圖算法、圖數據庫在風控場景的應用

本文首發於 DataFunTalk 公眾號,授權 NebulaGraph 社區轉發。
導讀:本文將分享圖算法在風控中的應用。
今天的介紹會圍繞下面四點展開:
- 圖算法和風控簡介
- 圖算法在風控的演化
- 相應平台的心得
- 展望未來
分享嘉賓|汪浩然,互聯網行業資深風控和圖計算專家。
圖算法和風控簡介
什麼是圖算法——圖論算法
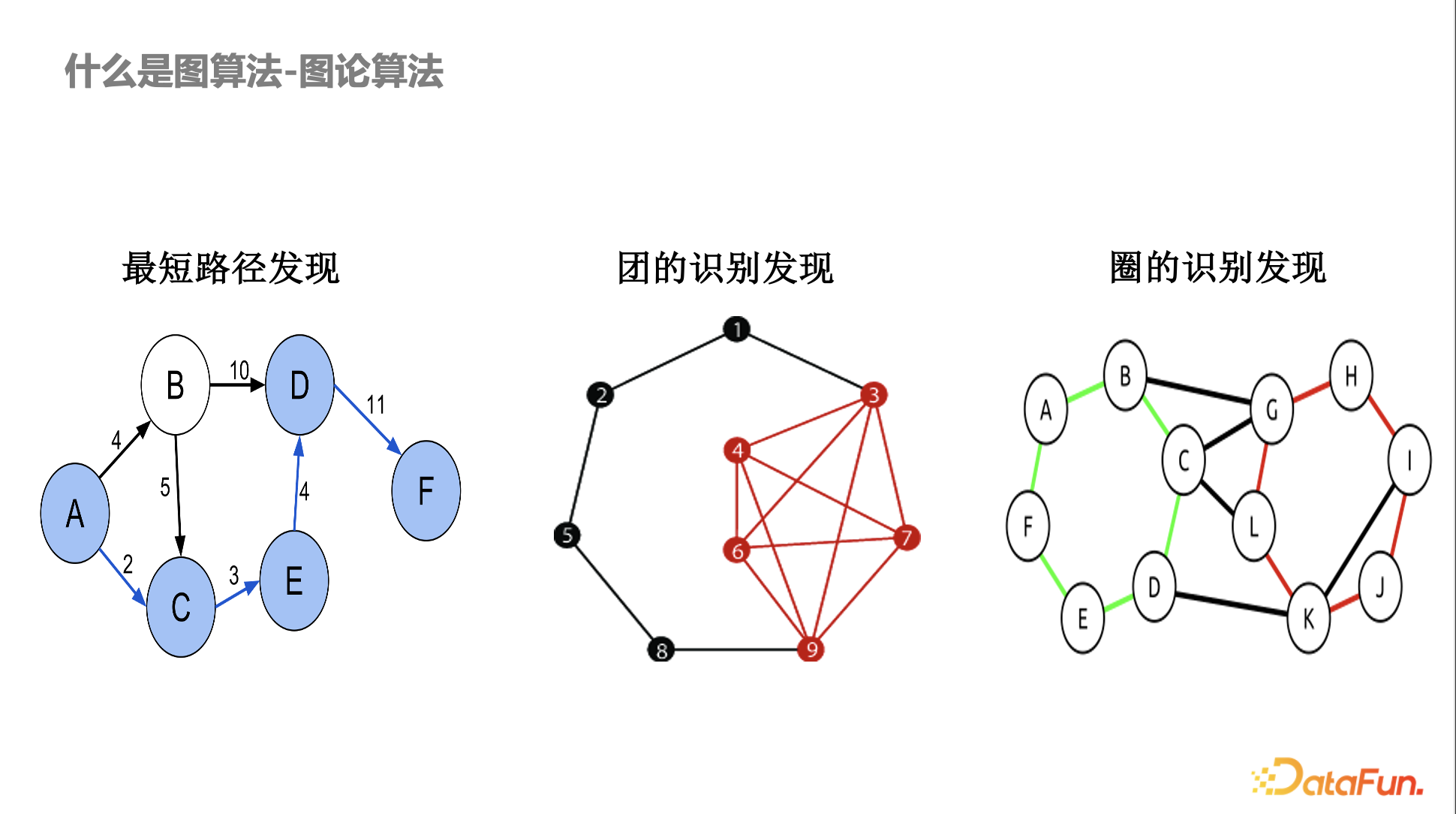
圖算法最早來源於圖論和組合優化相關算法,在風控裏面應用比較多的基本上都是傳統的圖算法或比較偏數學理論的算法,如最短路徑發現,不同的賬號和交易之間存在異常的最短路徑,某些賬號或設備存在異常的關聯。另外,還有圖的識別,比如洗錢,會涉及到異常的環路。
早期圖在風控的應用都是基於明確的數學結構定義,如果大家仔細研究這些算法,會發現有的算法是多項式時間可以解決的,有些是多項式時間無法解決的,比如 NP-hard 問題。在團或圈的發現算法中,其實會用到一些近似算法。而且風控中有意思的一點是數學上定義得越嚴格,黑產繞過就越容易。比如黑產知道你的目的是發現團,他會故意某幾個設備少一兩條邊,那數學嚴格的定義就很容易被繞過。
什麼是圖算法——圖機器學習
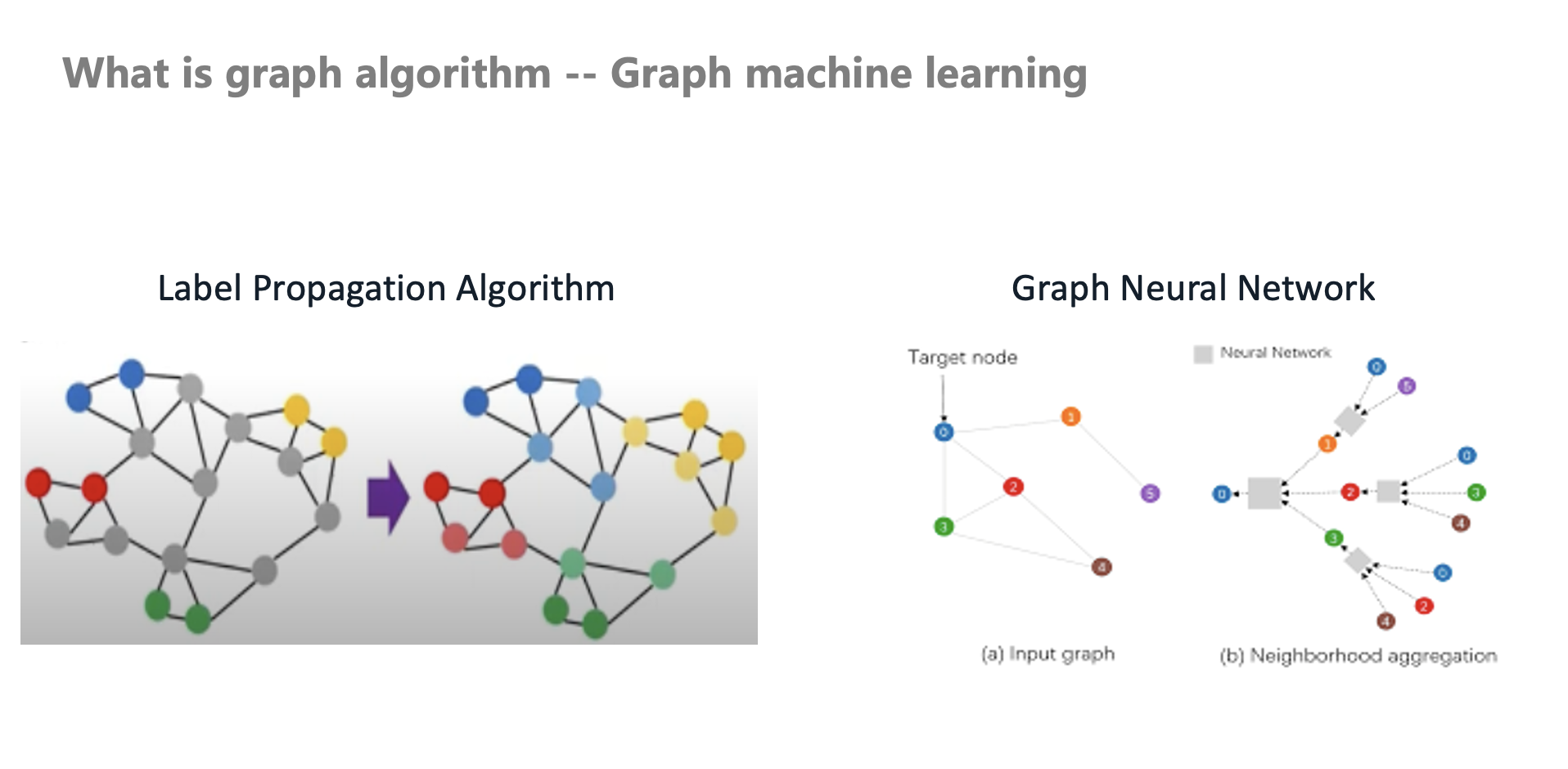
早期業內是直接應用這套傳統圖算法到風控中,隨着技術的發展,圖機器學習也開始應用在風控中。比如早期本人在交易場景中落地了一個標籤傳播算法,它是一個 Transudative 推演式的算法(非歸納式)。
在現實應用中,很多時候我們沒有辦法對黑白灰樣本去做完全精確的定位。那該如何利用類似社交網絡的同質性(好人和好人關係近,壞人和壞人關係近)做團伙識別?在風控場景,很容易通過強規則產出高準確率的樣本,但覆蓋率很低(低召回),那麼如何擴充這些樣本呢?
此時標籤傳播算法和半監督技術就開始在風控中使用。圖神經網絡的半監督學習,其學習能力和魯棒性高於傳統圖算法。有別於傳統的圖算法的自定義 Aggregate 和 Message Passing,隨着圖神經網絡的發展,也越來越多的應用到風控場景。
什麼是圖算法——圖挖掘算法

風控場景中使用到很多圖挖掘算法,如:
- 高密度子圖,一些異常賬號和異常行為對象之間會存在高密度子圖。
- 鄰居域異常,異常節點、邊、網絡存在異常的形狀(如星形散射狀),即該賬户的鄰居域異常。
- 複雜網絡,比如異常網絡的度分佈和正常網絡的度分佈是不同的。如有時挖掘了一些團伙,可以基於 Degree Sequence 構建特徵和模型。不同 Degree Sequence 分佈的網絡存在不同的特性,這可以指導我們進一步構建拓撲相關特徵。
什麼是風控

上圖中的台詞很好地概括了風控的工作,“人活一世,有的人成了面子,有的人成了裏子,都是時勢使然”。從事金融風控、交易風控,風控規則和算法是公司的核心競爭力,都需要保密。有很多精彩的算法及落地不方便出來交流,可能很少有人知道,但這都成了裏子。風控同學也是甘於寂寞,不斷地去進行各種對抗,同時也在鑽研技術和業務。
互聯網風控幹什麼

眾所周知的羊毛黨薅羊毛、賬户被盜、盜卡、現金貸、“以貸養貸”、貓池、惡意退貨、物流空包、各種各樣的詐騙、殺豬盤等等,這些場景都屬於互聯網風控範疇。
圖算法和風控的相遇

為什麼圖算法和風控會相遇?黑產作案存在團伙性,一個人不可能靠一個賬户就去作案,更多的時候需要多人多賬户的協同。
團伙特性就會使黑產之間產生關聯,這就引入了圖算法。作案有相似性,但案件和作案人之間可能沒有物理和空間關聯,但在某些角度他們存在相似性(如行為)。風控也可以通過除了直接的關係外的點和點之間的相似性構造邊。因為作案有相似性,這也是網絡可以存在的一個條件。
還有一個原因是作案需要大量的賬號和設備資源的配合,利益的驅動就會讓黑產做更多的事情。作案需要成本,如手機、賬號等。物以類聚,人以羣分(同質性)。
以上這些就是圖算法和風控相遇的原因。
圖算法在風控的演化
幾個核心趨勢

早年間風控尤其是風控策略,更多的是一個 Rule Writer。通過業務理解寫規則,慢慢演化成算法模型。還有從經典一階的 Velocity 變量變成了 Neutral Net Aggregator(後面會細講)。傳統的風控算法或規則只能看到相鄰點的特徵,現在可以通過神經網絡計算 Aggregator。這也是從數學嚴格定義的網絡結構到圖神經網絡、Strict Definition 到概率化的推斷的演進過程。
本人曾請教過圖靈獎得主 John Hopcroft,他在圖的匹配還有自動機方面做了很多工作。當時問他,傳統的圖算法的研究對現在的人工智能有沒有什麼幫助?首先他覺得是沒有的(可能是謙虛),他談到一個非常大的趨勢,過去大部分都是嚴格數學的定義,以後會更偏向概率推斷。這個趨勢也很契合風控,數學上定義得越嚴格,越容易被黑產攻克。使用機器學習、圖神經網絡去進行學習,最終就是變成了一個概率的推斷。
經典一階的 Velocity 變量
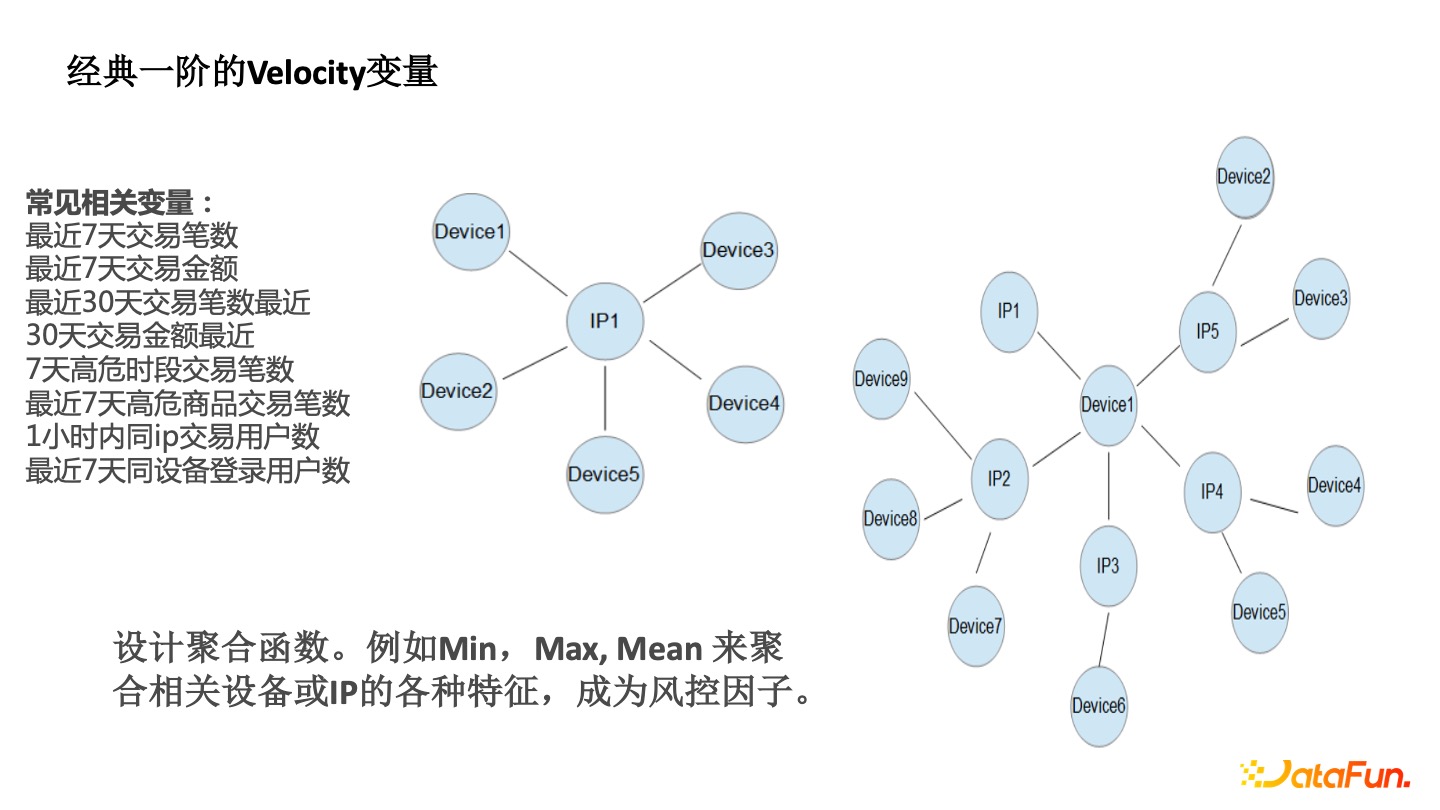
傳統的一階 Velocity 能看到一個 IP 周圍有很多的 Device 。要評估該IP 的風險,可以觀察其相鄰的 Device 的風險特徵,如最近幾天的交易登錄統計,最近 7 天的交易筆數,一小時內同 IP 的交易用户數等,這些都屬於一階 Velocity。
以前風控從業者相當於人工構建了圖神經網絡的 Aggregate 函數(Min、Max、Mean)。
- Min 函數,比如該 IP 周圍 Device 註冊的最小時間,如設備註冊最小時間都是最近的,即新設備,那麼該 IP 存在很大的風險。
- Max 函數,如設備上的最大的賬户數,多人共用單個設備也是異常。
- Mean 函數,如周圍的設備平均的交易數。之前風控從業者通過手工去設計這個一階的 Aggregate,通過圖算法能從一階到兩階。
神經網絡的聚合
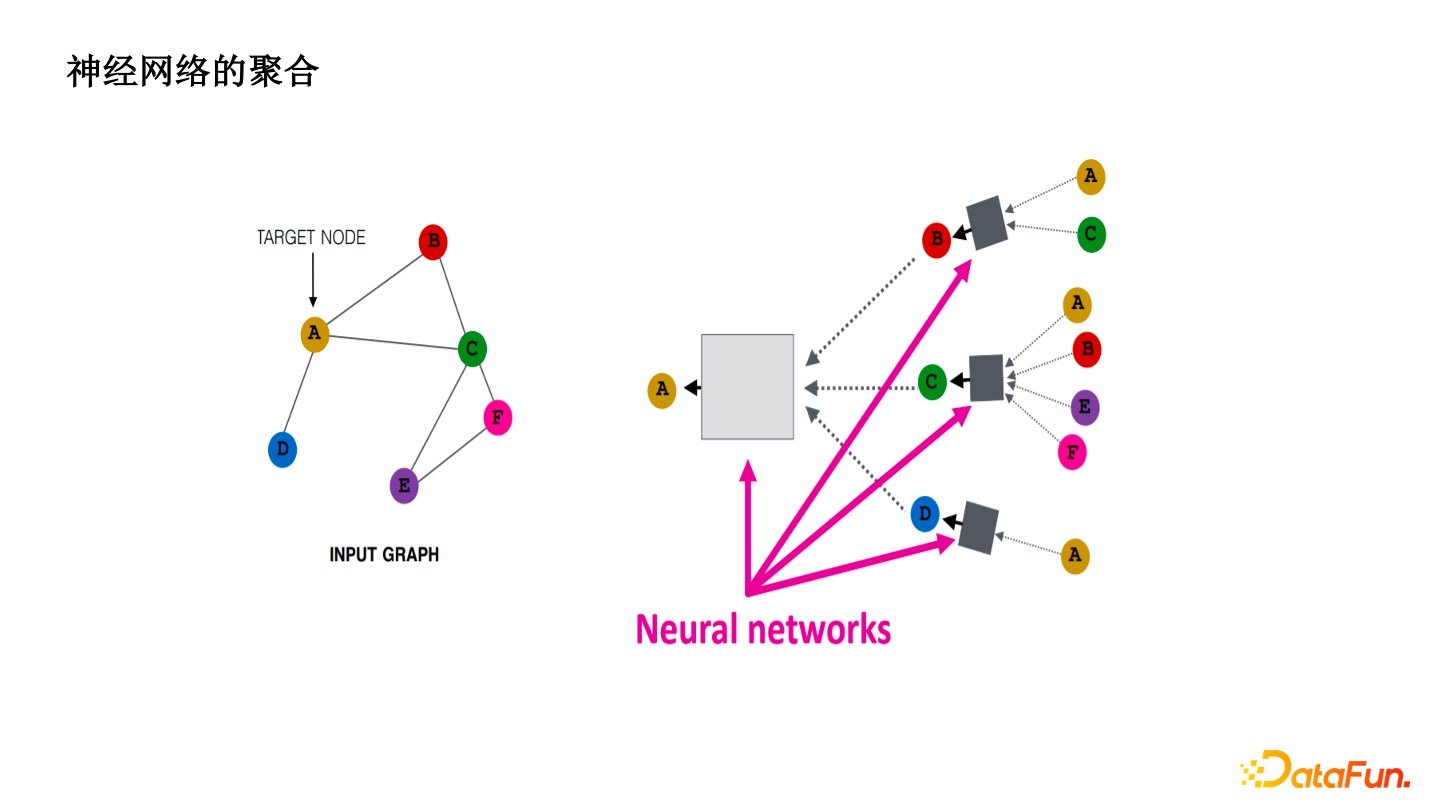
引入了神經網絡以後,把一階或者二階的 Velocity 通過神經網絡學習。讓算法去學壞人的 Pattern 而不是手工地去歸納,增加了繞過成本和模型的魯棒性。單純的一階的閾值很容易被黑產試出來,通過魯棒性的 MLP 去預測,有明顯的效果提升。
Aggregator 算子的突破

Aggregator 算子最核心的算法上的突破就是 Deepmind 實現的。它用了代數拓撲的概念,如一個節點的鄰居有 N 個點,每個都只有一個特徵,即 Size 是 N 的 Multi-Size,這時至少要 N 個 Aggregate 才能夠避免入射的產生。從算法上來講,GNN 如 GrapSAGE,Gat 等價於一階的 WL-test,本質上轉換成了同構圖的問題。同構就是讓不同的子圖確實能夠通過 Aggregate 函數不發生入射。
為解決這個問題,Deepmind 設計了一種新型的 Aggregator 算子, N 個 Moments 對應着 N 個 Aggregator 算子。後面加了一個 Scalers, 下面的 Sigma 相當於是整合度的總和。d 就是這個點的度,Alpha 是一個係數,Alpha 有 1 又有 -1。
在社交電商領域,基於人和人的推薦,有些商品實際上是適合劉耕宏這種度很大的人來推薦的,這時 Alpha=1。有些私密的商品適合你的閨蜜來向你推薦,此時 Alpha=-1。你們兩個度都很小,但你們兩個是有聯繫的,這樣推薦商品轉化率是很高的。
這些在社交電商的場景下去解釋是很合理的。最終通過從一階 Velocity 的規則到不同 Aggregate 聚合函數,再有 MLP,Scalers 對不同度的歸一化,再去使用 MLP,形成了整體框架。
相應平台的心得
早期一些 Velocity 很簡單,但是工程壓力大。要保證不同的特徵能對齊,還有時間窗口的計算也很複雜。比如風控的過程中,想實現時間衰減,昨天的累計和與今天的累計和加上不同的權重或者係數,都需要做很大的系統改造。我們需要站在更高的角度上去做風控的聚合算法和底層存儲索引系統,否則就是打補丁模式。
其實,實現難度也不大,用 DGL 都可以很輕鬆地去實現這樣的算子。
從算法角度來看,制約 GNN 學習能力的就是算子。不能變成另一種極端,複雜的框架和鏈路,用簡單的算子。如果算子非常簡單,就像四則混合運算,再怎麼組合,再怎麼搭積木,最後也就是四則混合運算,做不了微積分,又何談更高階的運算。
常用離線圖算法框架——GraphX

早期嘗試去做圖的時候,主要是做圖的最短路徑,單機版很簡單。在大廠數據量很大,會使用分佈式的圖學習。首先是思維的轉變,傳統的圖算法,都是 Sequency 的結構,很少有迭代式或者分佈式。在 Message Passing 的框架下,代表有阿里的 ODPS Graph、Spark GraphX,背後的框架都用的是谷歌的思想,第一次把圖算法的思路轉化成以點為中心,和周圍的點去做通信。
數學家説這是一種 local算法,怎麼通過 Local 的算法來產生一個全局的觀測?當所有的點都在做 Local 的時候,就變成分佈式了。
相對來説,阿里 ODPS Graph 實際上沒有很複雜的設計,但是它保證了只要 Work 足夠,總能算出結果。而且它是用 Java 開發,相對於 GraphX Scala 沒有做太多的封裝,可以自己去寫一些底層的函數。在實際的使用中,它並沒有很耗內存,GraphX 是非常耗內存的。如果要實現 Pre-K 框架這種 Message Passing 的傳統圖算法甚至圖標籤算法,ODPS Graph 是一個不錯的選擇。
騰訊高性能分佈式圖計算框架——Plato
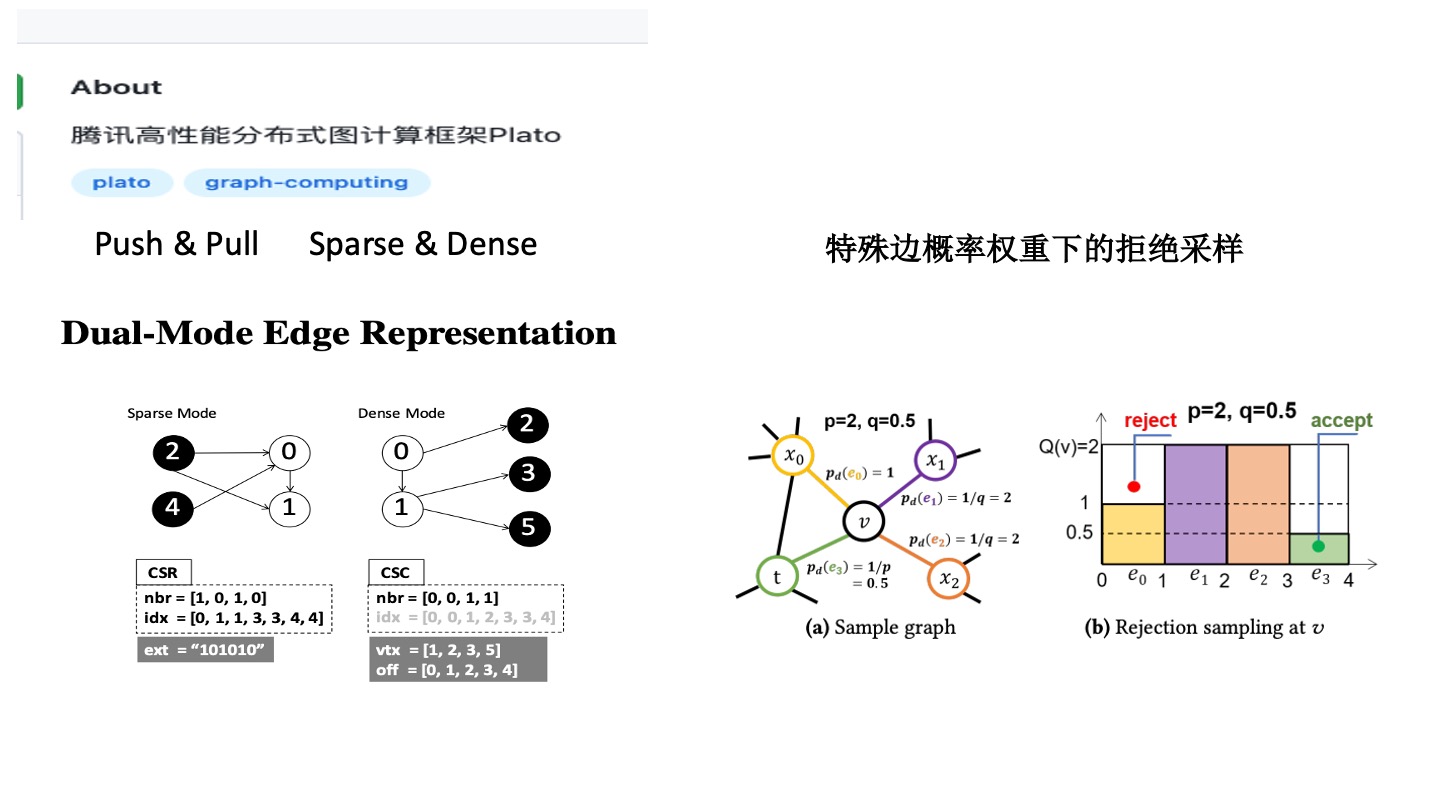
柏拉圖是對於圖論的算法以及 Degree 的分佈做了優化。目前大部分框架並沒有很強耦合,沒有要求圖的算法或分佈要滿足一定條件,更像是一種通用的分佈式的產品。
首先 Message Passing 有凝聚點的過程(push)和 Pull 過程(Push & Pull)。在這個過程中,大部分的算法有 Sparse 和 Dense 的演化過程。比如有些圖只有很少的點,如微信好友圈有些點只有很少的度,少部分點有很多的度,Push 階段這些點都是很稀疏的,接收的時候是很稠密的。
Sparse 和 Dense 雙引擎類似 CSR 和 CSC 傾向於列和行不同的壓縮模式。大部分 Message Passing 算法,只有小部分的點會經過很多輪的迭代才會收斂,大部分的點幾輪就會收斂。它是基於這種假設去設計的系統。
有時可能感覺它並沒有達到那麼好的效果,這其實與算法有關係。比如經典的 PageRank,早期谷歌在優化 PageRank 的時候,請了矩陣計算的大牛去完成優化。核心的優化點就是觀察到大部分的點經歷了幾步以後就已經收斂了,只有少部分的點要很多輪。基於這個洞察,讓一些點停止,不再跟周圍的點進行更新。這隻有利用到 Sparse 和 Dense 特性才可以實現。使用該系統的時候,如果不去深入研究系統原理,最終效果可能都不太理想,這個還和圖結構有關係。QQ 的圖與微信的圖是不一樣的。不同的算法在不同的圖上,不同的目的,它的 Sparse 和 Dense 的表現也是不一樣的。這需要算法去了解底層框架。
這個系統還有一個亮點,實現了特殊偏概率權重下的拒絕採樣。
拒絕採樣是動態的,如 Node2Vec 的算法,P 和 Q 的參數是來調整節點更傾向於深搜還是廣搜。它使用了一種抽樣方法去實現,比較適合 Node2Vec 算法。Node2Vec 每個邊概率的權重是有上限的,P 和 Q 的權重決定了面積的大小,那麼它就適合。此時做蒙特卡洛隨機採樣的時候,確實是能夠看到效果的提升。但如果使用動態權重的話,就會出現一些凝聚點和高峯。比如走到一個熱點(明星點),會有一些高峯誕生,周圍的點就很塌。此時會發現拒絕採樣要多走好多輪才可能會落到 R 中,效果反而不好。針對 Node2Vec 這種每個偏概率權重有上限的情況,確實是能夠很好地優化,對於通用的情況可能就會出現很差的效果。這時候需要算法同學選擇合適的框架去做,也需要算法同學非常瞭解應用算法和系統算法的原理,做到上下貫通。
騰訊 Angel 圖計算框架
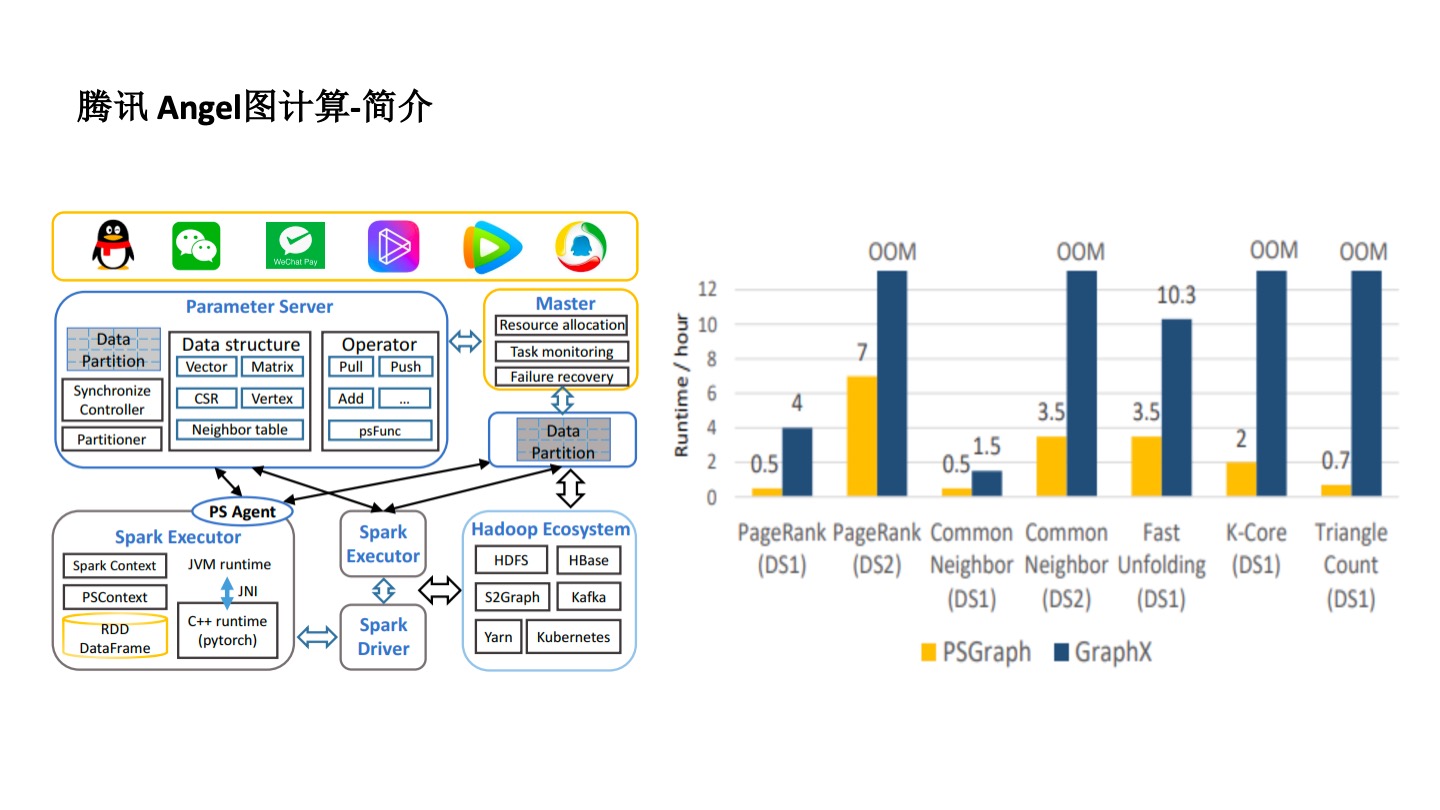
騰訊 Angle 圖計算平台在有些地方很好用,但也存在一些瓶頸。
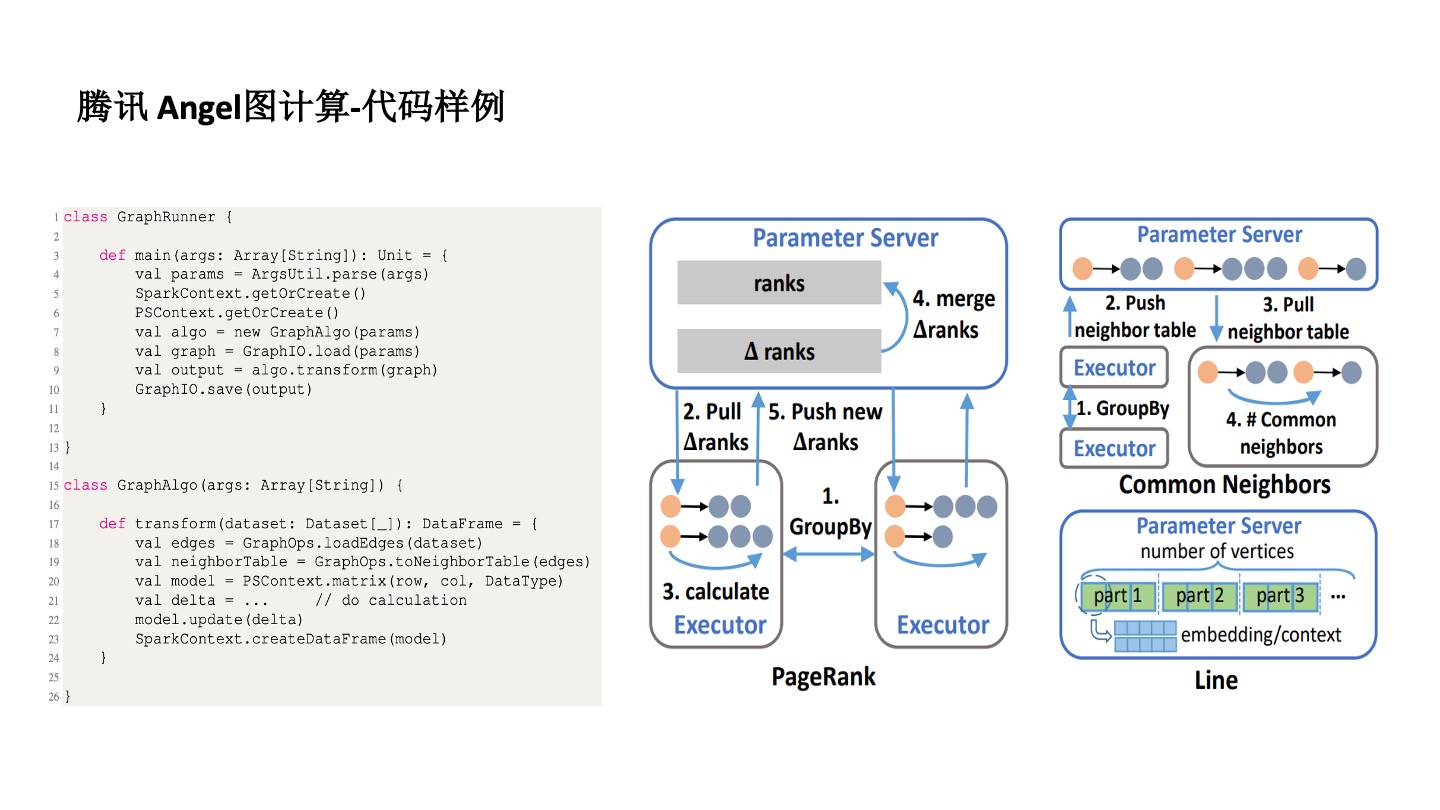
首先,圖很難實現分佈式及分佈式管理。為了解決這個問題,Angel 用了 Parameter Server 框架去實現。對於不同的算法,比如 PageRank 要把每個點的向量作為參數存起來,然後再進行分佈式計算。在分佈式計算的時候,採用了 Spark 計算的原理,一個 Spark 程序有很多的 Executor 來實現分佈式計算。也從某種程度上解決了算法同學編程難的問題。
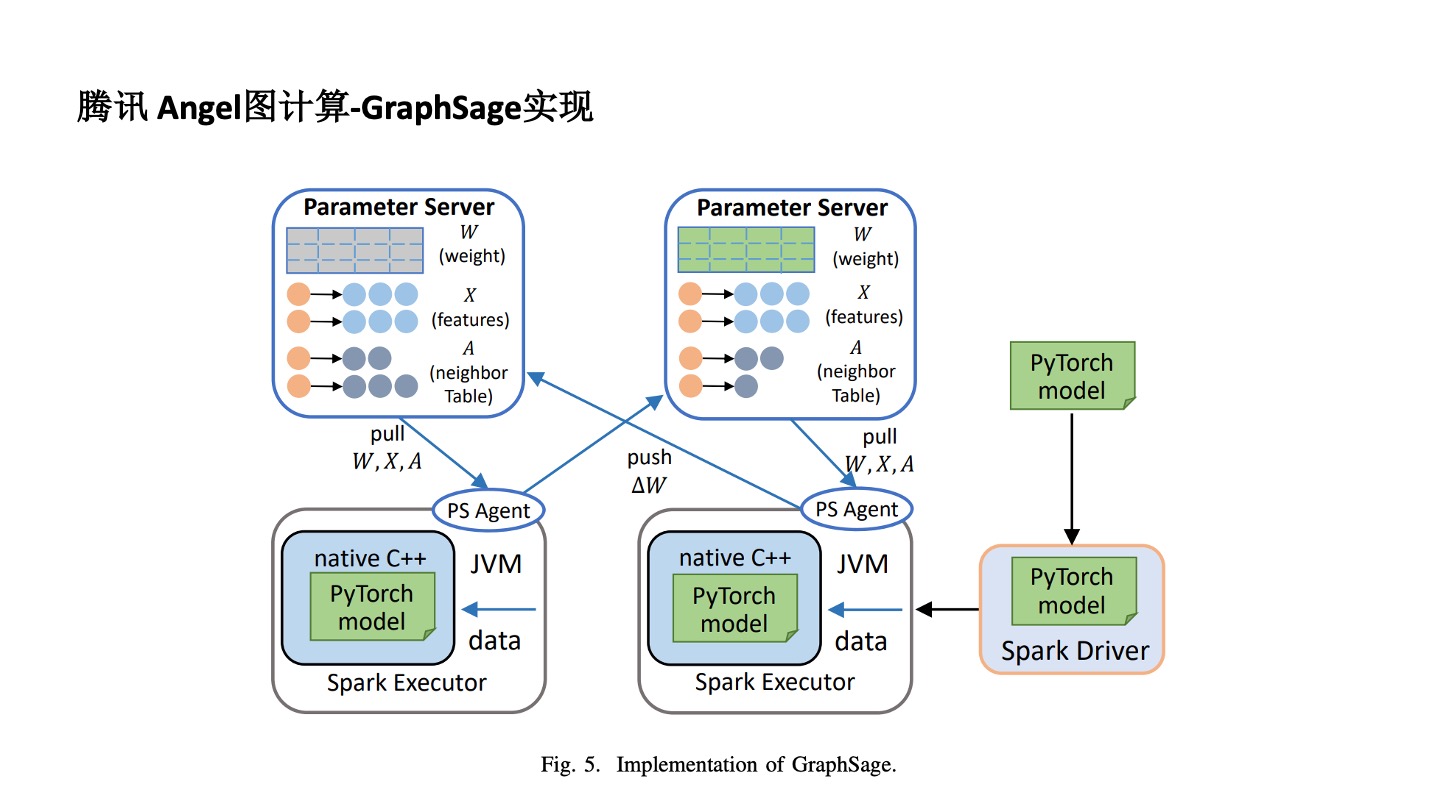
Angel 針對 GraphSAGE 改一下是能夠實現的。比如通過把連接節點放在 Parameter Survey 中實現分佈式,再通過 C++& PyTorch 的 Model JVM 技術,使用 Spark Execute 方式實現分佈式。這是一個更通用的計算平台,不同的圖算法,不管是圖神經網絡還是特定圖模式的發現都可以實現。
開源圖數據庫——NebulaGraph
近幾年,開源圖數據庫生態正在日益完善,NebulaGraph 的開源圖數據庫在社區中已經有很多的文章。早期算法同學需要自己實在 Flink 框架實現數據同步,NebulaGraph 提供了 Connector 組件可以去實現。風控要做大量的案件和觀點的分析,有這種可視化的平台很方便。但是,從工程的角度,還有很多運維的事情。不管是在數據鏈路,跟流數據 Flink 還是離線數據 Spark 的打通上,跟圖算法的打通,以及可視化分析,在運維上都已經有比較成熟的解決方案。
線上實時模型查詢推理系統

金融支付防範實時風險可以用大廠的開源工具去實現。比如使用 DGL 實現模型實時推理;離線模型使用社區、交易數據訓練,產生模型文件。
線上實時推理時,NebulaGraph 拿到實時文件去獲得子圖。Amazon SageMaker 這樣的 Online 的 Inference 還是很好用的。自己去寫一些腳本, query 圖、解析圖、導入圖,再打通變成風控上的 UDF。隨着 DGL 的進步和 NebulaGraph 的進步,一般獨角獸公司 SageMaker 肯定是夠用的。
從算法出發,反而能給到工程和設計更多幫助。比如要問 SageMaker 留一個腳本的口子的好處是什麼,是要寫死還是留給算法同學,可能需要不同類型的人去參與到圖平台和框架的建設中去。如果不能成為風控、推薦中的一個特徵或者因子,平台再好也沒有多少價值,不會有更多的資源投入,也不會真正在工業界發揮作用。
DGL-Message Passing 角度優化
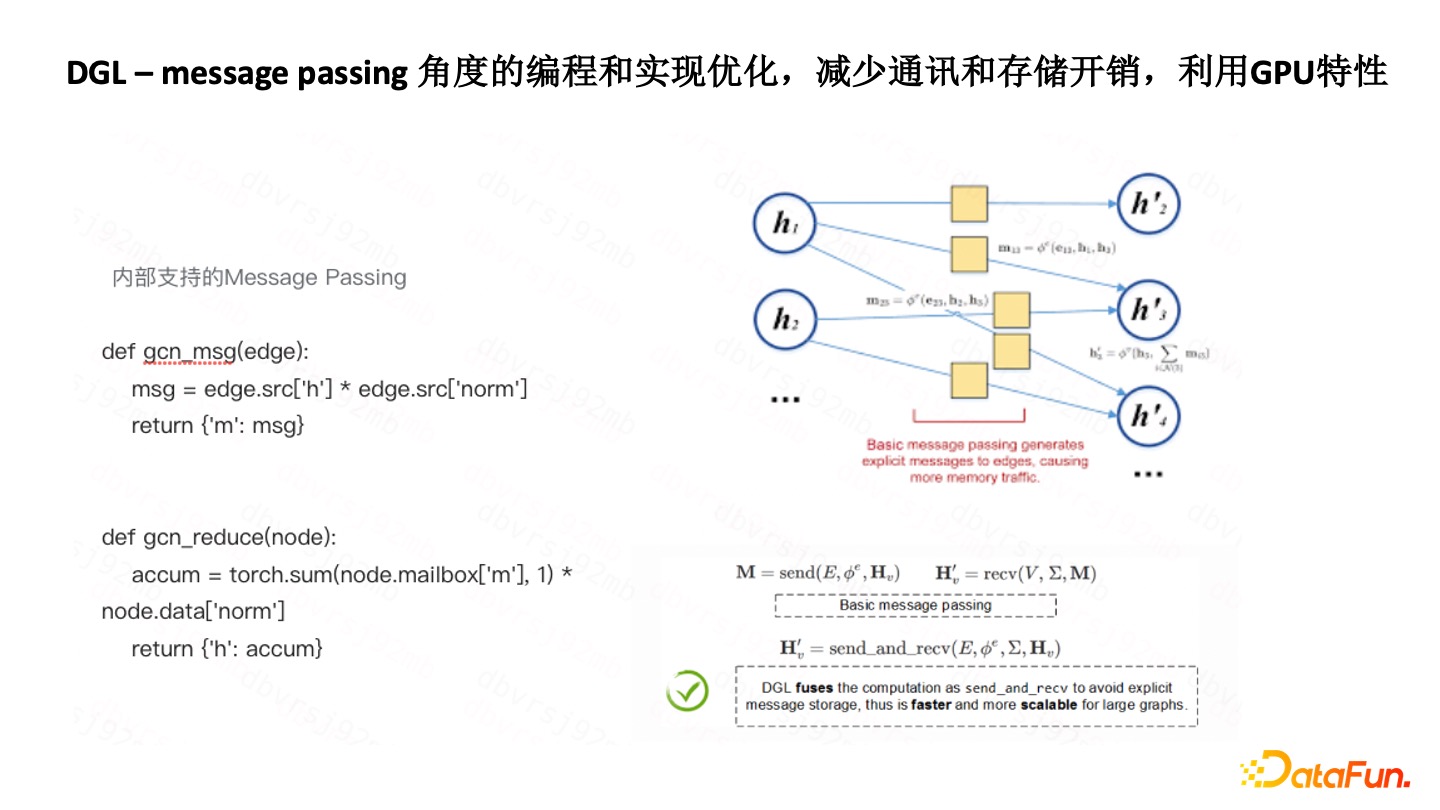
DGL 的 Message Passing 的封裝做得比較好。比如用 DGL 去開發標籤傳播,比用 ODPS Graph 去開發,速度快了很多,效率很高,因為它把 Message Passing 函數、聚合函數都做了封裝,能夠快速實現各種各樣的標籤傳播算法。
DGL 的底層也做了一些優化。因為基於 Spark,有一個問題就是 Aggregate 到 Send 過程會有很多額外的通訊和存儲的開銷。優化的方式是把該過程變成了矩陣的計算,然後再用到 GPU 優化的特性去完成,所以編程難度有所降低,效率上有很大的提高。

另外,有時圖本身並不複雜,GPU 很長時間在等待。現在的做法是,把更多的計算放到 GPU 中。去年黃仁勛在英偉達大會中也談了 GPU 對 DGL 的推動。當然在工業界,與敏捷有一些差別。敏捷是更往下走,希望能封裝成更底層的一些神經網絡的算子,而我們是希望往上封裝,提高對一線算法同學的易用性。

我們自己做了一個 DGL-Adapter,以突破內存限制,用少量的通信成本的犧牲,換取更大的圖數據規模的訓練能力。這是一個分佈式的框架,有 Client和 Server 去獲取圖數據,再把不同的 Batch 分發給不同的 Worker ,不同的 Worker 有了反饋結果,採樣的結果再返回過來進行計算。
展望未來
最後展望一下未來。長期的趨勢是要從算法層面、平台層面、系統層面去改進。
圖算法和圖神經網絡算法的融合
現在很多團隊在談 GNN,但有時並不能説清 GNN 到底學到了什麼東西,解釋能力有多強。圖的傳統算法也不能放,因為不同的互聯網公司、社區等等,都有不同的網絡結構。我們要基於這些網絡結構有一些洞察。比如是否需要和圖神經網絡,和 Data Mining 結合。在風控的特定場景下,還要對圖的特定 Pattern 去進行挖掘。比如 Angel 支持在 Parameter Server 框架的基礎上加 Spark,DGL 又開了一個 Message Parsing 的口子,只要是能夠變成 Message Parsing 框架的圖算法,就都是可以實現的。首先,算法同學在一線要知道如何融合,才能跟中台團隊框架團隊去合作。
圖神經網絡算法學習能力的攻克
學習能力的攻克,包括基本算子的不斷突破非常重要,否則光是四則混合運算,再怎麼組合其本身學習能力就不夠。
圖神經網絡算法魯棒性
風控很多時候是對抗,並不知道會有什麼樣的攻擊方式,因此要提高算法魯棒性。
圖神經網絡算法可解釋性
無論是推薦還是風控,現實中制約落地的很多時候是一個可解釋性的問題。
平台易用性和整合性
平台易用,用起來流程快,才能更快地實現各種算法的迭代。
應用算法和系統算法上下融合貫通和統籌
在建設圖計算平台的時候,要真的懂業務和應用算法,實際用户也要懂系統算法層面,整體上需要上下打通和統籌。
一線算法、平台算法和中台等各個團隊需要加強合作,也需要學術界和工業界一起努力。
問答環節
Q1:風控場景中,它有這種事前事中和事後這種圖模型。在這些三種不同的場景的話,它的圖模型分別是如何來應用的?
A1:可能以前我們對算法和系統的發展沒有那麼好的時候,會分得比較清楚,事前事中事後,但是現在發展得更快,尤其我前面説的那個框架,就圖數據庫的完善,DGL 以及類似 SageMaker 完善了以後,實時模型也不像以前那麼難了,所以它在應用的時候更多的還是從數據和特徵角度一方面要去考慮。在事前事中事後拿到的數據不一樣是可以容忍的,計算量是不一樣的。可能在事前算法不會那麼複雜。比如一個新用户的數據本身是有限的,那這時候去做事後就可以上一些更加複雜的算法。一個人比如説今天來了就要判斷他是壞人還是他在這裏表現了 30 天是壞人?兩者難度是不一樣的,在算法的複雜度特徵上是會不一樣的。
Q2:在風控場景中有遇到圖模型的可解釋性問題嗎?怎麼解決?
A2:這個其實是很有意思的問題。圖模型的解釋性,其實説句實話比其他模型要容易的。為什麼?因為圖算法在風控為什麼用得那麼好?它有個強大的圖的可視化能力。把不同的團伙可視化出來,一目瞭然。通過可視化來展示你的算法,主要就發現幾種模式,一看就知道是批量註冊。也可以通過動態圖的演化,有一夥人在遷移。這方面大家可以多用一些圖可視化的技術去形象化地把你發現東西總結出來。這是最快的。你也可以嘗試着去實現一個 GNN Explain。這裏可能有些坑,因為 GNN 本身是一個優化問題,一般的機器學習都是無約束的,優化之後怎麼去處理?可以弄一個近似 GNN Explainer 就大概知道到底學到了什麼。不知道你學到了什麼東西,其實也很難去進一步調整圖神經網絡,然後可能還要用一些觀察。個人建議大家可以找一些學術合作伙伴,對於明天的方法,後天的方法也可以讓學術界的朋友來看一看,就是説如何能夠定量地去對 GNN Explainer 做一些突破,這些都可以。
Q3:圖算法的魯棒性,有哪些方法去度量?
A3:這個分一種學術上或者技術上嚴格意義的。這個度量是指改變了點和邊的一些特性以後,其結果的變化,那就是一些面子上的或者是最基本的。在風控場景下的所謂魯棒性的攻擊,我總結下來就可能,點是真的,邊是假的或者點是假的,邊是真的。比如説今天別人偽造 IP 隨便輸了個 IP 來腳本攻擊,那 IP 可能是真的,但邊是假的?那有可能今天偽造了一個東西,這個點就是假的,所以有幾種可能性。作為風控來説,可以嘗試這幾種不同的可能性去對你的模型進行攻擊。因為現在對於風控來説比較缺的就是領域內的 Cost 和 Attacks。Attacks 有時候是未知的,黑產有時候用你不知道的方法,但是 Cost 可能是知道。在 Cost 和 Attacks 部分知道的情況下怎麼去定義模型的魯棒性,我覺得這個可能是對風控來説比較有價值的一個研究方向。
今天的分享就到這裏,謝謝大家。
分享嘉賓
汪浩然,互聯網行業資深風控和圖計算專家。英國碩士,曾在螞蟻金服,阿里巴巴,騰訊等公司主要從事風控算法,社交計算和圖計算等工作,橫跨金融,支付,電商,供應鏈,社區,社交等場景。率先工業界落地過諸多圖上挖掘和機器學習算法,有算法百曉生和掃地僧之稱。
謝謝你讀完本文 (///▽///)
一起用 NebulaGraph Cloud 來搭建自己的圖數據系統,節省大量的部署安裝時間來搞定業務吧~ NebulaGraph 阿里雲計算巢現 30 天免費使用中,點擊鏈接來用用圖數據庫吧~
想看源碼的小夥伴可以前往 GitHub 閲讀、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流圖數據庫技術和應用技能,留下「你的名片」一起玩耍呢~
- 圖數據庫在中國移動金融風控的落地應用
- 記一次 rr 和硬件斷點解決內存踩踏問題
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網絡應用
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網絡應用
- 圖數據庫中的“分佈式”和“數據切分”(切圖)
- 揭祕可視化圖探索工具 NebulaGraph Explore 是如何實現圖計算的
- 連接微信羣、Slack 和 GitHub:社區開放溝通的基礎設施搭建
- 圖數據庫認證考試 NGCP 錯題解析 vol.02:這 10 道題竟無一人全部答對
- 如何判斷多賬號是同一個人?用圖技術搞定 ID Mapping
- 複雜場景下圖數據庫的 OLTP 與 OLAP 融合實踐
- 如何運維多集羣數據庫?58 同城 NebulaGraph Database 運維實踐
- 有了 ETL 數據神器 dbt,表數據秒變 NebulaGraph 中的圖數據
- 基於圖的下一代入侵檢測系統
- 從實測出發,掌握 NebulaGraph Exchange 性能最大化的祕密
- 讀 NebulaGraph源碼 | 查詢語句 LOOKUP 的一生
- 當雲原生網關遇上圖數據庫,NebulaGraph 的 APISIX 最佳實踐
- 從全球頂級數據庫大會 SIGMOD 看數據庫發展趨勢
- 「實操」結合圖數據庫、圖算法、機器學習、GNN 實現一個推薦系統
- 如何輕鬆做數據治理?開源技術棧告訴你答案
- 圖算法、圖數據庫在風控場景的應用