(方案)高併發下如何避免髒數據

1. 什麼是髒數據
髒數據是指從目標中取出的數據已經過期、錯誤或沒意義,當出現髒數據時,一般會涉及髒讀和髒寫兩種操作。
- 髒讀:讀取出來的髒數據稱為髒讀;
- 髒寫:寫入進去的髒數據稱為髒寫。
2.應用層面如何避免髒數據
- 髒讀:獲取經常變化的數據,高併發期間緩存數據與數據庫數據不一致問題:-- >解決方案: 利用數據庫鎖、Redis分佈式鎖和Zookeeper分佈式鎖來解決,參考http://my.oschina.net/pengchanghua/blog/3275206
- 髒寫:就是兩個事務沒提交的狀況下,都修改同一條數據,結果一個事務回滾了,把另外一個事務修改的值也撤銷了,所謂髒寫就是兩個事務沒提交狀態下修改同一個值。 --->解決方案:利用Redis緩存的IncrBy、incr函數,由於其具有原子性,在寫入過程中不會產生髒數據。 (注意:redis後台服務是串行的單線程執行,不存在併發,即多線程調用Incr/incrby方法,在redis服務器上仍然是串行的單線程執行,不存在併發,所以這倆命令都是原子自增、線程安全的。)
3.數據庫層面如何避免髒數據
如果多個事務要是對數據庫中的同一條數據同時進行更新或者查詢,此時會產生哪些問題呢?這裏實際上會涉及到髒寫、髒讀、不可重複讀、幻讀四種問題。
3.1 髒寫
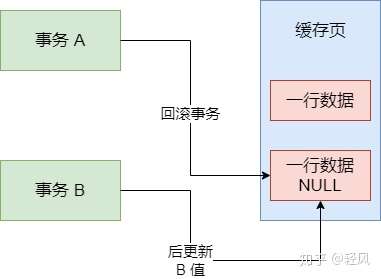
當兩個事務同時嘗試去更新某一條數據記錄時,就肯定會存在一個先一個後。而當事務A更新時,事務A還沒提交,事務B就也過來進行更新,覆蓋了事務A提交的更新數據,這就是髒寫。
3.2 髒讀
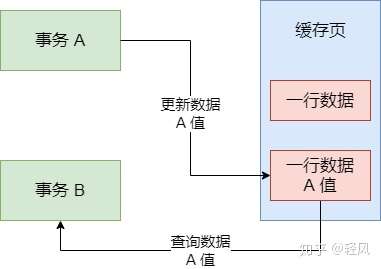
如果一個事務A向數據庫寫了數據,但事務還沒提交或終止,另一個事務B就看到了事務A寫進數據庫的數據,這就是髒讀。
3.3 不可重複讀
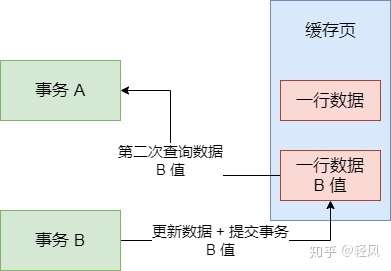
如果你期望的是可重複讀,但是數據庫表現的是不可重複讀,讓你事務 A 執行期間多次查到的值都不一樣,都的問題是別的提交過的事務修改過的,那麼此時你就可以認為,數據庫有問題,這個問題就是「不可重複讀」
3.4 幻讀
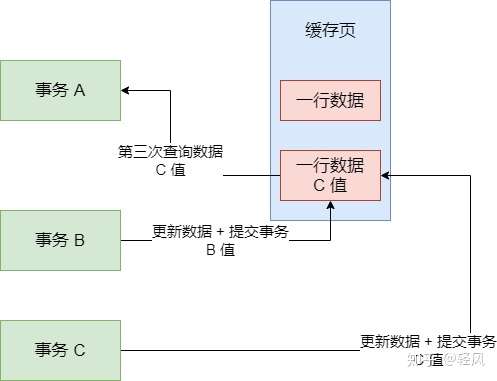
簡單來説,你一個事務 A,先發送一條 SQL 語句,裏面有一個條件,要查詢一批數據出來,如SELECT * FROM table WHERE id > 10。然後呢,它一開始查詢出來了 10 條數據。接着這個時候,別的事務 B往表裏插了幾條數據,而且事務 B 還提交了,此時多了幾行數據。
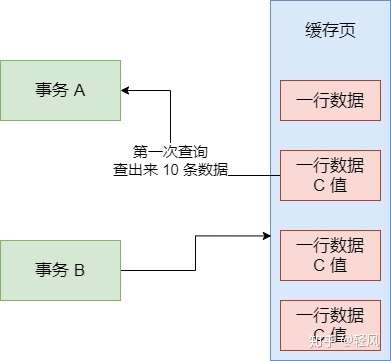
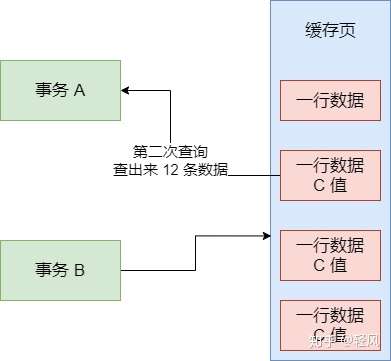
要解決上述問題,通過數據庫的隔離級別進行解決,如MYSQL。
Read Uncommitted(讀取未提交內容)
在該隔離級別,所有事務都可以看到其他未提交事務的執行結果。本隔離級別很少用於實際應用,因為它的性能也不比其他級別好多少。讀取未提交的數據,也被稱之為髒讀(Dirty Read)。
Read Committed(讀取已提交內容)
這是大多數數據庫系統的默認隔離級別(但不是MySQL默認的,ORACLE和 SQL Server 默認為該級別)。它滿足了隔離的簡單定義:一個事務只能看見已經提交事務所做的改變。這種隔離級別 也支持所謂的不可重複讀(Nonrepeatable Read),因為同一事務的其他實例在該實例處理其間可能會有新的commit,所以同一select可能返回不同結果。
Repeatable Read(可重讀)
這是MySQL的默認事務隔離級別,它確保同一事務的多個實例在併發讀取數據時,會看到同樣的數據行。不過理論上,這會導致另一個棘手的問題:幻讀 (Phantom Read)。簡單的説,幻讀指當用户讀取某一範圍的數據行時,另一個事務又在該範圍內插入了新行,當用户再讀取該範圍的數據行時,會發現有新的“幻影” 行。InnoDB和Falcon存儲引擎通過多版本併發控制(MVCC,Multiversion Concurrency Control)機制解決了該問題。
存在的問題: 條件列未命中索引會鎖表, 現死鎖的機率 比在讀取已提交RC多得多,而在RC隔離級別下,只鎖行。
所以針對互聯網高併發應用,如果用MYSQL也會將其默認隔離級別改成讀已提交RC .
http://my.oschina.net/pengchanghua/blog/4701283
Serializable(可串行化)
這是最高的隔離級別,它通過強制事務排序,使之不可能相互衝突,從而解決幻讀問題。簡言之,它是在每個讀的數據行上加上共享鎖。在這個級別,可能導致大量的超時現象和鎖競爭。
在MySQL中,實現了這四種隔離級別,分別有可能產生問題如下所示:
