNet上預訓練的權值初始化模型),並在目標域上進行微調。
因此,作者考慮3種初始化策略:
-
隨機初始化權值 -
使用ImageNet預訓練權值進行遷移學習 -
初始化後對目標資料集進行自監督預訓練學習
資料增強策略:
-
normalization; -
color jitter: -
brightness -
contrast -
saturation -
hue -
horizontal flip -
vertical flip -
random resized crops
資料集:
-
APTOS 2019
在這個資料集中,任務是將糖尿病視網膜病變影象分類為疾病嚴重程度的5類。APTOS 2019包含3662張高解析度視網膜影象。
-
ISIC 2019
這裡的任務是將25333張面板鏡影象在9種不同的面板病變診斷類別中進行分類。
-
CBIS-DDSM
該資料集包含10239張乳房x線照片,任務是檢測乳房x線照片中腫塊的存在。
資料集被分為train/test/valid(80/10/10),除了APTOS,由於其規模小,APTOS被分為70/15/15。所有監督訓練都使用ADAM優化器,基本學習率為 ,warm-up週期為1000次迭代。當驗證指標達到飽和時,學習率會下降10倍,直到達到最終值。重複每個實驗5次,並選擇每次執行中驗證分數最高的checkpoint。
4實驗
4.1 隨機初始化Transformer模型是否有效?
將DEIT-S與具有隨機初始化權值(Kaiming初始化)的ResNet50進行比較。在這些實驗中,通過網格搜尋將基礎學習率設定為0.0003。
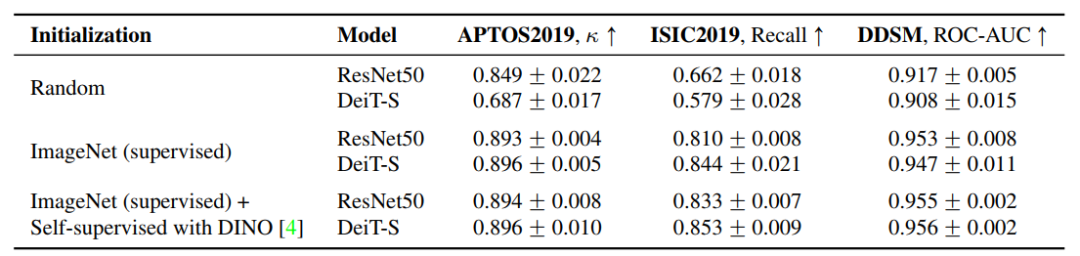
表1的結果表明,在這種設定下,CNNs在各方面都大大優於ViTs。
這些結果與之前在自然影象領域的觀察結果一致,在有限的資料上訓練CNNs優於ViTs,這一趨勢歸因於ViT缺乏歸納偏差。由於大多數醫學影像資料集大小適中,隨機初始化的ViTs的用處似乎有限。
4.2 ImageNet上預訓練ViTs是否適用於醫學影象領域?
在醫學影象資料集中,隨機初始化在實際應用中很少使用。標準步驟是使用ImageNet預訓練網路,然後對來自目標域的資料進行微調。
在這裡,作者也研究了這種方法是否可以有效地應用於ViTs。為了測試這一點,作者用在ImageNet上預訓練過權重初始化所有模型。然後進行微調。表1中的結果表明,CNNs和ViTs都從ImageNet初始化中得到了顯著提升。事實上,ViTs受益更多,表現與CNN相當。
這表明,當使用ImageNet初始化時,可以用普通的ViTs替換CNNs,而不會影響使用中等規模訓練資料的醫學成像任務的效能。
4.3 ViT是否能從醫療影象領域的自監督中獲益?
表1中結果顯示,ViTs和CNNs在自監督的預訓練中表現得更好。在這種情況下,ViTs的表現優於CNNs,儘管差距很小。對自然影象的研究表明ViTs和CNNs將隨著更多的資料增長。
5討論
作者比較了3種初始化策略下的醫學影象任務cnn和vit的效能。實驗結果證實了之前的發現,並提供了新的見解。
在醫學影象中,正如之前在自然影象領域所說的那樣,作者發現,在低資料模式下從零開始訓練時,cnn優於vit。這一趨勢在所有資料集上都是一致的,並且很好地符合“Transformer缺乏歸納偏差”的論點。
令人驚訝的是,當使用監督ImageNet預訓練權重初始化時,CNN和ViT效能之間的差距在醫療任務中消失了。在cnn上進行ImageNet預訓練的好處是眾所周知的,但出乎意料的是,ViTs的受益也如此之大。這表明,可以通過與任務更密切相關的其他領域的遷移學習獲得進一步的改進,cnn的情況就是如此。
作者研究了自監督預訓練對醫學影象域的影響。研究結果表明,vit和cnn有微小但一致的改善。而最佳的整體效能是使用自監督+ViTs獲得的。
總結髮現,對於醫學影象領域:
-
如果從零開始訓練,那麼在低資料下,vit比cnn更糟糕; -
遷移學習在cnn和vit之間架起了橋樑;效能是相似的; -
最好的表現是通過自監督預訓練+微調獲得的,其中ViTs比CNNs有小的優勢。
6可解釋性
在醫學影象任務中,vit似乎可以取代cnn,還有其他選擇vit而不是cnn的原因嗎?
我們應該考慮視覺化transformer attention maps的額外好處。transformer的自注意機制內建了一個attention maps,它提供了模型如何做出決策的新方式。
cnn自然不適合把自己的突出形象表現出來。流行的CNN可解釋性方法,如類啟用對映(CAM)和grada-CAM,由於池化層的存在,提供了粗糙的視覺化。與CNN有限的接受域相比,transformer token提供了更精細的注意力影象,而自注意對映明確地模擬了影象中每個區域之間的互動。雖然可解釋性的質量差異還有待量化,但許多人已經注意到transformer的注意力在可解釋性方面所帶來的質量改進。
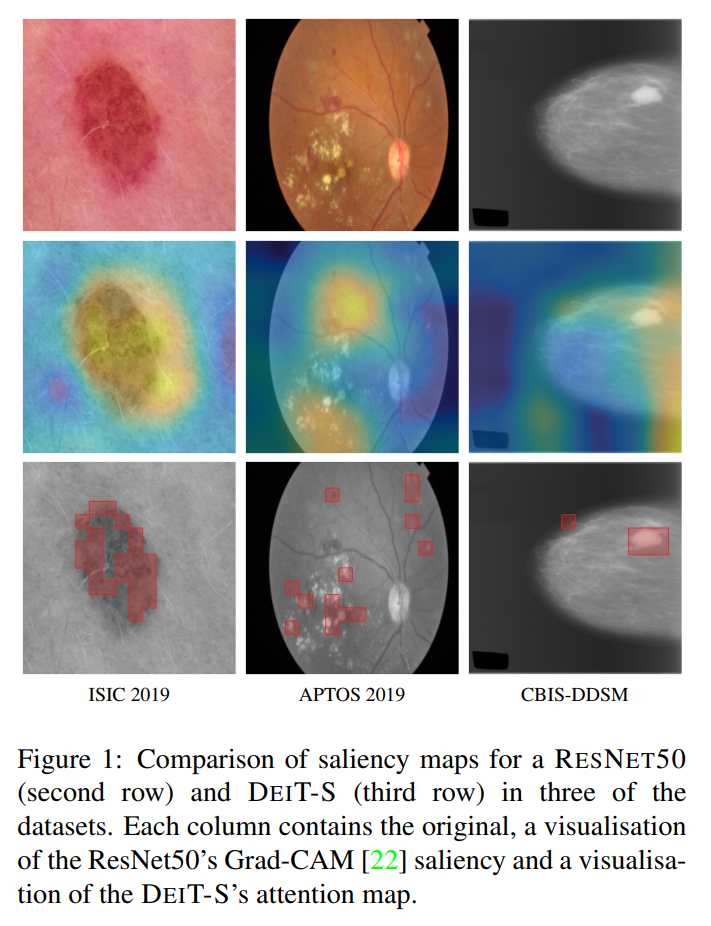
圖1中展示了來自每個資料集的示例,以及ResNet-50的grade-cam視覺化和 DEIT-S CLS token的前50%自注意。注意ViTs的自注意如何提供一個清晰的、區域性的注意力圖,例如ISIC的面板病變邊界的注意力,APTOS的出血和滲出物的注意力,以及CBIS-DDSM的乳腺緻密區域的注意力。這種關注粒度很難通過cnn實現。
7參考
[1].Is it Time to Replace CNNs with Transformers for Medical Images?
8知識星球
各位小夥伴們,【集智書童】也上線啦!!!主要涉獵的內容包括:
-
演算法改進 -
優秀論文推薦 -
演算法復現 -
AI演算法部署(TensorRT、OpenCV、ONNX、OpenVINO等內容)
部分內容如下截圖:



下面是送出了40張新人優惠券,掃描下方二維碼即可加入星球:

9推薦閱讀

詳細解讀 | 如何讓你的DETR目標檢測模型快速收斂
Mobile-Former | MobileNet+Transformer輕量化模型(精度速度秒殺MobileNet)
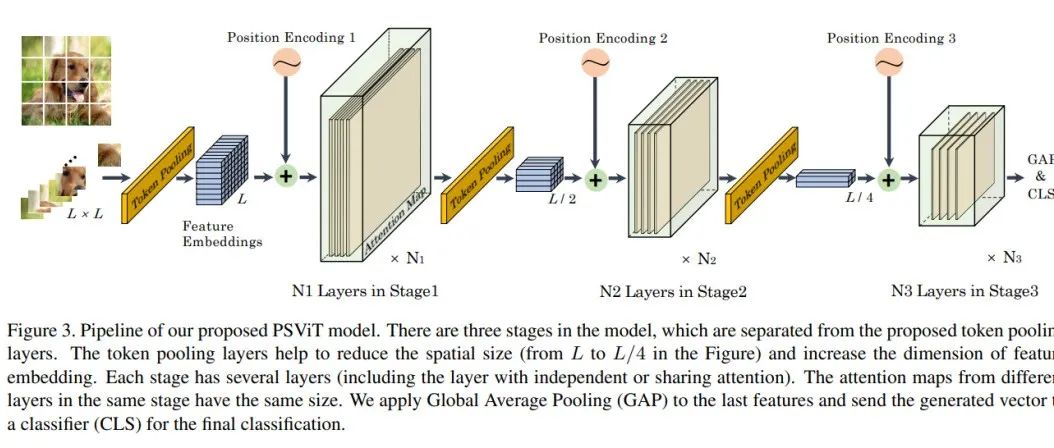
牛津大學提出PSViT | Token池化+Attention Sharing讓Transformer模型不在冗餘!!!
長按掃描下方二維碼新增小助手。
可以一起討論遇到的問題

宣告:轉載請說明出處
掃描下方二維碼關注【集智書童】公眾號,獲取更多實踐專案原始碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!

本文分享自微信公眾號 - AI人工智慧初學者(ChaucerG)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- 部署教程 | ResNet原理 PyTorch復現 ONNX TensorRT int8量化部署
- 超級解密 | 無人駕駛是如何煉成的
- 詳解分析 | ViT如何在醫療影象領域替代CNNs?
- 學完這些乾貨,想不變強都難!
- 詳細解讀GraphFPN | 如何用圖模型提升目標檢測模型效能?
- 華為瘋狂擴招1000人,招聘要求讓人窒息!
- 簡單有效 | Transformer通過剪枝降低FLOPs以走向部署(文末獲取論文)
- 會"看"也要會"聽",NVIDIA 第四屆 Sky Hackathon 註冊開啟,更有挑戰的比賽主題,誠邀您組團挑戰!
- 最佳Backbone | RepVGG重鎮VGG雄風,各大任務獨佔鰲頭(附原始碼和論文下載)
- 泛化神器 | BGN全方位解決因Batch Size大小問題所帶來的訓練不穩定(附論文下載)
- 漲點明顯 | 港中文等提出SplitNet結合Co-Training提升Backbone效能(附原始碼和論文)
- NeurIPS 2020 | 伯克利新工作: 基於動態關係推理的多智慧體軌跡預測問題
- 【訓練Trick】讓你在一張卡上訓練1000萬個id人臉資料整合為可能(附開原始碼和論文連結)
- 【送書活動】人臉核心演算法大集結