大根堆與小根堆的理解,如何手寫一個堆,以及什麼時候用自己手寫的堆,什麼時候用語言提供堆的api,(二者的區別)
大根堆與小根堆的理解,如何手寫一個堆,以及什麼時候用自己手寫的堆,什麼時候用語言提供堆的api,(二者的區別)
定義
Heap是一種資料結構具有以下的特點:
1)完全二叉樹;
2)heap中儲存的值是偏序;
Min-heap: 父節點的值小於或等於子節點的值;
Max-heap: 父節點的值大於或等於子節點的值;
用通俗語言來說,大根堆就是每個最大的數字在每個子樹的最上方,及大根堆pop值為最大值,小根堆反之

堆的儲存
堆的儲存一般由陣列表示,由於堆的實質就是完全二叉樹,所以對於每個i來說(從0開始),左右孩子分別為2i+1,2i+2,父節點為(i-1)/2,
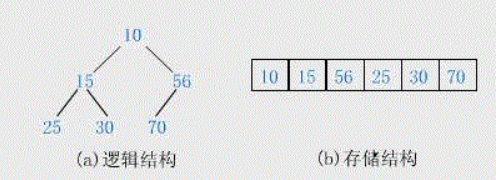
堆的核心操作(手寫與系統均有)
heapinsert與heapify
1.heapinsert:加入一個節點,通過上升的方式,依次進行比較,(上升操作),時間複雜度為o(logN)因為樹的深度為logN

swap為交換操作
private void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
2.heapify:彈出根結點之後的,將剩餘變成堆的操作(下沉操作),因為彈出根結點後,會將陣列最後面的數字頂替為根結點,所以只需將該結點進行下沉操作即可,時間複雜度為o(logN)樹的深度為logN

swap為交換操作
/**
*
* @param arr 陣列
* @param index 索引
* @param heapSize 堆大小
*/
private void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1;
while (left < heapSize) {
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
堆排序
首先堆排序分為2部分
1.將一個無序陣列變成堆
2.將堆進行排序核心操作(heapfiy,因為如果是大根堆的話,最大值在上方一直,heapfiy即可+swap(交換)即可)
首先分析第一個部分
通常有2中方法
1.最常用的一種是將陣列依次遍歷,最後一次加入堆中,便可將陣列變成堆,但是此種方法的因為將陣列中所以數進行遍歷 (N),將每個數進行heapinsert(logN),所以時間複雜度為O(N*logN)
// O(N*logN)
for (int i = 0; i < arr.length; i++) {
// O(N)
heapInsert(arr, i); // O(logN)
}
2.對此有一種優化方法,從陣列尾部開始遍歷,然後進行下沉,由於是從尾部,那邊可以得到下沉數字一定為有限常數
可以嘗試這麼理解,剛開始從尾部遍歷,那麼底部只有一層嘛,這時候heapify就為下沉0,倒數第二層時候,heapify為下沉1層,倒數第三層,heapify為下沉2層,有限個數時間複雜度為o(1)
那麼總體便為o(N*1)=O(N)
for (int i = arr.length - 1; i >= 0; i--) {
heapify(arr, i, arr.length);
}
然後分析第二個部分
變成堆之後,例如大根堆,最大是數字是根結點,那麼將最大的數字為尾部交換,然後將–heapsize,然後迴圈依次swap,heapify就ok了
這個方法的時間複雜度為o(n*logN)從頂部開始下沉,heapify是logN哈
詳細程式碼如下
// 堆排序額外空間複雜度O(1)
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
// O(N*logN)
// for (int i = 0; i < arr.length; i++) { // O(N)
// heapInsert(arr, i); // O(logN)
// }
//O(N)
for (int i = arr.length - 1; i >= 0; i--) {
heapify(arr, i, arr.length);
}
int heapSize = arr.length;
swap(arr, 0, --heapSize);
// O(N*logN)
while (heapSize > 0) {
// O(N)
heapify(arr, 0, heapSize); // O(logN)
swap(arr, 0, --heapSize); // O(1)
}
}
什麼時候使用語言自帶api,什麼時候使用自己的手寫api
首先我們需要明確一點,我們需要重寫編寫一個類代替原有api,肯定當前api無法滿足我們的情況,我們來重寫api達到我們的效果
我們現在來看一種效果,我們現在不是int型別,是一個引用型別例如Teacher(假設包含id,name),我們通過比較器(後續部落格會有一篇詳細結束比較器的,會更新的,嘿嘿)
對其進行id比較,變成堆之後,(切記是以及變成堆之後)我們對其中某一個Teacher進行操作,將他的id變化,那麼這個時候整個堆會發生巨大變化(變成不是堆結構),而這不是使用者本意,使用者只是想修改某一個teacher的資訊,然後依然希望這個list是堆,換句話說,修改之後依然希望類自己進行維護,修改之後的結構自己進行復原變成堆
所以這個時候,語言自帶的api無法完成這個操作(java,python沒有,就算某些語言有,也是進行整體heapinsert,時間複雜度太高不適應)這個時候我們便需要自己首先一個api,來完成此操作
手寫解決上述問題優化的堆
核心思想便是使用HashMap<T, Integer> indexMap;對修改位置的索引進行記錄,在push的時候將指標(地址)與索引進行記錄在pop的時候進行刪除,
核心在於regsion
通過值可以得到索引,然後對索引依次進行heapify與heapinsert巧妙在於因為堆的特性要麼上升要麼下沉,時間複雜度與o(logN)
public static class MyHeap<T> {
private ArrayList<T> heap;
private HashMap<T, Integer> indexMap;
private int heapSize;
private Comparator<? super T> comparator;
public MyHeap(Comparator<? super T> com) {
heap = new ArrayList<>();
indexMap = new HashMap<>();
heapSize = 0;
comparator = com;
}
public boolean isEmpty() {
return heapSize == 0;
}
public int size() {
return heapSize;
}
public boolean contains(T key) {
return indexMap.containsKey(key);
}
public void push(T value) {
heap.add(value);
indexMap.put(value, heapSize);
heapInsert(heapSize++);
}
public T pop() {
T ans = heap.get(0);
int end = heapSize - 1;
swap(0, end);
heap.remove(end);
indexMap.remove(ans);
heapify(0, --heapSize);
return ans;
}
public void resign(T value) {
int valueIndex = indexMap.get(value);
heapInsert(valueIndex);
heapify(valueIndex, heapSize);
}
private void heapInsert(int index) {
while (comparator.compare(heap.get(index), heap.get((index - 1) / 2)) < 0) {
swap(index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
private void heapify(int index, int heapSize) {
int left = index * 2 + 1;
while (left < heapSize) {
int largest = left + 1 < heapSize && (comparator.compare(heap.get(left + 1), heap.get(left)) < 0)
? left + 1
: left;
largest = comparator.compare(heap.get(largest), heap.get(index)) < 0 ? largest : index;
if (largest == index) {
break;
}
swap(largest, index);
index = largest;
left = index * 2 + 1;
}
}
private void swap(int i, int j) {
T o1 = heap.get(i);
T o2 = heap.get(j);
heap.set(i, o2);
heap.set(j, o1);
indexMap.put(o1, j);
indexMap.put(o2, i);
}
}
結語
第一次寫部落格,搞了一晚上,肯定寫的不好,希望大家不吝賜教,也希望能幫助到大家,也為自己總結使用,如果有不對的地方,歡迎大家指正
- 編譯安裝Mysql8.0.22
- 由Hadoop驅動的原始大資料時代已於2019年6月結束…….858
- Apache Jmeter 教程
- 中國科學院正式回覆饒毅:不再進行調查
- Android熱修復及外掛化原理
- 【資料庫MySQL】練習---備份及恢復
- 一組強大的CSS3 Material 按鈕
- No.8 bin和sbin的區別
- nginx配置ssl證書訪問不了https網站
- 大根堆與小根堆的理解,如何手寫一個堆,以及什麼時候用自己手寫的堆,什麼時候用語言提供堆的api,(二者的區別)
- FreeRTOS的License許可說明~
- 穩定流暢、高清晰, 華為HMS Core帶來一站式視訊服務
- “模板方法 職責鏈設計模式”解決業務場景重複以及場景之間依賴
- vi視窗切分命令(split命令)
- Linux學習筆記
- MySQL事務隔離級別以及髒讀、幻讀、不可重複讀示例
- 基於live555的rtsp播放器:資料接收(拉流)
- APACHE 2.2.15 TOMCAT6.0.26配置負載均衡
- 資料恢復基礎和進階教程(一)
- 2011年11月51CTO桌布點評活動獲獎名單【已結束】