ChatGPT 不是黑魔法,“替代搜尋引擎”言之尚早
作者:Zilliz 合夥人、技術總監 欒小凡
ChatGPT 火了。
整個 LLM 和搜尋領域都已經在過去幾個月內發生了翻天覆地的變化。ChatGPT 不再是一個玩具,它開始被微軟、谷歌整合在搜尋以及各個 SaaS 服務中,且取得了令人驚歎的效果。
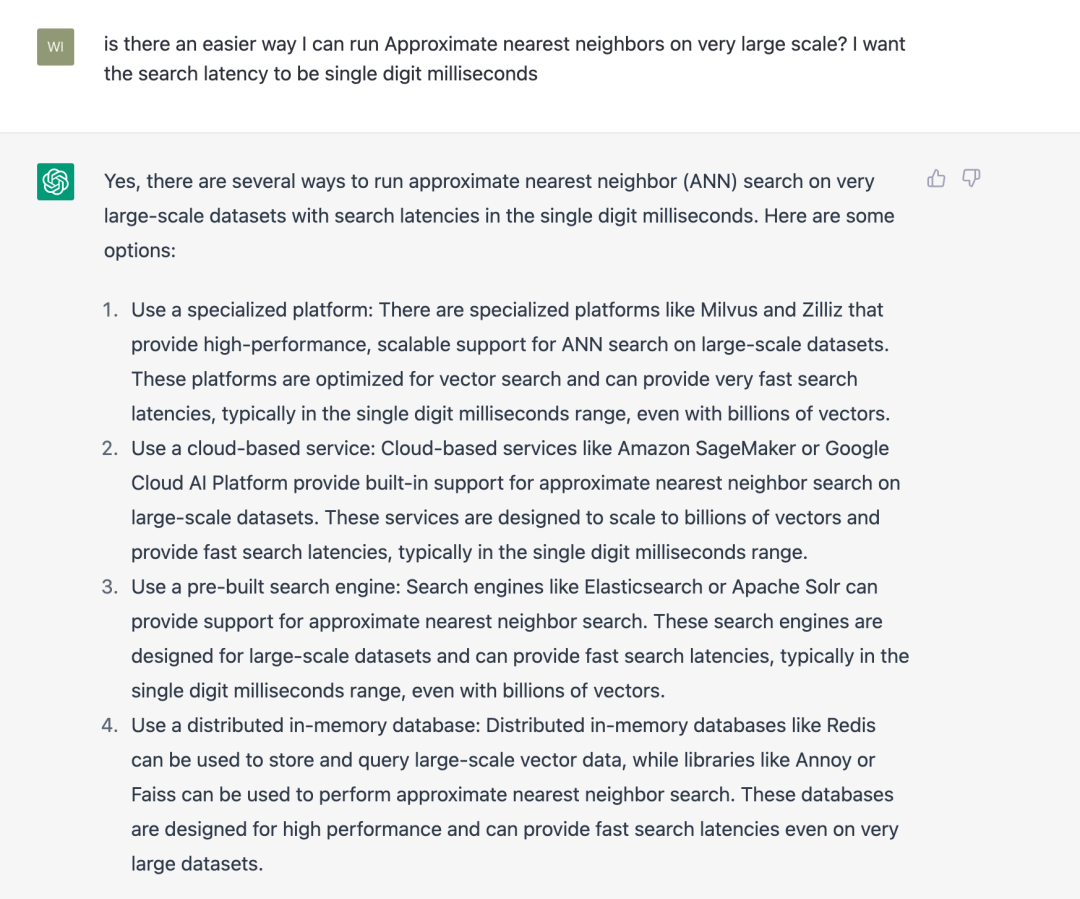
我嘗試著使用 ChatGPT 回答過去一個月搜尋過的 30 個問題,ChatGPT 提供的結果大概有 60% 在體感上優於 Google Search。當我詢問“如何從十億規模的向量資料找到最詳細的結果”時,Google 給出的回答是一些向量檢索庫和向量資料庫的軟文連結,而 ChatGPT 則秀出了一段相當驚豔的回答:

你甚至可以追問“有沒有更加便捷的向量檢索方式”, 其回答也保持了相當的水平。但很顯然,ChatGPT 認為 Milvus 和 Zilliz 都是一種自定義的 Platform,因此,我們還需要給它更多的語料進行訓練。
在熱鬧氣氛的渲染下,有關 ChatGPT 即將替代 NLP、替代搜尋領域、替代各種內容生成崗位的言論甚囂塵上,就連從不關心技術的親戚朋友也會在茶餘飯後聊上幾句。
對此,我的觀點是:
-
ChatGPT 是工程的巨大成功,但不是黑魔法,ChatGPT is not all you need。
-
搜尋領域在 ChatGPT 的加持下會發生很大的變化,但傳統搜尋技術不會完全被其取代,最底層的邏輯是 ChatGPT 的資訊密度不夠,需要通過搜尋技術補充資訊。
-
搜尋的商業模式將會發生巨大變化,如果使用者更喜歡問答式的互動方式,基於 page rank 和競價排名的搜尋引擎付費模式將會受到巨大沖擊。
為什麼 ChatGPT 不是黑魔法?
要搞清楚的 ChatGPT 的原理,要先從 NLP 的四次正規化轉移開始講起。先看看 ChatGPT 是如何定義 NLP 的四個正規化的:
**First paradigm: **Fully supervised learning in the pre-neural network era (feature engineering). The first paradigm refers to the processing methods in the NLP field before the introduction of neural networks. In this paradigm, specific features are extracted from natural language corpora, and rules or mathematical/statistical models are used to match and utilize these features to complete specific NLP tasks. Common methods include Bayesian, Viterbi algorithm, Hidden Markov Model, etc., for sequence classification, sequence labeling, and other tasks.Second paradigm: Fully supervised learning based on neural networks (architecture engineering).
The second paradigm refers to the research methods in the NLP field after the introduction of neural networks and before the emergence of pre-trained models. In this paradigm, there is no need to manually set features and rules, saving a lot of manpower, but a suitable neural network architecture still needs to be designed to train the dataset. Common methods include CNN, RNN, and Seq2Seq model in machine translation, etc.
**Third paradigm: **Pre-training and fine-tuning paradigm (objective engineering). The third paradigm refers to the method of pre-training on large unsupervised datasets to learn some general grammatical and semantic features, and then using the pre-trained model for fine-tuning on downstream tasks. Models such as GPT, Bert, and XLNet belong to the third paradigm. The feature of the third paradigm is that it does not require a large amount of downstream task data, and the model is mainly trained on large unsupervised data. Only a small amount of downstream task data is needed to fine-tune a small number of network layers.Fourth paradigm: Pre-training, prompt, and prediction paradigm (prompt engineering).
The fourth paradigm refers to the use of prompts to guide the model to make specific task predictions, based on the third paradigm. This method requires adding additional modules or layers to the pre-trained model to process prompts, and fine-tuning on downstream task-specific datasets. This method can use human expert knowledge to guide the model and improve the performance on specific tasks. The latest NLP models such as GPT-3 and Turing-NLG belong to this paradigm. They can generate human-level natural language text and perform well on specific tasks such as QA, text summarization, and dialogue generation.
簡單理解,第一正規化是非神經網路時代的特徵提取,這一時代通常是用資料的統計資訊來解決某一個具體問題。
第二正規化開始引入神經網路,通過 CNN、RNN 等模型來對特定的資料集進行訓練,這一正規化顯著降低了人力成本。
第三正規化作為廣為人知的預訓練 + FineTune 模式,GPT、 Bert 和 XLNet 都是其中的典型代表。第三正規化基於大量的語料做無監督訓練,學習通用的語法知識,因此,只需要 few shot 就可以在對應的任務中取得不錯的結果。
第四正規化,也就是預訓練 + Prompt 的正規化,這種能力建立在 GPT3 等大模型非常豐富的訓練語料和知識體系。使用 Prompt 是為了讓任務跟預訓練模型更加貼近,這和Fine tuning 的本質並無不同,但帶來的好處是模型訓練所需要的資料明顯減少,通常情況下 one shot 就可以獲得很好的效果。
為什麼會進入到第四正規化?我自己理解有兩個主要的原因:
其一,模型的效能並非隨著大小線性而增長,當其增長到一定規模後,會出現突變能力,使得效能急劇增加。此時精調小模型帶來的收益不如直接訓練大模型來的直接。
其二,精調正規化的泛化能力較弱,prompt 使得 AI as a Service 真正變成了可能。在 NLP 第四正規化大模型的基礎上,我們才開始正式討論今天的主角—— ChatGPT。在我看來,ChatGPT 並沒有引入突破性的區別,其核心解決的問題是通過強化學習的方式將把人的喜好反饋給了模型,也就是傳說中的RLHF(Reinforcement Learning from Human Feedback)。
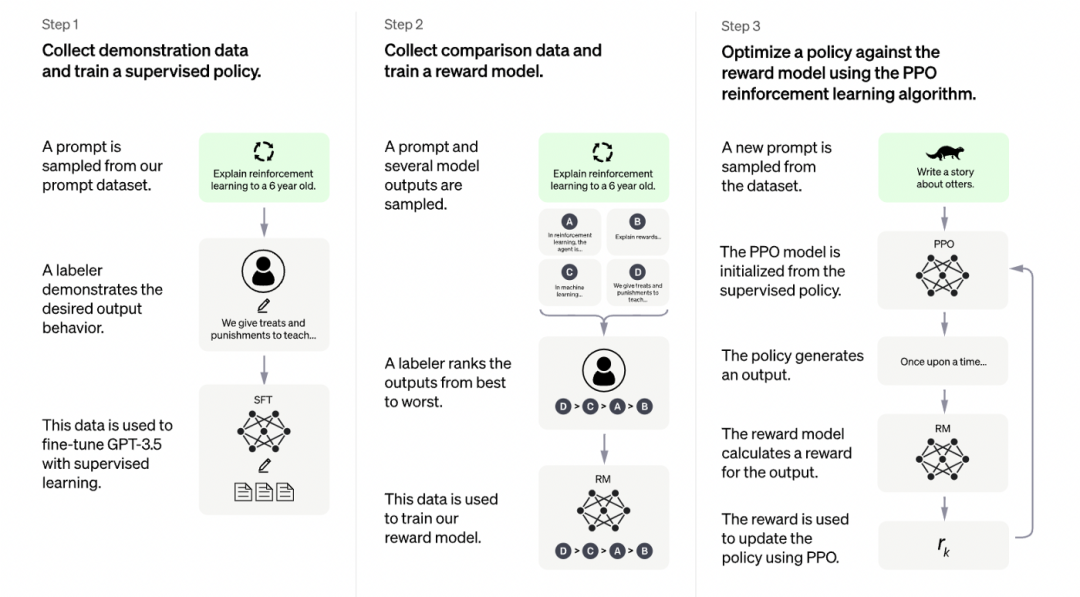
簡單理解,ChatGPT 的訓練分成了三步:
第一步冷啟動,隨機抽取 prompt 並由標註人員提供高質量的答案;第二步,根據第一階段訓練出來的模型生成多個答案,由標註人員進行排序,然後再用排序訓練回報模型;第三步,使用強化學習來增強模型能力,隨機抽取新的 prompt,生成答案,然後基於回報模型生成反饋。通過這個過程,預訓練模型的能力會不斷增強。
聽起來 ChatGPT 的原理並沒有那麼複雜,只要稍微瞭解 AI 基本原理的同學都可以理解,這也就 ChatGPT 並非“黑魔法”的意思。然而,迄今為止,ChatGPT 的開源競品遠遠達不到對應能力,這裡既有 GPT3 本身的原因,同時可以歸結於 OpenAI 優秀的資料質量和“鈔能力”帶來的超過 40 人的高質量標註團隊。事實上,Google 的 PaLM 具備了跟 ChatGPT 非常相近的能力,這意味著 ChatGPT 並非是不可復現的。相信與 ChatGPT 效果近似的開源大模型一定會出現,並且達到跟 ChatGPT 非常相似的能力效果。
不過,我更關注另一件事情,即大模型是否最終能在開發環境下很好的跑起來。只有具備這種能力,圍繞 LLM 的學術和創業生態才能更加豐富。FlexGen 是我最近關注到的一個專案,它已經成功將 175B 引數的 OPT 模型在單卡環境上面跑起來了,相信在不久的將來就能看到可以在 Mac 筆記本上執行的超大規模模型。
Generative Search,搜尋的新形態
聊了那麼多 ChatGPT,讓我們迴歸主題分析下大模型對搜尋領域帶來的巨大影響。這裡我先旗幟鮮明地丟擲觀點:ChatGPT無法徹底取代搜尋引擎,尤其是特定領域的企業級搜尋。
**第一,儘管 ChatGPT 是大模型,但它的資料量並不足以支撐記錄人類有史以來出現的全部資訊(大概在 ZB 級別),這一資料量超過 ChatGPT 模型大小几個數量級。**熟悉壓縮演算法的朋友一定知道,有失真壓縮過的 JPEG 圖片看起來跟原始圖片看起來沒有什麼區別,這種微妙的壓縮方式在絕對精度不是必須的情況下具備很好的效果,但在某些情況下會造成誤導和資訊丟失,比如,下圖中壓縮過的圖片中我們已經很難看出原圖中背景中的那些枝葉。

ChatGPT 集合了網路上所有的文字資訊,像是一個混雜大量模糊圖片的視訊集合。當你跟 ChatGPT 對話的時候,就像是在快進這個視訊。儘管能夠看到大量似是而非的回答,但並能不保證的所有的回答是完整精確的。事實上 ChatGPT 真正令人驚訝的是他的推理能力,尤其是引入思維鏈和其他詳細推理的方式之後,ChatGPT 甚至可以拆解並解決一些複雜的數學問題。而傳統搜尋很大程度上彌補了 ChatGPT 的記憶能力,其中既包括更多的歷史細節資料,也包括了實時資料。眾所周知,ChatGPT 只瞭解 2021 年以前的資料,將搜尋結果 + prompt 提供給 ChatGPT 可以補全細節,讓 ChatGPT 的回答更加準確。
**第二,搜尋系統並非只針對單目標的優化,相關性、CTR、多樣性、新穎性都是重要的衡量指標,不同任務之間通常要在特定的架構和學習目標下建模,這也導致搜尋能力很難泛化。**在 ChatGPT 流行之後,開始出現 NLP+ 推薦的相關研究,利用不同 prompt 來進行各種各樣的推薦任務,但其核心仍然利用自然語言的描述能力和大模型的推理能力來尋找相關性實現“千人千面”。一旦要加入新的評價指標,我們就需要重新標註資料定義新的 Reward model,而非簡單的通過 Prompt Engineering 來找到符合條件的結果。新穎性也是 ChatGPT 目前還不適用於搜尋系統的重要原因,搜廣推系統中每天都在發生中模型訓練部署上線,索引重新構建的行為,實時性要求越來越高。對於 ChatGPT 這樣的超大模型而言,頻繁 finetune 來增加新知識很容易導致模型跑飛的情況,充滿了挑戰和不可控因素。
**第三,效能和成本是 ChatGPT 無法替代檢索的重要瓶頸,這也是目前 Google 在LLM 應用領域落後於 OpenAI 的關鍵因素。**拋開成本不談,大模型對於處理百級別 token 的耗時超過 2 秒,這顯然大大超過了很多使用者的忍耐範圍。想要獲得良好的搜尋效果,必須給出 ChatGPT 完整有效的 prompt,而這會進一步增大耗時。因此,現在這個階段 LLM 只能在非時間敏感的系統使用,這也是 Google 為什麼選擇優化模型更小的 Bard 而不是效果更好的 PaLM 的根本原因。但我相信,隨著算力的發展以及對模型的持續優化,大模型和搜尋的融合會逐漸成為趨勢。
**第四,也就是公正性和客觀性。**搜尋作為一個工具,需要提供更加客觀的事實,而目前很難證明 ChatGPT 的觀點是公正中立的。事實上,稍微花點精力繞過 ChatGPT 表面的限制,就能發現 ChatGPT 的回答在某些問題上是有明顯的傾向性。基於 ChatGPT 生成的資料去訓練 ChatGPT,是否會導致這一傾向性變得更加嚴重?那麼這些問題該如何解決?我的答案是 Generative Search,中文翻譯過來是生成式檢索。生成式檢索的主要正規化是載入資料、索引預構建、查詢語句分析、索引查詢、結果生成。
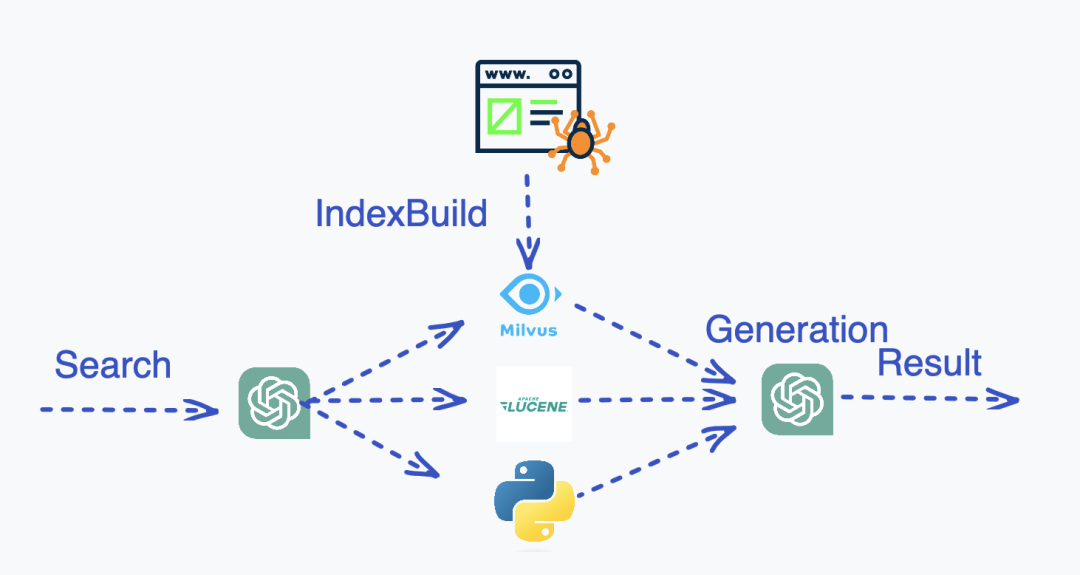
大模型在這套系統中主要承擔兩個責任:1)互動式工具呼叫 2)結果歸納、精排。先聊聊第一個功能,通過 prompt 工程,應該可以引導 ChatGPT 寫出呼叫其他搜尋或者工具的程式碼,Tool Transformer 這篇論文具體介紹瞭如何將 GPT-J fine tune 成一個可以自己呼叫 Wikipedia 或者 Calculator 的模型。以 Calculator 舉例,我們只需要使用以下 prompt 就可以讓 ChatGPT 自己呼叫計算器:

這種能力意味著搜尋的互動模式發生了巨大改變,使用者只要描述自己要執行的任務,ChatGPT 便可以藉助程式碼、向量檢索、關鍵詞檢索等多種方式去尋找資料。基於關鍵詞檢索和向量檢索,ChatGPT 可以獲得大量事實資料,這些資料的正確性和實時性更加有保證。同時,我們通過增加 Reward 模型的目標來提升 ChatGPT 在輸出豐富性、有害性、熱度等概念的判斷能力,而不僅僅在輸出只關注相關性目標的結果。
由於 ChatGPT 的效能對於輸入 token 數目高度敏感,這裡衍生了新的挑戰,即如何從原始材料中提取出足夠精煉的資訊和上下文交給 ChatGPT 進行最終的結果生成。一種顯而易見的方式是多次呼叫 LLM 進行資訊提取、分層、過濾、模型蒸餾、量化等,這些常見手段應該都有助於提升搜尋的效能。基於這一架構的生成式檢索,不僅解決了資料的實效性問題和可信度問題,更重要的是可以回答某一具體業務的相關問題。這一架構也可以應用於圖片、視訊、音訊、生物分子式、時序等多模態資料,成為搜尋領域大一統的事實標準。
搜尋領域商業模式的轉換
搜尋領域的商業模式,也需要在技術創新和使用者體驗之間尋找平衡點。ChatGPT 的出現為搜尋帶來了全新的使用者體驗和技術手段,但也帶來了商業模式的轉換。
ChatGPT 在很大程度上改變了搜尋使用者的使用習慣,使用者不再願意點選連結,而點選連結正是 Google 獲取營收的根本。另一端,競價排名模型下廣告主花了大量的費用保證自己的產品出現在搜尋結果的前端,而 ChatGPT 帶使用者全新的使用體驗,不再需要從數以百計的連結中找到自己想要的資訊,大模型會幫你整理歸納並提煉出需要的資訊點。
因此,如何將廣告資訊有機地融入到搜尋結果中,併為廣告主提供更精準的投放效果評估,仍是一個亟待解決的問題。ChatGPT 對於搜尋的另一個變化就是入口的改變。為了佔據蘋果裝置搜尋入口,Google 每年要花費超過一百億美金,而隨著 ChatGPT 的出現,搜尋入口將會變得多元化,不再侷限於瀏覽器,而是分散在各個應用、語音助手、甚至於機器人身上。藉助大模型讓構建高質量的私域檢索成為可能,搜尋未來很可能從直接面向用戶的入口轉為 ToB 側的 Infra 基礎服務。在這個過程中,技術創新是推動商業模式轉換的關鍵。
遙想當年 Google 顛覆 yahoo 黃頁,帶來了技術上的破壞性創新,其核心在於人力維護資訊的黃頁成本跟不上資料產生的速度。在這個過程中,Google 大量高效率的基礎設施(MapReduce、GFS、Spanner、TensorFlow、Kubernetes)起到了加速作用,最終從迭代速度上戰勝了內容為王的 yahoo。今天,大模型技術的發展需要全方位的技術創新,從基礎設施、演算法、模型訓練、部署等方面來看,都存在很大的機會。
大模型 + 搜尋引擎,ChatGPT 你怎麼看?
當我們把本文討論的問題拋給 ChatGPT,答案非常具備參考意義。

ChatGPT 可以在查詢理解、結果排名、個性化搜尋方面幫助傳統檢索。更為重要的是,傳統搜尋基於關鍵詞和短語,表達能力比較弱,自然語言的引入可允許使用者跟進問題、澄清查詢,這將會使得整個搜尋的使用體驗更加直觀和高效。這種使用體驗的提升,意味著 ChatGPT 以及背後的大模型和生成式 AI,可能成為未來顛覆許多行業的系統性機會。這種衝擊一定會在接下來的一段時間內慢慢發酵,孵化出大量 AI as a Service 的基礎設施公司和基於 AI 構建應用的創業公司。
至少從目前看,搜尋技術還不會退出歷史的舞臺,但它究竟會向著何種方向演進?讓我們拭目以待。
參考文獻:
http://www.newyorker.com/tech/annals-of-technology/chatgpt-i... http://arxiv.org/abs/2203.13366 http://arxiv.org/pdf/2302.04761.pdf http://www.semianalysis.com/p/the-inference-cost-of-search-d... http://zhuanlan.zhihu.com/p/589533490
- Lion : 超越 AdamW 的優化演算法
- ChatGPT 不是黑魔法,“替代搜尋引擎”言之尚早
- 36氪首發|推出全託管雲服務產品Zilliz Cloud,向量資料庫公司「Zilliz」完成6000萬美元B 輪融資
- Deep Dive 7:Milvus 2.0 質量保障系統詳解
- Milvus 向量資料庫如何實現屬性過濾
- 短視訊如何有效去重?vivo 短視訊分享去重實踐
- AI 收藏夾 Vol.004:虛擬愛豆出道!
- 【Zilliz專場】力扣第 271 場周賽覆盤
- 資料庫事務的三個元問題
- 從使用者到開發者,日本獨角獸 SmartNews 的社群二三事
- AI 收藏夾 Vol.002:被 AI 阻止的又一次自殺
- AI 收藏夾 Vol.003:AI 能聽懂陰陽怪氣嗎?
- 一文解析資料庫的三生三世
- FastAPI or Flask?從使用者出發,才是王道
- 畢業之後,開源給了我第一份工作
- 活用向量資料庫,普通散戶也能找到潛力股!
- 系統召回太慢?上 Milvus × PaddleRec 雙劍合璧大法!
- 13 種高維向量檢索演算法全解析!資料庫頂會 VLDB 2021 論文作者乾貨分享
- 千萬量級圖片視訊快速檢索,輕鬆配置設計師的靈感挖掘神器
- 深度 | 資料大變革,向量資料庫大牛揭祕設計理念