在位元組跳動,一個更好的企業級SparkSQL Server這麼做

SparkSQL是Spark生態系統中非常重要的元件。面向企業級服務時,SparkSQL存在易用性較差的問題,導致難滿足日常的業務開發需求。本文將詳細解讀,如何通過構建SparkSQL伺服器實現使用效率提升和使用門檻降低。
前言
Spark 元件由於其較好的容錯與故障恢復機制,在企業的長時作業中使用的非常廣泛,而SparkSQL又是使用Spark元件中最為常用的一種方式。
相比直接使用程式設計式的方式操作Spark的RDD或者DataFrame的API,SparkSQL可直接輸入SQL對資料進行ETL等工作的處理,極大提升了易用度。但是相比Hive等引擎來說,由於SparkSQL缺乏一個類似Hive Server2的SQL伺服器,導致SparkSQL在易用性上比不上Hive。
很多時候,SparkSQL只能將自身SQL作業打包成一個Jar,進行spark-submit命令提交,因而大大降低Spark的易用性。除此之外,還可使用周邊工具,如Livy,但Livy更像一個Spark 伺服器,而不是SparkSQL伺服器,因此無法支援類似BI工具或者JDBC這樣的標準介面進行訪問。
雖然Spark 提供Spark Thrift Server,但是Spark Thrift Server的侷限非常多,幾乎很難滿足日常的業務開發需求,具體的分析請檢視:觀點|SparkSQL在企業級數倉建設的優勢
標準的JDBC介面
Java.sql包下定義了使用Java訪問儲存介質的所有介面,但是並沒有具體的實現,也就是說JavaEE裡面僅僅定義了使用Java訪問儲存介質的標準流程,具體的實現需要依靠周邊的第三方服務實現。
例如,訪問MySQL的mysql-connector-java啟動包,即基於java.sql包下定義的介面,實現瞭如何去連線MySQL的流程,在程式碼中只需要通過如下的程式碼方式:
Class.forName("com.mysql.cj.jdbc.Driver");Connection connection= DriverManager.getConnection(DB_URL,USER,PASS);//操作connection.close();第一,初始化驅動、建立連線,第二,基於連線進行對資料的操作,例如增刪改查。可以看到在Java定義的標準介面訪問中,先建立一個connection完成儲存介質,然後完成connection後續操作。
效能問題導致單次請求實時建立connection的效能較差。因此我們往往通過維護一個存有多個connection的連線池,將connection的建立與使用分開以提升效能,因而也衍生出很多資料庫連線池,例如C3P0,DBCP等。
Hive 的JDBC實現
構建SparkSQL伺服器最好的方式是用如上Java介面,且大資料生態下行業已有標杆例子,即Hive Server2。Hive Server2在遵循Java JDBC介面規範上,通過對資料操作的方式,實現了訪問Hive服務。除此之外,Hive Server2在實現上,與MySQL等關係型資料稍有不同。
首先,Hive Server2本身是提供了一系列RPC介面,具體的介面定義在org.apache.hive.service.rpc.thrift包下的TCLIService.Iface中,部分介面如下:
public TOpenSessionResp OpenSession(TOpenSessionReq req) throws org.apache.thrift.TException;
public TCloseSessionResp CloseSession(TCloseSessionReq req) throws org.apache.thrift.TException;
public TGetInfoResp GetInfo(TGetInfoReq req) throws org.apache.thrift.TException;
public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;
public TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req) throws org.apache.thrift.TException;
public TGetCatalogsResp GetCatalogs(TGetCatalogsReq req) throws org.apache.thrift.TException;
public TGetSchemasResp GetSchemas(TGetSchemasReq req) throws org.apache.thrift.TException;
public TGetTablesResp GetTables(TGetTablesReq req) throws org.apache.thrift.TException;
public TGetTableTypesResp GetTableTypes(TGetTableTypesReq req) throws org.apache.thrift.TException;
public TGetColumnsResp GetColumns(TGetColumnsReq req) throws org.apache.thrift.TException;也就是說,Hive Server2的每一個請求都是獨立的,並且是通過引數的方式將操作和認證資訊傳遞。Hive 提供了一個JDBC的驅動實現,通過如下的依賴便可引入:
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>version/version></dependency>在HiveConnection類中實現了將Java中定義的SQL訪問介面轉化為呼叫Hive Server2的RPC介面的實現,並且擴充了一部分Java定義中缺乏的能力,例如實時的日誌獲取。但是使用該能力時,需要將對應的實現類轉換為Hive的實現類,例如:
HiveStatement hiveStatement = (HiveStatement) connection.createStatement();List<String> logs = hiveStatement.getQueryLog();Log獲取也需呼叫FetchResult介面,通過不同的引數來區分獲取Log資訊還是獲取內容資訊,因此,Hive JDBC封裝的呼叫Hive Server2 RPC介面流程是:

如果該流程觸發獲取MetaData、獲取Functions等操作,則會呼叫其他介面,其中身份資訊即token,是用THandleIdentifier類進行封裝。在OpenSession時,由Hive Server2生成並且返回,後續所有介面都會附帶傳遞這個資訊,此資訊是一次Connection連線的唯一標誌。
但是,Hive Server2在FetchResults方法中存在bug。由於Hive Server2沒有很好處理hasMoreRows欄位,導致Hive JDBC 客戶端並未通過hasMoreRows欄位去判斷是否還有下一頁,而是通過返回的List是否為空來判斷。因此,相比Mysql Driver等驅動,Hive會多發起一次請求,直到返回List為空則停止獲取下一頁,對應的客戶端的JDBC程式碼是:
ResultSet rs = hiveStatement.executeQuery(sql);while (rs.next()) { // }即Hive JDBC實現next方法是通過返回的List是否為空來退出while迴圈。
構建SparkSQL伺服器
介紹了JDBC介面知識與Hive的JDBC知識後,如果要構建一個SparkSQL伺服器,那麼這個伺服器需要有以下幾個特點:
-
支援JDBC介面,即通過Java 的JDBC標準進行訪問,可以較好與周邊生態進行整合且降低使用門檻。
-
相容Hive協議,如果要支援JDBC介面,那麼需要提供SparkSQL的JDBC Driver。目前,大資料領域Hive Server2提供的Hive-JDBC-Driver已經被廣泛使用,從遷移成本來說最好的方式就是保持Hive的使用方式不變,只需要換個埠就行,也就是可以通過Hive的JDBC Driver直接訪問SparkSQL伺服器。
-
支援多租戶,以及類似使用者名稱+密碼和Kerberos等常見的使用者認證能力。
-
支援跨佇列提交,同時支援在JDBC的引數裡面配置Spark的相關作業引數,例如Driver Memory,Execute Number等。
這裡還有一個問題需要考慮,即使用者通過SparkSQL伺服器提交的是一段SQL程式碼,而SparkSQL在執行時需要向Yarn提交Jar。那麼,如何實現SQL到Jar提交轉換?
一個最簡單的方式是,使用者每提交一個SQL就執行一次spark-submit命令,將結果儲存再快取,提供給客戶端。還有更好方式,即提交一個常駐的Spark 作業,這個作業是一個常駐任務,作業會開啟一個埠,用來接收使用者的SQL進行執行,並且儲存。
但是為了解決類似Spark Thrift Server的問題,作業需要和使用者進行繫結,而不是隨著Spark的元件啟動進行繫結,即作業的提交以及接收哪個使用者的請求,均來自於使用者的行為觸發。
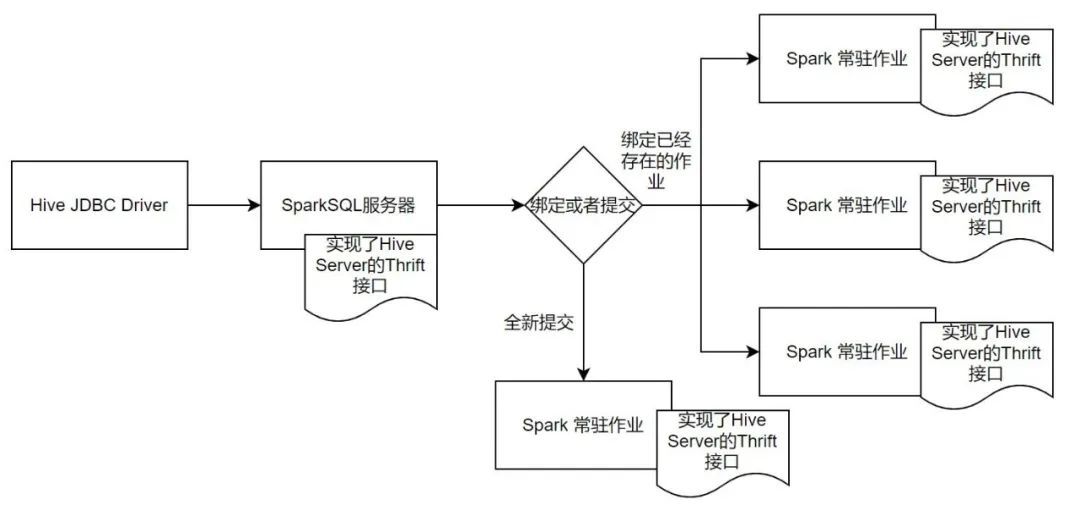
有了這樣幾個大的方向後,便可以開始開發SparkSQL伺服器。首先需要實現TCLIService.Iface下的所有介面,下面用程式碼+註釋的方式來講述這些Thrift介面的含義,以及如果實現一個SparkSQL伺服器,需要在這些介面做什麼內容:
public class SparkSQLThriftServer implements TCLIService.Iface {
@Override
public TOpenSessionResp OpenSession(TOpenSessionReq req) throws TException {
//Hive JDBC Driver在執行建立Connection的時候會呼叫此介面,在這裡維護一個使用者與Spark 作業的對應關係。
//來判斷是需要複用一個已經存在的Spark作業,還是全新執行一次spark-submt。
//使用者與是否需要spark-submit的關聯關係均在這裡實現。
//同時需要生成THandleIdentifier物件,並且和使用者身份進行關聯,後續其他方法呼叫均需要使用這個物件關聯出使用者的資訊。
return null;
}
@Override
public TCloseSessionResp CloseSession(TCloseSessionReq req) throws TException {
//客戶端呼叫connection.close()方法後會進入到這裡,在這裡進行使用者狀態的清除,同時需要基於使用者的情況判斷是否需要停止用來執行該使用者SQL的Spark 作業引擎。
return null;
}
@Override
public TGetInfoResp GetInfo(TGetInfoReq req) throws TException {
//獲取伺服器的元資料資訊,例如使用BI工具,在命令會列出所連線的服務的版本號等資訊,均由此方法提供。
return null;
}
@Override
public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws TException {
//執行SQL任務,這裡傳遞過來的是使用者在客戶端提交的SQL作業,接收到使用者SQL後,將該SQL傳送給常駐的Spark作業,這個常駐的作業在OpenSession的時候已經確定。
return null;
}
@Override
public TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req) throws TException {
//獲取資料庫支援的型別資訊,使用BI工具,例如beeline的時候會呼叫到這裡。
return null;
}
@Override
public TGetCatalogsResp GetCatalogs(TGetCatalogsReq req) throws TException {
//獲取Catalog,使用BI工具,例如beeline的時候會呼叫到這裡。
return null;
}
@Override
public TFetchResultsResp FetchResults(TFetchResultsReq req) throws TException {
//返回查詢結果,基於THandleIdentifier物件查詢到使用者的SQL執行的情況,將請求轉發至常駐的Spark 例項,獲取結果。
//引數中通過TFetchResultsReq的getFetchType來區分是獲取日誌資料還是查詢結果資料,getFetchType == 1為獲取Log,為0是查詢資料查詢結果。
return null;
}
}
我們採用複用當前生態的方式,來實現相容Hive JDBC Driver的伺服器。有了上面的Thrift介面實現後,則需要啟動一個Thrift服務,例如:
TThreadPoolServer.Args thriftArgs = new TThreadPoolServer.Args(serverTransport)
.processorFactory(new TProcessorFactory(this))
.transportFactory(new TSaslServerTransport.Factory())
.protocolFactory(new TBinaryProtocol.Factory())
.inputProtocolFactory(
new TBinaryProtocol.Factory(
true,
true,
10000,
10000
)
)
.requestTimeout(1000L)
.requestTimeoutUnit(TimeUnit.MILLISECONDS)
.beBackoffSlotLengthUnit(TimeUnit.MILLISECONDS)
.executorService(executorService);
thriftArgs
.executorService(
new ThreadPoolExecutor(
config.getMinWorkerThreads(),
config.getMaxWorkerThreads(),
config.getKeepAliveTime(),
TimeUnit.SECONDS, new SynchronousQueue<>()));
TThreadPoolServer server = new TThreadPoolServer(thriftArgs);
server.serve();
至此便開發了一個支援Hive JDBC Driver訪問的伺服器,並且在這個伺服器的方法中,實現了對Spark 作業的管理。後續,還需要開發預設Spark Jar,Jar同樣實現瞭如上介面,只是該作業的實現是實際執行使用者的SQL。
經過前面的流程,已經完成一個可以工作SparkSQL伺服器開發,擁有接收使用者請求,執行SQL,並且返回結果的能力。但如何做的更加細緻?例如,如何實現跨佇列的提交、如何實現使用者細粒度的資源管理、如何維護多個Spark 作業的連線池,我們接下來會講到。
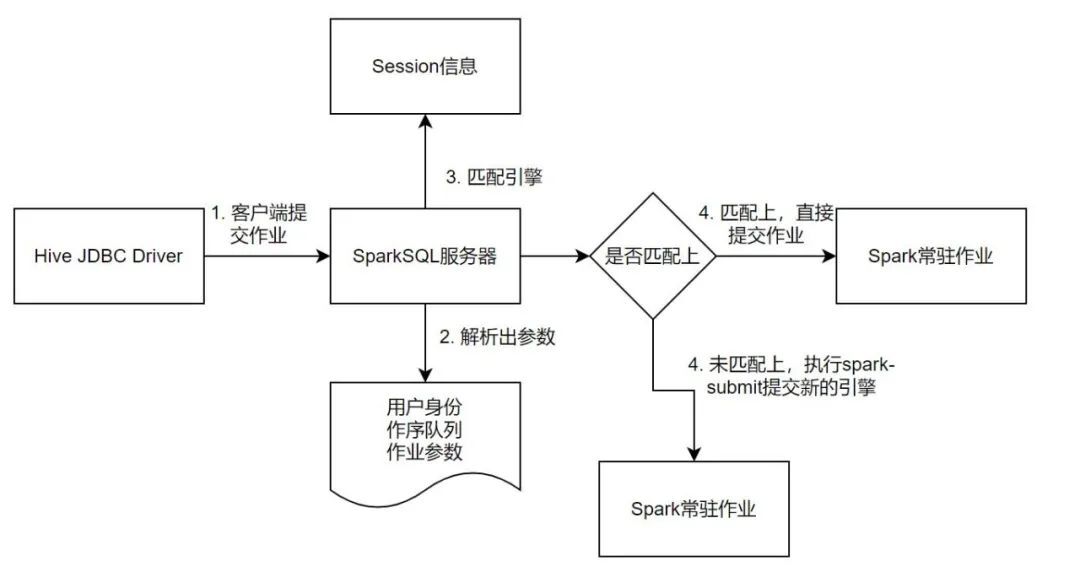
由於對於Spark作業在Yarn上的提交,執行,停止均由SparkSQL伺服器管理,對使用者是不可見的,使用者只需要編寫標準的JDBC程式碼即可,因此可以基於使用者的引數資訊來匹配合適的引擎去執行,同時還可以限制一個Spark 常駐作業的任務個數,實現更加靈活的SparkSQL作業的管理,同時也可以實現類似C3P0連線池的思想,維護一個使用者資訊到Spark常駐作業的關聯池。
SparkSQL伺服器的HA
Hive Server2在啟動的時候會將自己的伺服器資訊寫入Zookeeper中,結構體如下所示:
[zk: localhost:2181(CONNECTED) 1] ls /hiveserver2\[serverUri=127.0.01:10000;version=3.1.2;sequence=0000000000]當連線HA模式下的伺服器的時候,Hive JDBC Driver的URL需要切換成zookeeper的地址,Hive JDBC Driver會從多個地址中隨機選擇一個,作為該Connection的地址,在整個Connection中均會使用該地址。
因此對於我們實現的SparkSQL伺服器,只需要在伺服器啟動的時候,保持與Hive一致的資料格式,將自己的伺服器的地址資訊寫入到Zookeeper中即可,便可通過標準的zk地址進行訪問,例如:
./bin/beeline -u "jdbc:hive2://127.0.01/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=自定義的節點;auth=LDAP" -n 使用者名稱 -p密碼由於伺服器的選擇基於Connection級別的,也就是在Connection被生成新的之前,整個伺服器的地址是不會發生變化的,在發生錯誤的時候服務端可以進行重試,進行地址的切換,因此HA的力度是在Connection級別而非請求級別。
對接生態工具
完成以上開發之後,即可實現在大部分的場景下,使用標準的Hive驅動只需要切換一個埠號。特別提到Hue工具,由於和Hive的整合並未使用標準的JDBC介面,而是直接分開呼叫的Hive Server2的Thrift介面,也就是Hue自行維護來如何訪問Thrift的介面的順序問題。
可以發現在這樣的情況會有一個問題就是對於Hue來說,並沒有Connection的概念,正常的SparkSQL在JDBC的互動方式下處理流程是:
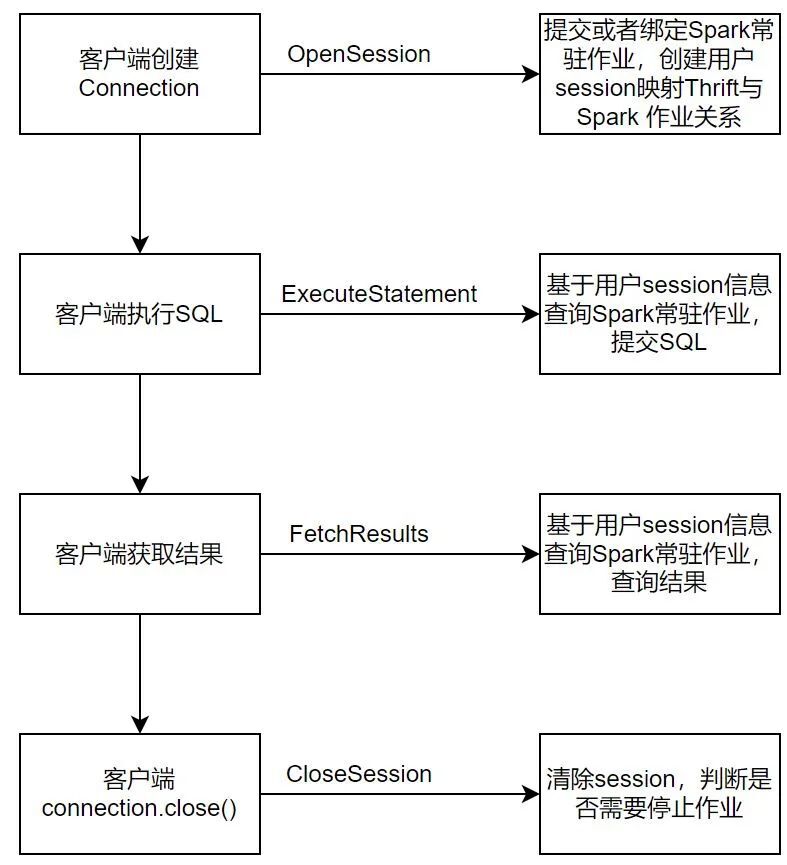
由於Hue沒有Connection概念,因此Hue的請求並不會先到OpenSession,而是直接發起ExecuteStatement。由於沒有上下文資訊,正常流程下ExecuteStatement處接收到Hue的請求會發現該請求為非法,所以OpenSession不能作為連線的起點,而是需要在每一個Thrift介面處實現OpenSession的能力,以此作為上下文初始化。
尾聲
SparkSQL在企業中的使用比重越來越大,而有一個更好用的SQL伺服器,則會大大提升使用效率和降低使用門檻。目前,SparkSQL在伺服器這方面的能力顯然不如Hive Server2提供的更加標準,所以各個企業均可基於自身情況,選擇是否需要開發一個合適於自身的SparkSQL伺服器。
本文所提到的相關能力已通過火山引擎EMR產品向外部企業開放。結合位元組跳動內部以及外部客戶的需求情況,火山引擎EMR產品的Ksana for SparkSQL提供一個生產可用的SparkSQL伺服器,並且在Spark 效能方面也做了較大的優化,本文主要圍繞技術實現的角度來闡述如何實現一個SparkSQL服務,後續會有更多文章講述其他相關的優化。
產品介紹
火山引擎 E-MapReduce
支援構建開源Hadoop生態的企業級大資料分析系統,完全相容開源,提供 Hadoop、Spark、Hive、Flink整合和管理,幫助使用者輕鬆完成企業大資料平臺的構建,降低運維門檻,快速形成大資料分析能力。
更多技術交流、求職機會、試用福利,歡迎關注位元組跳動資料平臺微信公眾號,回覆【1】進入官方交流群
- 位元組跳動資料平臺技術揭祕:基於ClickHouse的複雜查詢實現與優化
- 位元組跳動一站式資料治理解決方案及平臺架構
- 以位元組跳動內部 Data Catalog 架構升級為例聊業務系統的效能優化
- 實時資料湖在位元組跳動的實踐
- 基線監控:基於依賴關係的全鏈路智慧監控報警
- UniqueMergeTree:支援實時更新刪除的 ClickHouse 表引擎
- 乾貨 | 難對齊、難保障、難管理?一文了解位元組跳動如何解決資料SLA治理難題
- 在位元組跳動,一個更好的企業級SparkSQL Server這麼做
- 位元組跳動構建Data Catalog資料目錄系統的實踐
- 基於 Feature Flag 的下一代開發模式
- 從玄學走向科學:在位元組跳動廣告投放這麼幹
- 位元組跳動基於 Apache Hudi 的多流拼接實踐方案
- 位元組跳動流式資料整合基於Flink Checkpoint兩階段提交的實踐和優化
- 揭祕位元組跳動雲原生Spark History 服務 UIService
- 為什麼在資料驅動的路上,AB 實驗值得信賴?
- Hudi Bucket Index 在位元組跳動的設計與實踐
- 來看看位元組跳動內部的資料血緣用例與設計
- 看 SparkSQL 如何支撐企業級數倉
- ClickHouse 在 UBA 系統中的字典編碼優化實踐
- 位元組跳動資料湖技術選型的思考與落地實踐