昂貴、複雜、低效... 中小型企業如何打破大數據技術棧困境?


大數據已經成為當代經濟增長的重要驅動力
數字經濟,已經成為當今經濟發展中非常重要的一部分。
與農業經濟、工業經濟如出一轍,數字經濟活動需要土地、勞動力、資本、技術以及相應配套基礎設施。不同之處在於:第一,很多要素都需要數字化;第二,會產生“數據”這一新的生產要素。
在數據要素市場化配置上升為國家政策的當下,大數據已經成為推動經濟高質量發展的新動能。由於物聯網,工業互聯網和各種智能設備的廣泛應用,智能化設備所產生的數據日益龐大。而要支撐如此體量和類型多樣的數據採集,存儲, 應用及市場化離不開大數據技術。
大數據技術仍然只有少數大型企業能掌握
時至今日,大數據概念不再晦澀,其技術已經發展了近 20 年。網絡新聞,線上購物,互聯網打車等場景都是大數據常見的應用。
然而在產業側,企業對大數據的應用落地卻不盡如人意。大數據技術棧的複雜性和落地成本讓絕大部分中小企業望而生畏。
有不少盲目上馬數據平台/數據中台項目的企業最後竹籃打水一場空,為什麼企業應用大數據技術如此之難呢?讓我們通過兩個典型的數據平台案例來一探究竟。
案例 1:大數據營銷系統
大數據營銷系統常見於互聯網行業,零售行業,金融行業。
核心是在平台採集大量用户行為信息後,對用户喜好打上一定標籤,同時把同類型的廣告或者產品分發到對應類別用户終端上,以提升整體銷量或者廣告點擊率。構建這類大數據營銷應用相當複雜。
典型的營銷數據平台架構如下圖所示。
其中分成離線和實時兩套鏈路。離線鏈路負責大批量的數據計算,例如對歷史存量的訂單或者用户行為進行分析。實時鏈路負責對流式的數據進行快速的數據分析,例如用户的點擊流,瀏覽行為等等。
這套架構涉及到的核心組件需要 6-10 個,周邊組件多達數十個。數據的存儲產生多份宂餘,流轉鏈路中的可靠性經常無法得到保證。由此,數據工程師經常耗費大量時間檢查數據一致性。
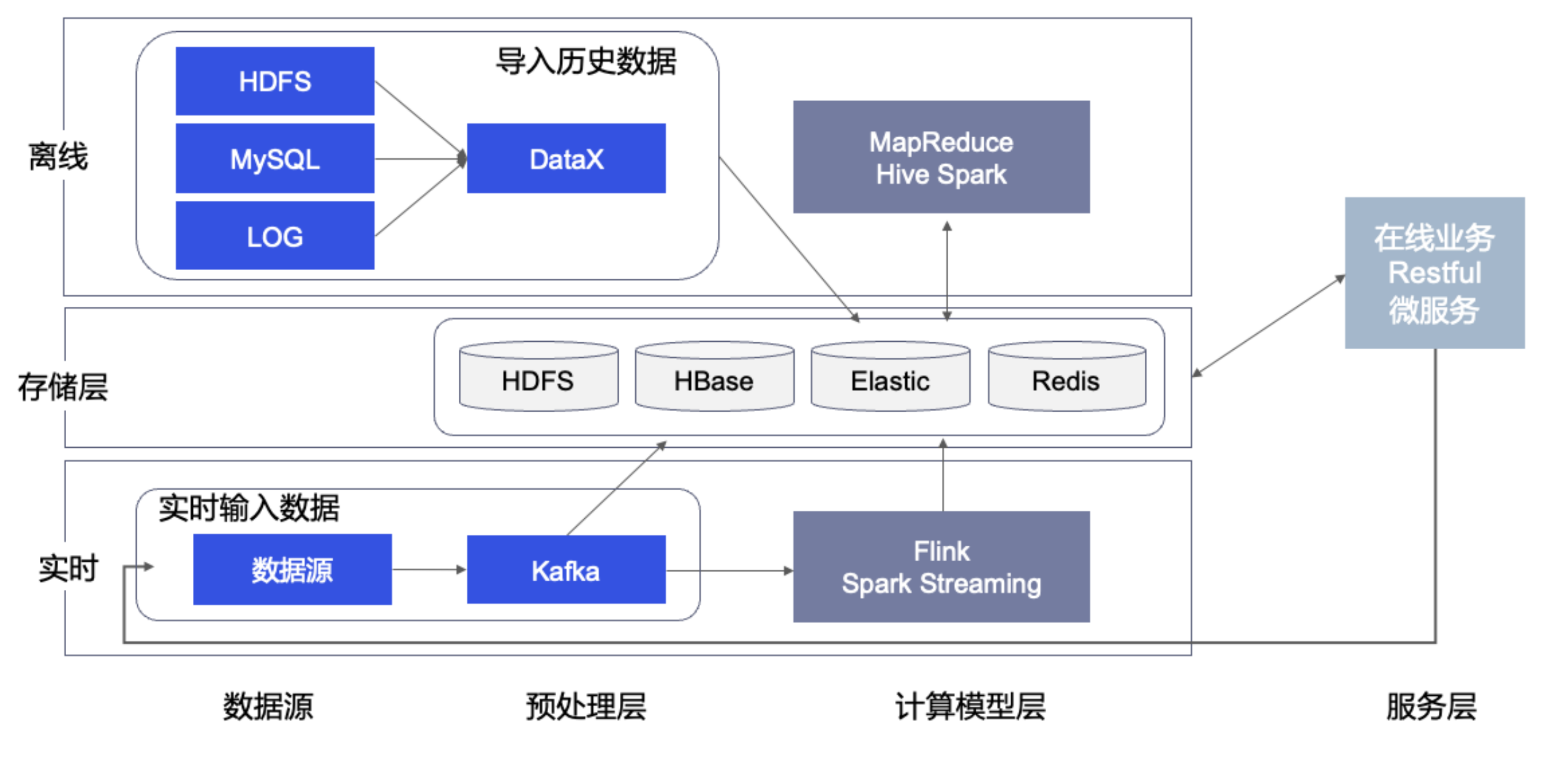
圖-典型營銷大數據平台技術架構
做這樣一個營銷大數據平台,團隊配置難度更甚架構構建,往往需要兩個團隊的 20 多位專業工程師來共同建設。
團隊一負責數據基礎,如果將大數據應用類比成餐廳,這就是建房子和裝修廚房的團隊。團隊二負責數據應用,對餐廳來説,這就是做菜和上菜的團隊。
如此,團隊配置的成本必然是非常高昂。在騰訊、阿里這種頂級互聯網公司中,內部冠有“數據平台”名字的團隊就有數個,少的團隊 10-20 人,多的團隊高達數百人。
案例 2:智能製造數據中台
自“中國製造 2025”提出,數字化轉型和實踐走到今天,取得了非常多成果,也帶來了很多新的挑戰。
近年來由於政策的驅動和行業認知的進步,大量的智能製造項目開始上馬。在“中台思想”的流行下,經常會同時上馬一個數據中台子項目。打造智能製造數據中台,難度也是非常大的。
我們來看下圖中展示的一個典型的製造業企業的整體 IT 系統架構和其中需要用到的數據庫組件。

圖-製造業典型 IT 系統架構
-
在底層與生產設備打交道的是自動控制系統,為了採集高頻的設備數據,製造業企業往往會用到如 PI 這樣的專用實時數據庫或者 InfluxDB 這樣的時序數據庫。
-
其次是製造執行的 MES 系統,MES 系統是將人員,物料,設備等進行有效協作和管理的系統。因此往往依賴於一個或多個關係型數據庫,一般預算較高的用 Oracle,SQL Server,預算較低的用開源的 MySQL,PostgreSQL。
-
再上層是企業的 ERP 系統,其中會涉及更多維度的數據,包括供應鏈,銷售,庫存,財務等等。而這個也依賴於強大的關係型數據庫,根據預算從 SAP Hana,Oracle 到 MySQL 都很常見。
-
最上層就是各種所謂的 BI 智能化應用,包括各類指標報表的監控,各類產量,質量,耗能等分析應用,甚至一些機器學習預測算法應用。
要實現一整套智能製造的數據中台就需要將上述多層的 IT 系統進行打通,將其中多個業務數據庫的數據匯聚上來,同時建立多條 ETL 管道將相關的數據進行集成和處理,同時選用不同的數據庫組件進行高性能或者海量分析應用。下圖是一個典型的智能製造數據中台架構。
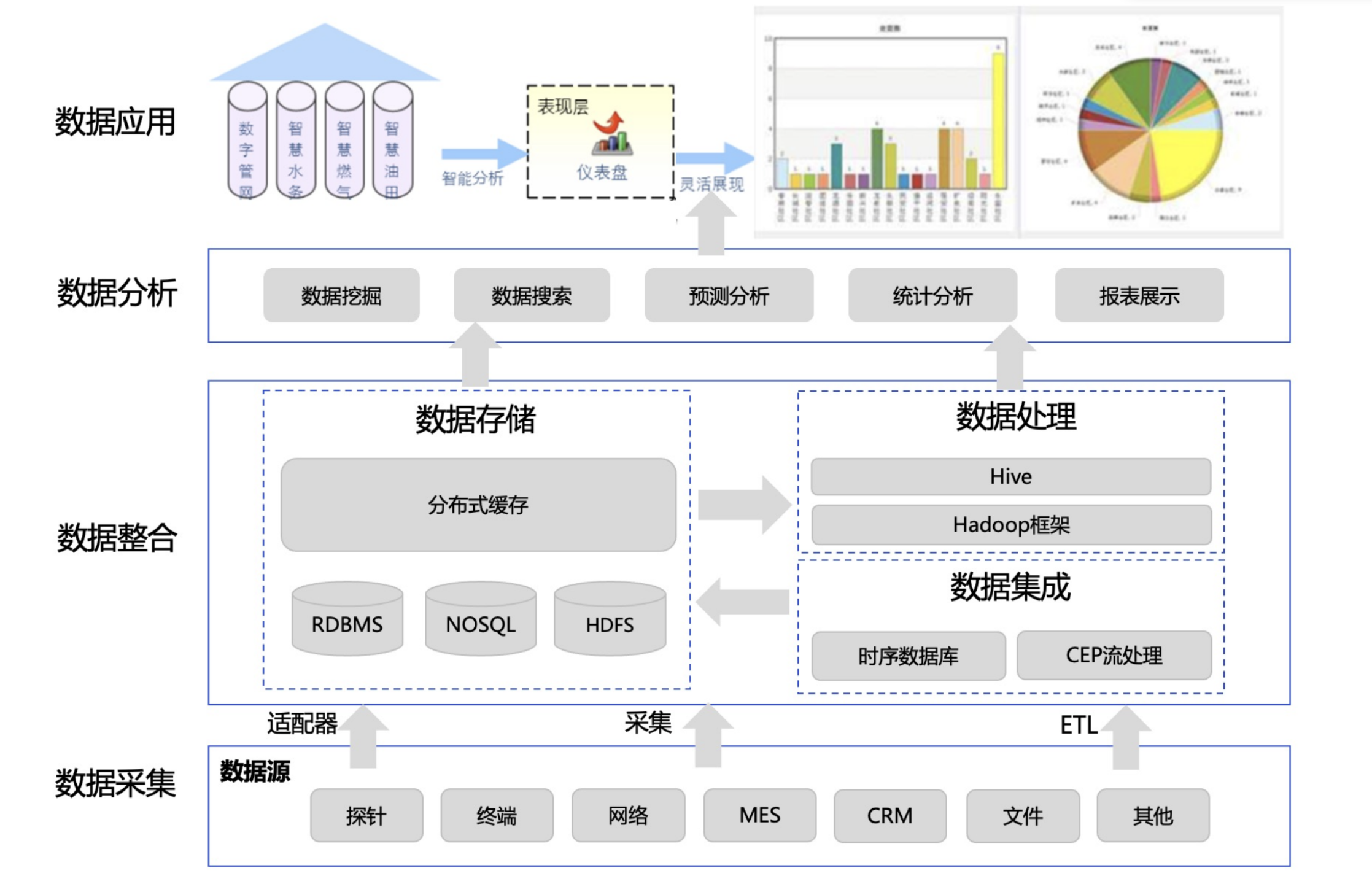
圖-智能製造數據中台架構
建設這樣一套數據中台實際上與之前營銷大數據的案例類似,組件繁多與數據流轉的問題同樣也存在,而且在另外幾個方面甚至會更有挑戰。
-
第一,製造業的某些應用往往有非常強的實時性要求,因為產線每停一段時間就會有很大的經濟損失,因此可能某個查詢或者分析必須在很短的時間裏出結果。
-
第二,製造業中設備所產生的數據類型非常豐富,其中只有少量數據是結構化的,還有數據是文本,二進制圖片等非結構化數據。
-
第三,製造業往往對 IT 預算卡的很嚴,通常無法給予比較高的服務器採購預算,建設團隊必須在很有限的底層硬件資源中實現既定的功能。
-
第四,製造業並不具備如互聯網一樣充分的 IT 人員供給,在互聯網行業中應用相同技術和架構的技術人才獲取門檻更加難以克服。
這一切都註定了在製造業中應用大數據技術是一個挑戰度更高的課題,只有極少數頭部企業能將大數據應用到一定程度。而廣大的中小製造型企業就更加無法享受到大數據技術帶來的收益。
大數據系統的普遍痛點
通過以上兩個行業大數據應用案例,我們可以看到,當前的大數據技術架構普遍有如下 3 類痛點:
1、 昂貴
公司建設一個大數據平台最少需要一支十人以上的有經驗的數據平台與應用的工程師團隊。而這樣的工程師本身在行業裏都是稀缺資源,大多集中在互聯網和科技行業,傳統行業即使花大價錢也很難吸引這類團隊。
2、複雜
平均一個公司建設一個大數據平台需要引入至少 5 個數據組件。大量組件是開源項目,並沒有完整的商業支持,企業需要自己花力氣去調研和學習這些組件。而且每種數據組件都有自己的 API 接口、語言和事務模型,都要各自安裝、監控、補丁和升級。工程師需要花大量時間維護這套架構。企業的內部人員也並非一成不變,複雜的技術棧讓平台的運行狀態對人員變化更加敏感。
3、低效
企業建設大數據平台的目的還是為了更好的挖掘數據價值,對業務進行賦能。過於複雜的大數據架構將導致建設週期過長,很多企業管理層開始寄希望於大數據快速能讓業務增長,但發現光搭建技術架構和梳理數據就需要半年甚至更長的時間,很快就失去耐心砍掉項目。此外,過去底層架構的複雜,讓基於大數據平台的業務應用很難快速迭代。
這些痛點,都導致了當前的大數據技術架構是隻有少數大型企業才能“用的起,玩的轉”的“高級定製時裝”,離行業的普適依然道阻且長。
大數據技術的發展歷程
大數據技術的應用現狀如此複雜,我們不禁要追問,大數據技術是如何逐步發展至今的?以史為鑑,也許我們能找着規律與解法。
自從計算機誕生以來,就有了數據應用。最早是紙帶、卡片等物理介質,後來發展出了文件系統,但是這些手段都無法滿足數據的增長,以及多用户共享數據和快速檢索數據的需求。數據庫應運而生。
最早的數據庫所使用的典型數據模型主要有層次數據模型和網狀數據模型,它們可以解決一定的數據存儲和管理問題,但是在數據獨立性和和抽象級別上仍有較大的欠缺。1970 年,IBM 的研究員 Edgar F.Codd 發表了幾篇關於關係數據模型的論文,奠定了關係型數據庫的基礎。
隨着幾個經典的關係型數據庫產品 Ingres(後來演變成 Postgres), Oracle, DB2 的誕生,關係型數據庫成為了整個數據管理行業的主流。傳統關係型數據庫始終維持了非常簡潔的架構,它劃分了業務處理和數據處理的邊界,業務邏輯由業務代碼實現,數據處理邏輯由數據庫實現,兩者之間使用標準 SQL。
而 2000 年以來,隨着大型互聯網公司的崛起,傳統關係型數據庫的水平擴展能力不足,無法滿足海量數據的處理要求。為解決這個矛盾,在最初的關係型數據庫基礎上,發展出大數據技術體系以滿足高性能查詢、可擴展性、海量數據處理等需求。
企業在實際場景使用時,構建數據平台要同時用到幾種技術棧的組合。比如下圖這張常見的大數據平台架構圖。
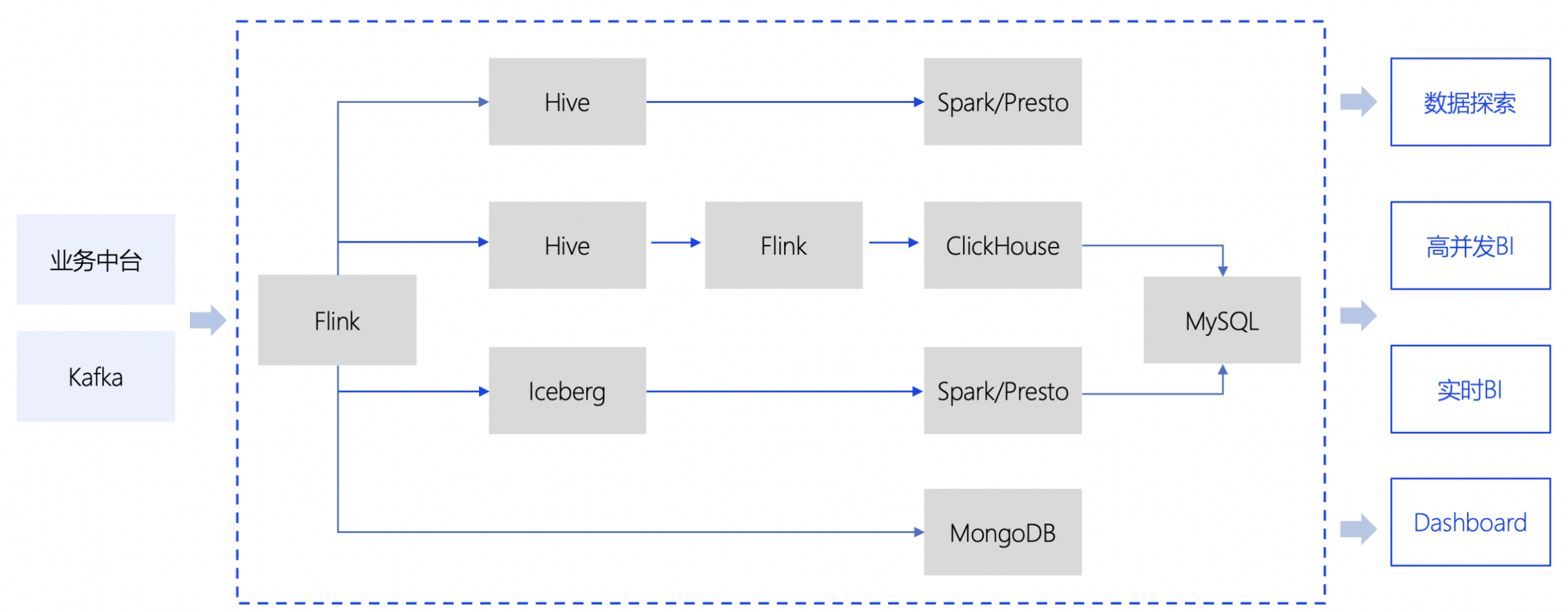
圖-當前常見大數據平台架構圖
面對如此複雜的系統,促使我們思考。最初的關係型數據庫系統裏僅僅通過 SQL 就隔離和解耦了數據處理和業務模塊。簡潔、令人懷念。
今天,為了解決數據處理的問題,業務人員不得不直面數據處理的問題,不斷從大數據社區裏引入一個又一個開源組件,通過一些“膠水”代碼,將它們組合起來,才能完成數據處理任務。這樣的開發體系和複雜的技術棧,對於業務開發人員要求很高,而企業需要維護這些系統所付出的各種成本也非常高。
超融合數據庫是實現大數據技術普惠的必然選擇
縱觀大數據的發展歷史,我們可以看到,之所以大數據技術只能被少數大型企業所玩轉,本質原因在於大數據技術本身的複雜性。
那破局之道在何處呢?答案還是在大數據技術本身。我們回到數據庫誕生的初衷:解決數據和業務的隔離問題,將數據處理的歸數據庫,將業務處理的歸應用。
重新把數據處理和業務處理解耦開,才能讓大數據技術變得像當年互聯網上風靡的 LAMP(Linux+Apache+MySQL+PHP)一樣簡單而普惠。
而要做到這一點,目前有三條技術路線:
第一條技術路線,在眾多大數據組件的基礎上,根據需要處理業務的特點,抽象一層通用的接口。把複雜的數據處理封裝在通用接口之下,業務人員只使用通用接口來解決業務問題。可以一定程度緩解前面提到的各種問題,但是由於底層使用的還是現在大數據體系下的組件,難以高效整合,且一旦業務發生變化,之前的抽象就可能發生變化。因此大部分項目在系統可靠性、兼容性和可維護性以及數據宂餘度、一致性和實時性等方面,無法令人滿意。
第二條技術路線是在數據庫層面提供整合,即傳統的多模數據庫。通過在多種數據庫組件的上面,封裝一層,提供統一對外的 SQL 接口,讓開發者使用起來像用一個數據庫一樣,從而大幅簡化系統設計複雜度。查詢時如果需要多模查詢,就是把查詢打到幾個數據庫組件上進行聯邦查詢。這個方案風格,比較類似於分佈式 OLTP 數據庫裏面的分庫分表中間件的方案。由於背後的多個數據庫組件在日誌、事務、一致性和高可用等實現方式並不相同,導致這種強行“縫合”的多模數據庫並不好用。
第三條技術路線是提供融合型數據庫產品。業內在這個方向上已經取得了一些進展,許多產品已經出現了能力互相融合的情況。2014 年,Gartner 提出了 HTAP 的概念,以 Greenplum,TiDB 和 Oceanbase 為代表的數據庫系統都具備 HTAP 能力:同時支持交易和分析型操作的支持,在確保事務能力的同時提供實時的數據分析能力。2021 年的 DTCC 大會上,更有國內的數據庫廠商提出了超融合時序數據庫的概念:融合了傳統的關係型數據庫、時序數據庫和分析型數據庫為一體。由此可見,數據庫產品不斷走向融合的歷史趨勢已經形成。
也正是在第三條技術路線的指引下,成立於 2021 年的矩陣起源公司致力於打造 MatrixOne 超融合異構雲原生數據庫,為開發者、商業和組織打造極簡的大數據建設工具。在思考了當前大數據體系的問題和未來數據處理技術的發展趨勢之後,我們認為新一代的超融合數據庫應該具備以下的能力:
-
用户交互方式上,能夠支持標準的 SQL 操作
-
支持業務場景上,能夠支持 TP、AP,也就是 HTAP 的能力
-
處理負載方式上,要能夠同時支持流和批量兩種計算,也就是流批一體的能力
-
支持數據類型上,要能夠支持時序數據、時空數據和機器學習特徵數據等多種負載,也就是多模的能力
-
除去確保高可用的數據副本,儘量避免在系統內引入宂餘
-
可提供強一致的分佈式事務;可根據業務規模,提供在線水平擴展支持海量數據存儲
-
存算分離,存儲節點、計算節點、元數據節點甚至調度節點全部解耦,都可以獨立擴縮容
-
一套方案支持在公有云和私有化部署,公有云部署是雲原生架構,支持雲上的廉價共享存儲和容器編排,且能做到公有云部署和私有化部署互聯互通,真正做到雲邊協同,甚至雲邊一體。
如果用一句話來描述其能力的話,可以這樣總結:流批一體,TP / AP 一體,雲邊一體。那麼,有這樣能力的超融合數據庫系統,給我們帶來的是什麼?
-
用户無需為了解決海量數據分析,搭建如此複雜的一套大數據平台,從而極大簡化了系統複雜度
-
單一系統,更加穩定,運維更加容易,技術人員的學習成本更低,用户體驗更好
-
避免宂餘存儲,宂餘傳輸,宂餘處理,降低硬件投入成本
-
融合多功能數據庫引擎,兼顧性能與功能
而之前給出的複雜大數據平台架構,就可以簡化為:

圖-理想的數據平台架構圖
數據庫與大數據技術已經發展數十年,在技術上已經枝繁葉茂,但是隨着數據規模的增大,用户處理數據的難度也越來越大。
我們相信超融合數據庫的出現,將能有效的解決當前的這一矛盾。16 年前數據庫領域的圖靈獎獲得者 Michael Stonebraker 提出了一套數據庫系統無法適用所有數據處理場景的論斷,也就是"One size doesn't fit all"。但是,在那篇文章的最後,Stonebraker 展望了未來數據庫系統架構的幾個演進方向,其中最後一個也是我們認同的方向:從頭開始設計和實現一個可以適合多種場景的數據庫系統。16 年後的今天,我們認為新一代超融合數據庫可以做到 "One size doesn't fit all, but most"。
未來企業應用超融合數據庫建設大數據平台會像使用關係型數據庫一樣簡單,超融合數據庫也是真正實現大數據技術普惠的必然選擇。