爆肝整理5000字!HTAP的关键技术有哪些?| StoneDB学术分享会#3
在最新一届国际数据库顶级会议 ACM SIGMOD 2022 上,来自清华大学的李国良和张超两位老师发表了一篇论文:《HTAP Database: What is New and What is Next》,并做了 《HTAP Database:A Tutorial》 的专项报告。这几期学术分享会的文章,StoneDB将系统地梳理一下两位老师的报告,带读者了解 HTAP 的发展现状和未来趋势。
在深度干货!一篇Paper带您读懂HTAP这期分享中我们已经把HTAP产生的背景和现有的HTAP数据库及其技术栈做了一个简单的介绍,这一期,我们将着重讲一讲报告中对HTAP关键技术的解读。
在正式开始前,先给上期简单收个尾,报告中提到 HTAP 数据库除了以下四种:
- Primary Row Store + InMemory Column Store
- Distributed Row Store + Column Store Replica
- Disk Row Store + Distributed Column Store
- Primary Column Store + Delta Row Store
还补充了3种,感兴趣的读者可以自行了解:
- Row-based HTAP systems:如 Hyper(Row)、BatchDB等
- Column-based HTAP systems:如 Caldera、RateupDB等
- Spark-based HTAP systems:如 Splice Machine、Wildfire等
下面进入正文,本篇报告中主要介绍了HTAP的五大类关键技术,分别是:
- Transaction Processing(事务处理技术)
- Analytical Processing(查询分析技术)
- Data Synchronization(数据同步技术)
- Query Optimization(查询优化技术)
- Resource Scheduling(资源调度技术)
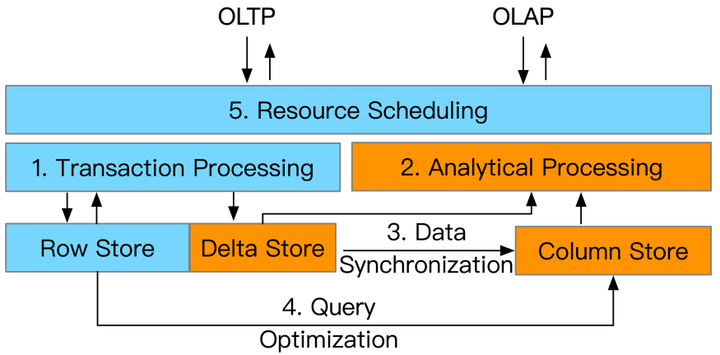
Overview of HTAP Techniques
这些关键技术被最先进的HTAP数据库采用。然而,它们在各种指标上各有利弊,例如效率、可扩展性和数据新鲜度。
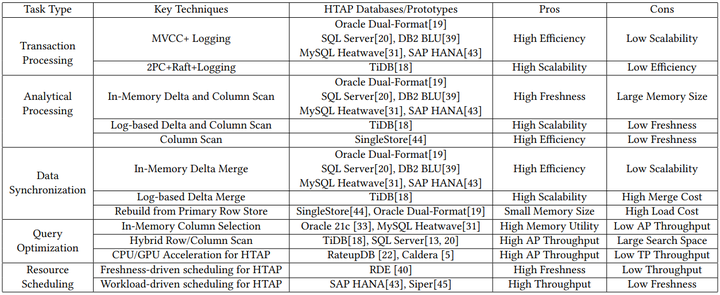
An Overview of HTAP Techniques

一、事务处理技术(OLTP)
HTAP数据库中的OLTP工作负载是通过行存储处理的,但不同的架构会导致不同的TP技术。它主要由两种类型组成。
1使用内存增量更新的单机事务处理
Standalone Transaction Processing with In-Memory Delta Update
关键技术点:
- 通过MVCC协议进行单机事务处理
- 通过内存增量更新进行insert/delete/update操作
相关数据库:Oracle、SQL Server、SAP HANA 和 StoneDB 等。
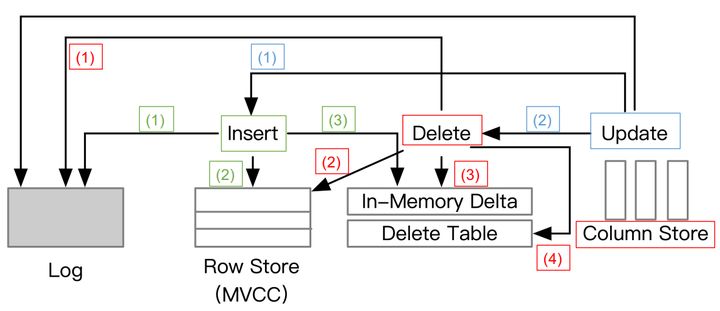
Standalone TP for insert/delete/update operations
上面这张图介绍了单机事务处理执行insert/delete/operations操作的一个逻辑过程,总体上是借助MVCC+logging,它依赖于MVCC协议和日志记录技术来处理事务。具体来说,每个插入首先写入日志和行存储,然后附加到内存中的增量存储。更新创建具有新生命周期的行的新版本,即开始时间戳和结束时间戳,即旧版本在删除位图中被标记为删除行。因此,事务处理是高效的,因为 DML 操作是在内存中执行的。请注意,某些方法可能会将数据写入行存储 或增量行存储 ,并且它们可能仅在事务提交时写入日志。
一般有三种方式来实现内存增量存储,分别是:Heaptable(堆表)、Index organized table(索引组织表) 和 L1 cache(一级缓存),具体区别如下表:
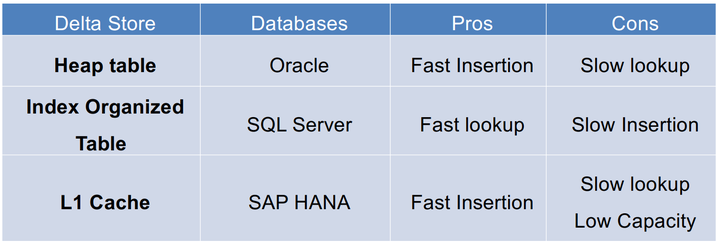
Three implementations for an in-memory delta store
三者主要的区别在于插入(insertion)速度、查询(lookup)速度和容量(capacity)大小上。
2使用日志回放的分布式事务处理
Distributed Transaction Processing with Log Replay
关键技术点:
- Two-Phase Commit(2PC)`+Paxos 用于分布式TP和数据复制
- 使用Log replay(日志回放)更新行存储和列存储
相关数据库:F1 Lightning
注:这里有稍有不同的分布式TP方案,就是采用主从复制(Master-slave replication)的方式实现HTAP,比如 Singlestore。
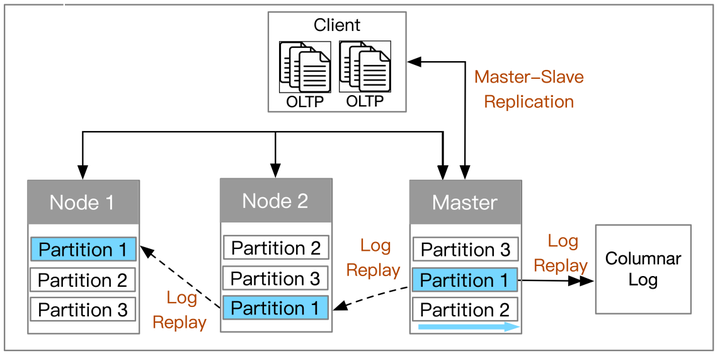
Master node handles the transactions, then replicate the logs to slave nodes
如上图所示,这种主从复制的方式下,主节点处理事务,然后将日志复制到从节点再做分析。
另外就是通过2PC+Raft+logging,它依赖于分布式架构。
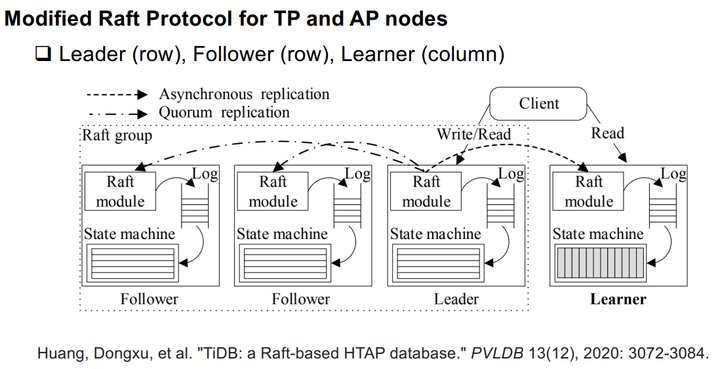
Modified Raft Protocol for TP and AP nodes
它通过分布式事务处理提供了高可扩展性。ACID事务在分布式节点上使用两阶段提交 (2PC) 协议、基于Raft的共识算法和预写日志 (WAL) 技术进行处理。特别是leader节点接收到SQL引擎的请求,然后在本地追加日志,异步发送日志给follower节点。如果大多数节点(即法定人数)成功附加日志,则领导者提交请求并在本地应用它。与第一种内存增量更新的方式相比,这种基于日志的方式由于分布式事务处理效率较低。
3对比
最后我们将提到事务处理技术做一个对比:

Comparisons of TP techniques in HTAP Databases

二、查询分析技术(OLAP)
对于HTAP数据库,OLAP负载使用面向列的技术执行,例如压缩数据上的聚合和单指令多数据 (SIMD) 指令。这里介绍两大类型和三种方式:
1内存增量遍历 + 单机列扫描
Standalone Columnar Scan with In-Memory Delta Traversing
关键技术点:
- 单指令多数据(SIMD),向量化处理
- 内存增量遍历(In-Memory Delta Traversing) 相关数据库:Oracle、SQL Server
举几个例子:
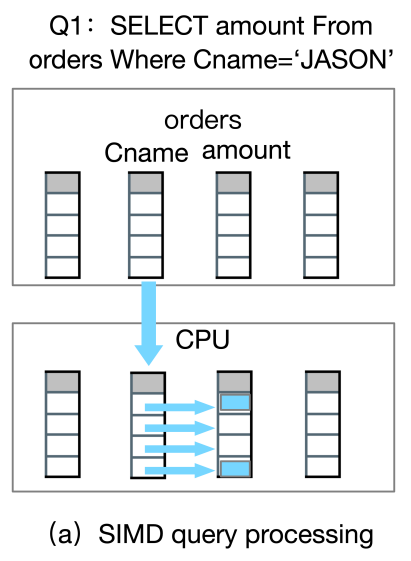
在(a)里,我们查询订单表中名称为JASON的花了多少钱,那么基于SIMD的查询方式,是可以通过CPU把数据Load到寄存器中,只需要一个CPU执行的周期,就可以同时去扫描查到满足条件的两个数据。

如果基于传统的火山模型,用的是一种迭代模型,就需要访问四行数据,而基于这种列存的方式,只要访问一次就可以得到结果。
同样的,还可以通过这种方式做基于Bloom Filter的向量化连接,也可以提高查询分析的效率。
在增量表中获取可见值,并跳过删除表中的陈旧数据
除此之外,我们在做列存扫描的同时要去扫描一些可见的增量数据来实现实时数据的分析,也去扫描删除表中是否有过期的数据,最终达到数据是新鲜的。
2日志文件扫描 + 分布式列扫描
Distributed Columnar Scan with Log File Scanning
关键技术点:
- 列段上的分布式查询处理
- 基于磁盘的日志文件归并与扫描 相关数据库:F1 Lightning
Distributed Columnar Scan

Samwel, Bart, et al. "F1 query: Declarative querying at scale."PVLDB 11(12) , 2018: 1835-1848.
如上图所示的分布式列扫描,传统方法就是基于多个Worker来做并发的多节点下进行算子下推,扫描之后,在上层做一些聚集、HASH、排序等一些操作。
Log File Scanning
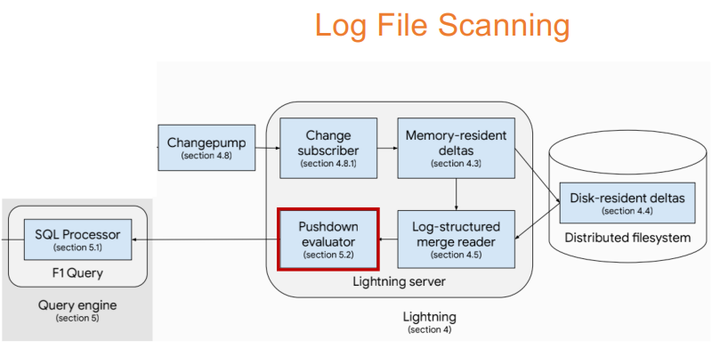
Yang, Jiacheng, et al. "F1 Lightning: HTAP as a Service." PVLDB 13(12), 2020: 3313-3325.
与分布式列扫描同时进行的还有日志文件扫描,我们还要基于列存储来做算子下推来查到当前增量存储中最新的数据,再进行数据合并。上图里的F1 Lighting就可以支持把10个小时的数据合并到Delta中。
3技术总结
内存中增量和列扫描
将内存中的增量和列数据一起扫描,因为增量存储可能包括尚未合并到列存储的更新记录。由于它已经扫描了最近可见的delta tuples in内存,因此OLAP的数据新鲜度很高。
基于日志的增量和列扫描
将基于日志的增量数据和列数据一起扫描以获取传入查询。与第一种类似,第二种使用列存储扫描最新的增量用于OLAP。但是,由于读取可能尚未合并的delta文件,这样的过程更加昂贵。因此,数据新鲜度较低,因为发送和合并delta文件的高延迟。
列扫描
只扫描列数据以获得高效率,因为没有读取任何增量数据的开销。但是,当数据在行存储中经常更新时,这种技术会导致新鲜度低。
4对比

Comparisons of AP techniques in HTAP Databases
对于第一种单机列扫描+内存增量遍历来说,优点是数据新鲜度较高,缺点是需要比较多的内存空间。对第二种分布式列扫描+日志文件扫描来说,优点是扩展性高,缺点是效率比较低。

三、数据同步技术(DS)
由于在查询时读取增量数据的成本很高,因此需要定期将增量数据合并到主列存储中。这个时候,数据同步(Data Synchronization)技术,就非常重要了,也是分为两大类型。
1类型一:内存增量合并
关键技术:
- 基于阈值的合并(Threshold-based merging)
- 两阶段数据迁移(Two-phase data migration)
- 基于字典的迁移(Dictionary-based migration)
相关数据库:Oracle、SQL Server、SAP HANA
Threshold-based merging
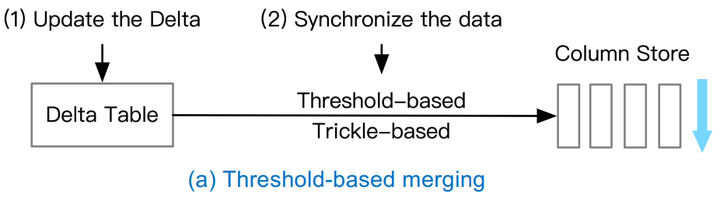
举个例子,如果阈值达到列存储90%的容量时,我们就把Delta Table中的数据合并到Column Store当中,当然这种方式有个缺点——如果阈值设置的太大可能会导致AP的性能发生抖动,所以看到图里我们加了一个Trick-based,最好是定小量按期地去合并,做一个权衡。
Two-phase data migration

两阶段数据的迁移,可以拿SQL Server举例,如图所示:
- 第一阶段:迁移准备
- 第(1)步先插入RID去把需要隐藏的数据写入到删除表当中;
- 第(2)步把这些数据分配RID后生成Delta Colunm Store;
- 第二阶段:迁移操作
- 第(3)步,把刚刚插入进去的RID删除;
- 第(4)步,最后真正把Delta中相关的数据删除,最后才把生成的增量列存合并到主列存中,达到了数据迁移的效果。
Dictionary-based migration
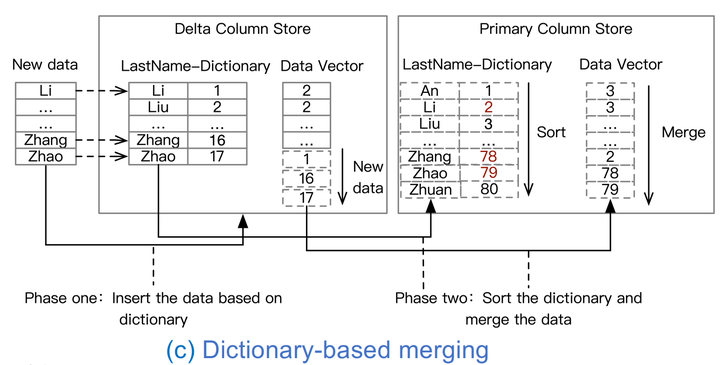
第三种基于字典的迁移,SAP HANA就是采用这种方式。如图所示,它第一阶段主要是针对每一列的数据做一个本地字典的方式映射过去增加对应的数据向量,第二阶段,才会把这个字典加入到全局的字典,做一个全局的排序,最后合并到数据向量当中。
2类型二:基于日志的增量合并
关键技术:LSM-tree 和 B-tree
相关数据库:F1 Lighting
这种类型分两层:
- Memory-resident deltas(驻留内存的增量),主要是row-wise
- Disk-resident deltas(驻留磁盘的增量),主要是column-wise

Log-based delta merge
如图所示,第一阶段会把小文件、小delta按它到来的顺序合并到增量的文件当中,第二阶段会通过查找B+树来做一个有序合并,最终让合并的Chunk是有序的。这主要涉及解决基于多版本的一些Log怎么去做合并和折叠,其中B+树主要的作用就是在有序合并时去加速数据查找的过程。
3技术总结
可归类为有3种数据合并技术。分别是:
- 内存中增量合并;
- 基于磁盘的增量合并;
- 从主行存储重建。
第一个类别定期将新插入的内存中增量数据合并到主列存储。引入了几种技术来优化合并过程,包括两阶段基于事务的数据迁移、字典编码排序合并和基于阈值的变化传播。
第二类 将基于磁盘的增量文件合并到主列存储。为了加快合并过程,增量数据可以通过B+树进行索引,因此可以通过键查找有效地定位增量项。
第三类从主行存储重建内存列存储。这对于增量更新超过某个阈值的情况很典型,因此重建列存储比合并这些具有大内存占用的更新更有效。
4对比

Comparisons of DS techniques in HTAP Databases
总体来看,基于内存的增量合并效率比较高,扩展性差点儿;基于日志的合并,扩展性好,但是多重合并的代价会比较高。

四、查询优化技术
HTAP中查询优化技术主要涉及三个维度,包括:

Query Optimization in HTAP databases
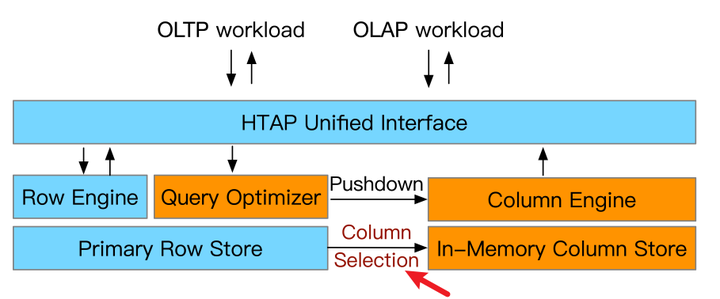
1In-Memory Column Selection
- 解决的问题:要从行存储区中选择哪些列进入内存呢?简单的做法是全部选择进去,但那样存储和更新的代价会很高,所以一般是基于历史的统计信息和现有内存的预算来做权衡选择。
- 解决方式:有两种,第一种是热力图(Heatmap),第二种是整数规划(Integer programming)
基于Heatmap,比如Oracle
通过访问频度来管理列存并进行热力图的制作。

Oracle 21c. Automating Management of In-Memory Objects., 2021.
如图所示,首先根据最下方持久化行存(Persistent Storage)来选定一些候选列集(Candidate Columns),通过记录候选集的访问频度。有些列就会变为Hot Columns,那么就可以把最新的数据Load进去(图中左下方的Populating)来达到加速查询的效果;慢慢地也有一些列会变为Cold Columns,那么就把这些冷列进行压缩(Compressed Columnar data),然后最后排除(图中右下方的Evicating)到内存当中,再选取其他被高频访问的列重复进行。
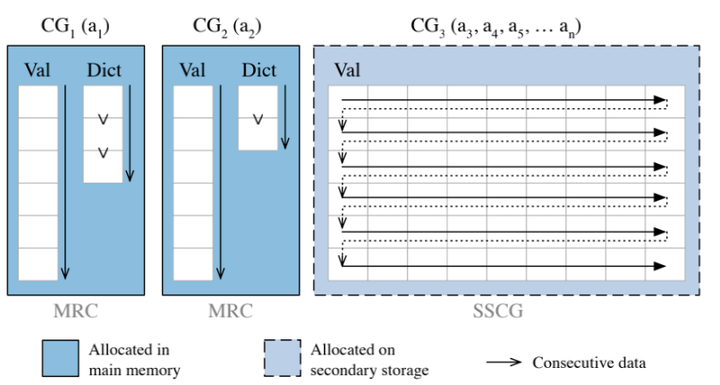
基于Integer programming,比如Hyrise
Integer programming for 0/1 Knapsack problem,第一种基于热力图的方式完全没有考虑选择列的代价,那么第二种就是把代价函数(cost-based optimization problem)考虑进去,再从二级存储中选择列。

Boissier, Martin, et al. "Hybrid data layouts for tiered HTAP databases with paretooptimal data placements." ICDE, 2018.
这个目标函数 就是要去优化所有的查询代价函数 ,而每个查询代价函数要去衡量所选择列的代价。总目标是最小化这个代价,要小于这个最大的 预算。(这里不展开讲了,感兴趣可以阅读这篇论文,也比较经典)
2Hybrid Row and Column Scan
- 解决的问题:内存中选择好列之后,如何利用混合行/列扫描加速查询呢?这个比较前沿了,像Google的AlloyDB也支持这个特性。
- 解决方式:基于规则的计划选择(Rule-based)或者基于代价(Cost-based)的计划选择。主要决定查询优化器要把哪些算子下推到列存引擎当中。

Rule-based Optimization(RBO)
先定义一些扫描的规则,比如先看列扫描,再看行扫描。相关数据库:Oracle、SQL server。
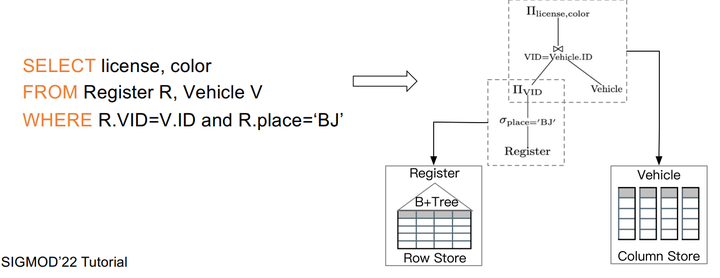
举个例子,上图中我们查找一些北京车子注册的证书和颜色,在这种规则下就可以生成一个逻辑计划树,在这个逻辑计划树里,我们先去查找底层表到底是行存还是列存,如果是列存,就做列存的方式处理,如果是行存就做一个B+树的扫描。最后合并做一个连接再返回最终结果。
Cost-based Optimization(CBO)
基于代价的方式,解决的方式是先去对比列存扫描和行存/索引扫描的代价分别是多少,然后再决定查询算子在哪里执行。

Compare the cost of row/index scan with the cost of columnar scan
3CPU/GPU Acceleration for HTAP
这个基于硬件去做HTAP的加速。比如,基于CPU/GPU异构处理器的方式进行HTAP的处理。相关数据库:RateupDB、Caldera。
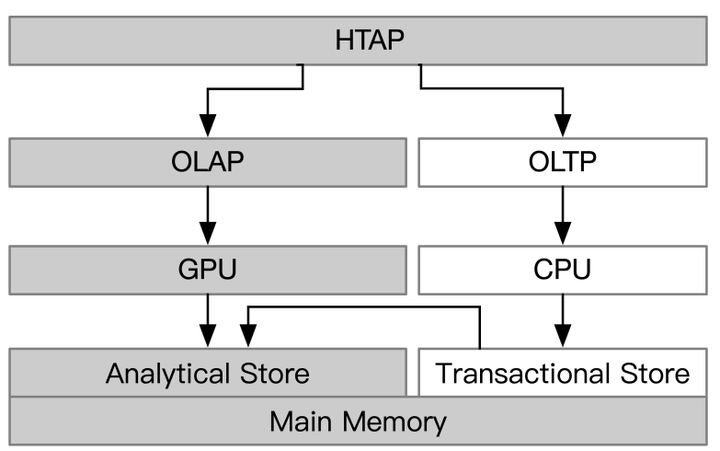
CPU/GPU processors for HTAP
- Task-parallel nature of CPUs for handling OLTP
- CPU任务并行的特性可以用来处理OLTP
- Data-parallel nature of GPUs for handling OLAP
- GPU数据并行的特性可以用来处理OLAP
涉及到一些并行计算的知识,感兴趣可以了解了解~
4技术总结
主要涉及三大技术:
- HTAP的列选择;
- 混合行/列扫描;
- HTAP 的 CPU/GPU加速。
第一种类型依靠历史工作负载和统计数据来选择从主存储中提取的频繁访问的列到内存中。因此,可以将查询下推到内存中的列存储以进行加速。缺点是可能没有选择新查询的列,导致基于行的查询处理。现有方法依靠历史工作负载的访问模式来加载热数据并驱逐冷数据。
第二种类型利用混合行/列扫描来加速查询使用这些技术,可以分解复杂的查询以在行存储或列存储上执行,然后组合结果。这对于可以使用基于行的索引扫描和完整的基于列的扫描执行的 SPJ 查询来说是典型的。我们引入了基于成本的方法来选择混合行/列访问路径。
第三种技术利用异构CPU/GPU架构来加速HTAP工作负载。这些技术分别利用CPU的任务并行性和GPU的数据并行性来处理OLTP和OLAP。然而,这些技术有利于高OLAP吞吐量,同时具有低OLTP吞吐量。
5对比

Query Optimization in HTAP databases

五、资源调度技术
对于 HTAP 数据库,资源调度是指为 OLTP 和OLAP 工作负载分配资源。当前可以动态控制OLTP 和 OLAP 工作负载的执行模式,以更好地利用资源。

Resource Scheduling
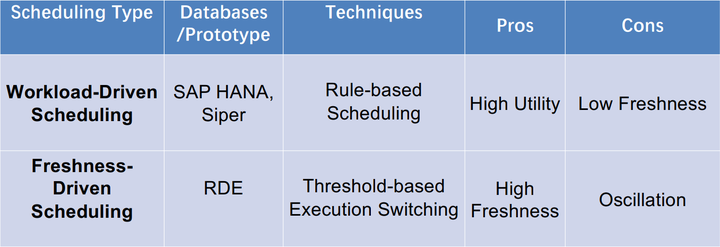
1基于工作负载驱动的调度
Workload-driven Scheduling for HTAP,就是根据HTAP工作负载的执行性能进行动态的调度,线程和内存这些根据OLTP和OLAP的性能需求动态分配资源。相关数据库: SAP HANA。
- Assign more threads to OLTP or OLAP

Psaroudakis, Iraklis, et al. "Task scheduling for highly concurrent analytical and transactional main-memory workloads." In ADMS, 2013.
举个栗子,第一种方式会分配更多的线程给OLTP或者OLAP,怎么分配呢?会在Scheduler里配置一个Watch-dog监测器,来监测当前的Worker,有一些被阻塞的Worker就分配多一些Thread,有一些比较活跃的的,就让它继续执行。
- Isolate the workload execution and assign more cache for OLAP
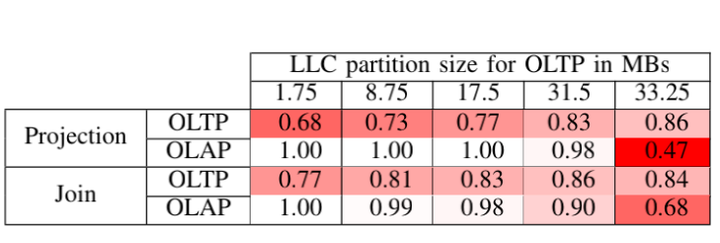
Sirin, Utku, Sandhya Dwarkadas, and Anastasia Ailamaki. "Performance Characterization of HTAP Workloads." In ICDE, 2021.
如表所示,在第三层Cache当中进行一些调度,通过实验可以得知增加OLTP存储资源时,OLAP的颜色是会变深的,这意味着影响越严重,所以还是建议在第三层尽量给OLAP多分配一些资源。
2基于新鲜度驱动的调度
Freshness-driven Scheduling for HTAP
- Switches the execution modes {S1, S2, S3}
- Default S2; When freshness < threshold, jump to S1 or S3

Raza, Aunn, et al. "Adaptive HTAP through elastic resource scheduling." In SIGMOD, 2020.
3技术总结
调度技术有两种类型,工作负载驱动的方法和新鲜度驱动的方法。前者根据执行工作负载的性能调整OLTP和OLAP任务的并行度。例如,当CPU资源被OLAP线程饱和时,任务调度器可以在增大OLTP线程的同时降低OLAP的并行度。后一个切换了OLTP和OLAP的资源分配和数据交换的执行模式。例如,调度程序单独控制OLTP和OLAP的执行以实现高吞吐量,然后定期同步数据。一旦数据新鲜度变低,它就会切换到共享 CPU、内存和数据的执行模式。其他与 HTAP 相关的技术,还有新的 HTAP 索引技术和横向扩展技术。
4对比
Resource Scheduling in HTAP databases
第一种优点是比较容易实现,但是新鲜度较低;第二种方式优点是新鲜度高,但来回切换容易导致系统震荡。

六、其他相关的HTAP技术
这里不展开介绍了,感兴趣可以看看相关的Paper。
1Multi-Versioned Indexes for HTAP
- Parallel Binary Tree (P-Tree)
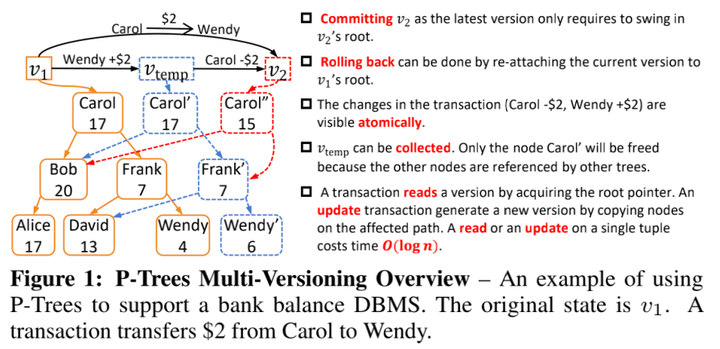
Sun, Yihan, et al. "On supporting efficient snapshot isolation for hybrid workloads with multiversioned indexes." PVLDB 13(2), 2019.
- Multi-Version Partitioned B-Tree (MV-PBT)

Riegger, Christian, et al. "MV-PBT: multi-version indexing for large datasets and HTAP workloads." In EDBT, 2020.
2Adaptive Data Organization for HTAP
- H2O [Alagiannis et al, SIGMOD 2014], Casper [Athanassoulis et al, VLDB 2019]
- Peloton [Arulraj et al, SIGMOD 2016], Proteus [Abebe et al, SIGMOD 2022]
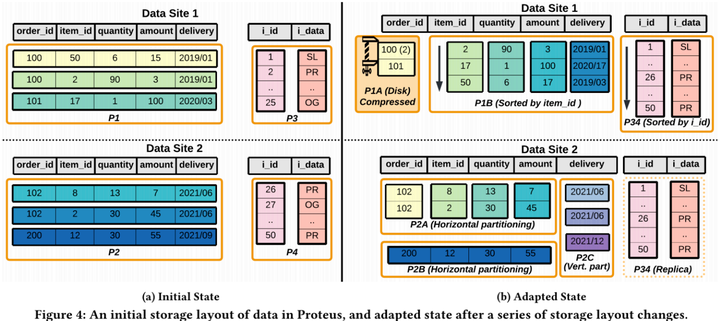
Abebe, Michael, Horatiu Lazu, and Khuzaima Daudjee. Proteus: Autonomous Adaptive Storage for Mixed Workloads. In SIGMOD, 2022.

HTAP的基准测试
下一期我们将介绍针对HTAP基准测试的相关进展,在我们的第二期学术分享会里,也介绍过来自慕尼黑工业大学(TMU)数据库组的研究,感兴趣可以前往查看,这篇文章只是其中一种基准测试的方法,想了解还有哪些方法么?欢迎关注StoneDB公众号,我下期见~
StoneDB 已经正式开源,欢迎关注我们 http://github.com/stoneatom/stonedb

官网:http://stonedb.io/
Github: http://github.com/stoneatom/stonedb
Slack: http://stonedb.slack.com/ssb/redirect#/shared-invite/email
- 为什么 MySQL 使用 B 树?| StoneDB数据库观察
- 带你来吃瓜!Andy Pavlo教授带您一文回顾数据库的2022年
- 哪篇论文宣布了 HTAP 数据库的诞生? | StoneDB学术分享会#5
- 列存引擎 Tianmu 如何实现 Delete?| StoneDB 研发分享 #3
- StoneDB 首席架构师李浩:如何选择一款 HTAP 产品?
- 如何给一个 HTAP 数据库做基准测试?| StoneDB学术分享会 #4
- StoneDB读写分离实践方案
- StoneDB 团队成员与 MySQL 之父 Monty 会面,共话未来数据库形态
- 爆肝整理5000字!HTAP的关键技术有哪些?| StoneDB学术分享会#3
- 爆肝整理5000字!HTAP的关键技术有哪些?| StoneDB学术分享会#3
- 解读《Benchmarking Hybrid OLTP&OLAP Database Systems》| StoneDB学术分享会
- 深度干货!一篇 Paper 带您读懂 HTAP | StoneDB 学术分享会第①期
- StoneDB 读、写操作的执行过程
- StoneDB 宣布开源,一体化实时 HTAP 架构为何是当前最优解
- 什么是真正的HTAP?(一)背景篇
- 什么是真正的HTAP?(一)背景篇
- 一体化实时HTAP数据库StoneDB,如何替换MySQL并实现近百倍分析性能的提升
- StoneDB 为国产数据库添砖加瓦,基于 MySQL 的一体化实时 HTAP 数据库正式开源!