MMOCR使用指南
MMOCR是通用視覺框架OpenMMLab的光學字符識別器。
安裝配置環境
MMOCR github主頁:GitHub - open-mmlab/mmocr: OpenMMLab Text Detection, Recognition and Understanding Toolbox
pip install mmcv-full -f http://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
pip install mmdet -i http://pypi.tuna.tsinghua.edu.cn/simple
pip install lmdb
pip install shapely
pip install rapidfuzz
pip install lanms
pip install pyclipper
pip install scikit-image
pip install imgaug
驗證是否安裝成功代碼
import torch, torchvision
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
import mmdet
import mmocr
from mmocr.utils.ocr import MMOCR
mmocr = MMOCR(det=None, recog='SAR', device='cpu')
print('mmocr載入成功')文本檢測與文本提取
import torch, torchvision
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
import mmdet
import mmocr
from mmocr.utils.ocr import MMOCR
# mmocr = MMOCR(det=None, recog='SAR', device='cpu')
# print('mmocr載入成功')
if __name__ == '__main__':
detector = MMOCR(det='TextSnake', recog='SAR', device='cuda')
result = detector.readtext('demo/demo_densetext_det.jpg', output='output/demo_densetext_det.jpg')文字分類
import torch, torchvision
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
import mmdet
import mmocr
from mmocr.utils.ocr import MMOCR
# mmocr = MMOCR(det=None, recog='SAR', device='cpu')
# print('mmocr載入成功')
if __name__ == '__main__':
detector = MMOCR(det='TextSnake', recog='SAR', kie='SDMGR', device='cuda')
result = detector.readtext('data/wildreceipt/image_files/Image_1/0/0ea337776eb4a57010accaf2814ea7351770819b.jpeg', output='output/0ea337776eb4a57010accaf2814ea7351770819b.jpeg')
print(result[0]['text'])中文檢測與提取
在mmocr主目錄下新建文件夾/data/chineseocr/labels
進入該文件夾執行
wget http://download.openmmlab.com/mmocr/textrecog/sar/dict_printed_chinese_english_digits.txt
wget http://download.openmmlab.com/mmocr/data/font.TTF
下載字體和字庫
import torch, torchvision
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
import mmdet
import mmocr
from mmocr.utils.ocr import MMOCR
# mmocr = MMOCR(det=None, recog='SAR', device='cpu')
# print('mmocr載入成功')
if __name__ == '__main__':
detector = MMOCR(det='TextSnake', recog='SAR_CN', device='cuda')
result = detector.readtext('demo/demo_densetext_det.jpg', output='output/demo_densetext_det.jpg')模型訓練
Kaggle驗證碼文本識別
數據集下載地址:CAPTCHA Images | Kaggle
下載完成後,將samples文件夾下的圖片放入mmocr主目錄下的tests/data/ocr_toy_dataset/imgs目錄下,圖片樣式大致如下

劃分訓練集和驗證集
import pandas as pd
import os
print('imgs文件夾中的文件總數', len(os.listdir('tests/data/ocr_toy_dataset/imgs')))
df = pd.DataFrame()
# 獲取所有圖像的文件名
df['file_name'] = os.listdir('tests/data/ocr_toy_dataset/imgs')
# 由文件名提取文本內容標籤
df['label'] = df['file_name'].apply(lambda x: x.split('.')[0])
# 隨機打亂
df = df.sample(frac=1, random_state=666)
# 重排索引
df.reset_index(drop=True, inplace=True)
# 訓練集
train_df = df.iloc[:800]
# 測試集
test_df = df.iloc[801:]
# 生成訓練集標籤
train_df.to_csv('tests/data/ocr_toy_dataset/train_label.txt', sep=' ', index=False, header=None)
# 生成測試集標籤
test_df.to_csv('tests/data/ocr_toy_dataset/test_label.txt', sep=' ', index=False, header=None)
print('標籤文件生成成功')此時會在tests/data/ocr_toy_dataset目錄下生成兩個標籤文件train_label.txt和test_label.txt,內容大致如下
2wc38.png 2wc38
y5n6d.png y5n6d
men4f.png men4f
57b27.png 57b27
x3deb.png x3deb
f858x.png f858x
xxw44.png xxw44下載toy_data.py,放入configs/_base_/recog_datasets目錄
wget http://download.openmmlab.com/mmocr/tutorial/toy_data.py內容如下
dataset_type = 'OCRDataset'
root = 'tests/data/ocr_toy_dataset'
img_prefix = f'{root}/imgs'
train_anno_file1 = f'{root}/train_label.txt'
train1 = dict(
type=dataset_type,
img_prefix=img_prefix,
ann_file=train_anno_file1,
loader=dict(
type='HardDiskLoader',
repeat=10, # 與訓練輪次相關
parser=dict(
type='LineStrParser',
keys=['filename', 'text'],
keys_idx=[0, 1],
separator=' ')),
pipeline=None,
test_mode=False)
test_anno_file1 = f'{root}/test_label.txt'
test = dict(
type=dataset_type,
img_prefix=img_prefix,
ann_file=test_anno_file1,
loader=dict(
type='HardDiskLoader',
repeat=1,
parser=dict(
type='LineStrParser',
keys=['filename', 'text'],
keys_idx=[0, 1],
separator=' ')),
pipeline=None,
test_mode=True)
train_list = [train1]
test_list = [test]修改configs/textrecog/sar目錄下的sar_r31_parallel_decoder_toy_dataset.py文件內容如下
_base_ = [
'../../_base_/default_runtime.py', '../../_base_/recog_models/sar.py',
'../../_base_/schedules/schedule_adam_step_5e.py',
'../../_base_/recog_pipelines/sar_pipeline.py',
'../../_base_/recog_datasets/toy_data.py'
]
train_list = {{_base_.train_list}}
test_list = {{_base_.test_list}}
train_pipeline = {{_base_.train_pipeline}}
test_pipeline = {{_base_.test_pipeline}}
data = dict(
workers_per_gpu=2,
samples_per_gpu=8,
train=dict(
type='UniformConcatDataset',
datasets=train_list,
pipeline=train_pipeline),
val=dict(
type='UniformConcatDataset',
datasets=test_list,
pipeline=test_pipeline),
test=dict(
type='UniformConcatDataset',
datasets=test_list,
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='acc')default_runtime.py是配置訓練時間和迭代的輪次的,也就是epoch;sar.py是配置算法模型的;schedule_adam_step_5e.py是配置學習率和優化器的;sar_pipeline.py是配置工作流的。
訓練代碼
from mmcv import Config
from mmdet.apis import set_random_seed
import mmcv
from mmocr.datasets import build_dataset
from mmocr.models import build_detector
from mmocr.apis import train_detector, init_detector, model_inference
import os.path as osp
cfg = Config.fromfile('./configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py')
# 存放輸出結果和日誌目錄
cfg.work_dir = './demo/tutorial_exps'
cfg.optimizer.lr = 0.001 / 8
cfg.lr_config.warmup = None
# 每訓練500張圖片記錄一次日誌
cfg.log_config.interval = 500
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
print(cfg.pretty_text)
# 建立數據集
datasets = [build_dataset(cfg.data.train)]
# 建立模型
model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
# 創建新目錄,保存訓練結果
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# 開始訓練
train_detector(model, datasets, cfg, distributed=False, validate=True)對測試圖片進行推理代碼
from mmcv import Config
from mmdet.apis import set_random_seed
import mmcv
from mmocr.datasets import build_dataset
from mmocr.models import build_detector
from mmocr.apis import init_detector, model_inference
cfg = Config.fromfile('./configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py')
# 存放輸出結果和日誌目錄
cfg.work_dir = './demo/tutorial_exps'
cfg.optimizer.lr = 0.001 / 8
cfg.lr_config.warmup = None
# 每訓練500張圖片記錄一次日誌
cfg.log_config.interval = 500
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
checkpoint = './demo/tutorial_exps/epoch_5.pth'
model = init_detector(cfg, checkpoint, device='cuda')
input_path = 'tests/data/ocr_toy_dataset/imgs/f6ne5.png'
result = model_inference(model, input_path)
out_img = model.show_result(input_path, result, out_file='output/demo_f6ne5.jpg', show=False)推理結果

不規則文字識別方法之 SAR: Show, Attend and Read
對於不規則(曲形文字、藝術字等)的識別,作者沒有采用基於修正(rectification)的策略,而是提出利用基於不規則文字而構造的(tailored)基於二維注意力機制模塊(2D attention module)的模型來定位和逐個識別字符的弱監督方法。之所以説是弱監督是由於該模型可以在不用額外的監督信息就可以定位單個字符(即不需要字符級別或像素級別的標註)。
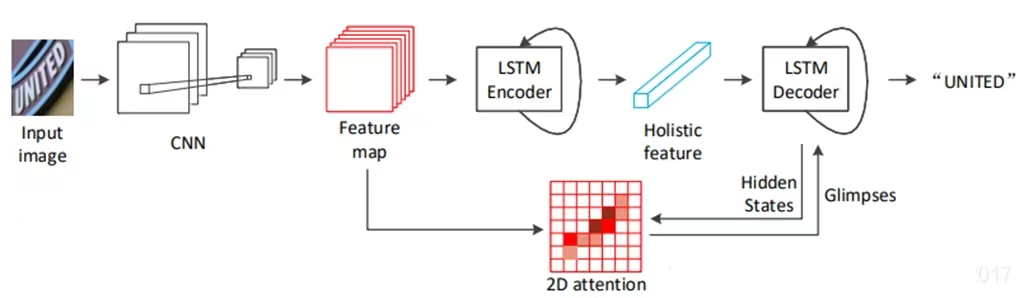
圖像送入主幹網(backbone),經過31層的ResNet卷積得到的特徵圖(feature maps),分別送入編解碼器以及注意力機制模塊,最終輸出識別的字符串。
ResNet CNN 模塊

- 共31層的ResNet,對於每個殘差模塊,如果輸入-輸出維度不同,則使用1x1卷積做projection shortcut;
- 同時使用了2x2最大池化和1x2最大池化(為了保留更多水平軸上的信息,對於'i', 'l'這種偏瘦的字符增益較大)
- 最終輸出V為 H x W x D (高、寬、通道數)的二維特徵圖,以用於提取圖像的整體特徵(holistic feature);
- 在保持原輸入圖像寬高比的基礎上,將圖像縮放至固定高度(論文中是48)和隨之變化的寬度,因此得到的特徵圖的寬度也是不固定的;
import torch
import torch.nn as nn
__all__ = ['basicblock', 'backbone']
class basicblock(nn.Module):
# 殘差模塊
def __init__(self, depth_in, output_dim, kernel_size, stride):
super(basicblock, self).__init__()
self.identity = nn.Identity()
self.conv_res = nn.Conv2d(depth_in, output_dim, kernel_size=1, stride=1)
self.batchnorm_res = nn.BatchNorm2d(output_dim)
self.conv1 = nn.Conv2d(depth_in, output_dim, kernel_size=kernel_size, stride=stride, padding=1)
self.conv2 = nn.Conv2d(output_dim, output_dim, kernel_size=kernel_size, stride=stride, padding=1)
self.batchnorm1 = nn.BatchNorm2d(output_dim)
self.batchnorm2 = nn.BatchNorm2d(output_dim)
self.relu1 = nn.ReLU(inplace=True)
self.relu2 = nn.ReLU(inplace=True)
self.depth_in = depth_in
self.output_dim = output_dim
def forward(self, x):
# create shortcut path
if self.depth_in == self.output_dim:
residual = self.identity(x)
else:
# 如果輸入 - 輸出維度不同,則使用1x1卷積做projection shortcut
residual = self.conv_res(x)
residual = self.batchnorm_res(residual)
out = self.conv1(x)
out = self.batchnorm1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.batchnorm2(out)
out += residual
out = self.relu2(out)
return out
class backbone(nn.Module):
# 主幹網絡
def __init__(self, input_dim):
super(backbone, self).__init__()
self.conv1 = nn.Conv2d(input_dim, 64, kernel_size=3, stride=1, padding=1)
self.batchnorm1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.batchnorm2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU(inplace=True)
# 2*2最大池化
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# Block 1 starts
self.basicblock1 = basicblock(128, 256, kernel_size=3, stride=1)
# Block 1 ends
self.conv3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.batchnorm3 = nn.BatchNorm2d(256)
self.relu3 = nn.ReLU(inplace=True)
# 2*2最大池化
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# Block 2 starts
self.basicblock2 = basicblock(256, 256, kernel_size=3, stride=1)
self.basicblock3 = basicblock(256, 256, kernel_size=3, stride=1)
# Block 2 ends
self.conv4 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.batchnorm4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU(inplace=True)
# 1*2最大池化
self.maxpool3 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))
# Block 5 starts
self.basicblock4 = basicblock(256, 512, kernel_size=3, stride=1)
self.basicblock5 = basicblock(512, 512, kernel_size=3, stride=1)
self.basicblock6 = basicblock(512, 512, kernel_size=3, stride=1)
self.basicblock7 = basicblock(512, 512, kernel_size=3, stride=1)
self.basicblock8 = basicblock(512, 512, kernel_size=3, stride=1)
# Block 5 ends
self.conv5 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
self.batchnorm5 = nn.BatchNorm2d(512)
self.relu5 = nn.ReLU(inplace=True)
# Block 3 starts
self.basicblock9 = basicblock(512, 512, kernel_size=3, stride=1)
self.basicblock10 = basicblock(512, 512, kernel_size=3, stride=1)
self.basicblock11 = basicblock(512, 512, kernel_size=3, stride=1)
# Block 3 ends
self.conv6 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
self.batchnorm6 = nn.BatchNorm2d(512)
self.relu6 = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv1(x)
x = self.batchnorm1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.batchnorm2(x)
x = self.relu2(x)
x = self.maxpool1(x)
x = self.basicblock1(x)
x = self.conv3(x)
x = self.batchnorm3(x)
x = self.relu3(x)
x = self.maxpool2(x)
x = self.basicblock2(x)
x = self.basicblock3(x)
x = self.conv4(x)
x = self.batchnorm4(x)
x = self.relu4(x)
x = self.maxpool3(x)
x = self.basicblock4(x)
x = self.basicblock5(x)
x = self.basicblock6(x)
x = self.basicblock7(x)
x = self.basicblock8(x)
x = self.conv5(x)
x = self.batchnorm5(x)
x = self.relu5(x)
x = self.basicblock9(x)
x = self.basicblock10(x)
x = self.basicblock11(x)
x = self.conv6(x)
x = self.batchnorm6(x)
x = self.relu6(x)
return x
# unit test
if __name__ == '__main__':
batch_size = 32
Height = 48
Width = 160
Channel = 3
input_images = torch.randn(batch_size, Channel, Height, Width)
model = backbone(Channel)
output_features = model(input_images)
print("Input size is:", input_images.shape)
print("Output feature map size is:", output_features.shape)運行結果
Input size is: torch.Size([32, 3, 48, 160])
Output feature map size is: torch.Size([32, 512, 12, 20])LSTM 編碼器-解碼器 模塊
編碼,就是將輸入序列轉化成一個固定長度的向量;解碼,就是將之前生成的固定向量再轉化成輸出序列。 當前 time step 的 hidden state 是由上一 time step 的state和當前 time step 輸入決定的,也就是獲得了各個時間段的隱藏層以後,再將隱藏層的信息彙總,生成最後的語義向量C;通常傳統的 encoder-decoder 結構將 encoder 最後的隱藏層作為語義向量C,作為 decoder 的輸入;
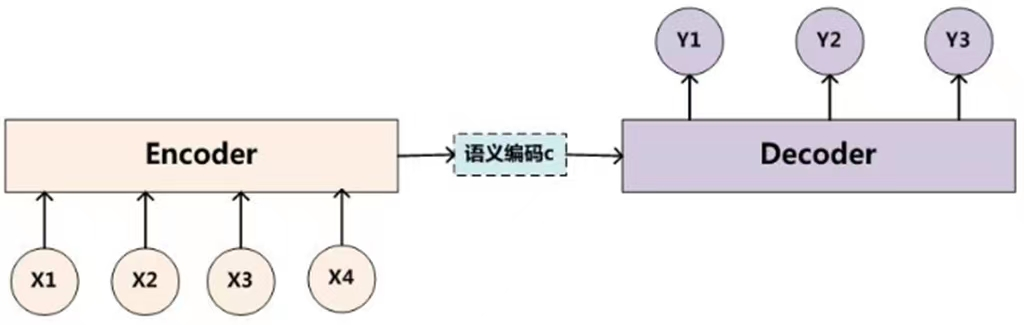
- 不改變原文字圖片(不修正)
- 編碼器encoder:
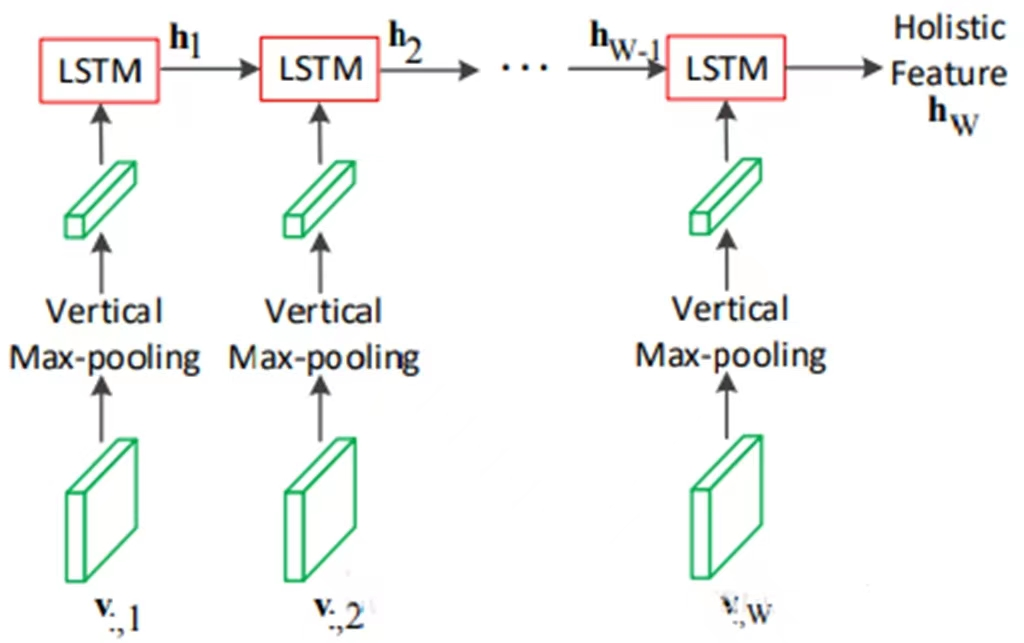
- 2層,每層各512個hidden state的LSTM模型;
- 每一個time step編碼器的一項輸入(圖中下方)是CNN得到的二維特徵圖的第 i 列經過垂直方向最大池化的特徵信息;
- 經過W(特徵圖的寬)個time step後,第二層LSTM的最後一個hidden state 就是輸入圖像的一個固定尺寸的特徵表示,稱為 holistic feature;
有關LSTM的內容請參考Tensorflow深度學習算法整理(二) 中的長短期記憶網絡,不過它這裏輸入LSTM的是特徵圖的每一列池化後的值,而在Tensorflow那邊是一個一個的文字或者字符。
import torch
import torch.nn as nn
__all__ = ['encoder']
class encoder(nn.Module):
# LSTM編碼器
def __init__(self, H, C, hidden_units=512, layers=2, keep_prob=1.0, device='cpu'):
super(encoder, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=(H, 1), stride=1)
self.lstm = nn.LSTM(input_size=C, hidden_size=hidden_units, num_layers=layers, batch_first=True, dropout=keep_prob)
# 層數
self.layers = layers
# 序列數
self.hidden_units = hidden_units
self.device = device
def forward(self, x):
self.lstm.flatten_parameters()
# x is feature map in [batch, C, H, W]
# 初始化兩個狀態
h_0 = torch.zeros(self.layers * 1, x.size(0), self.hidden_units).to(self.device)
c_0 = torch.zeros(self.layers * 1, x.size(0), self.hidden_units).to(self.device)
# 先池化
x = self.maxpool(x) # [batch, C, 1, W]
x = torch.squeeze(x) # [batch, C, W]
if len(x.size()) == 2: # [C, W]
x = x.unsqueeze(0) # [batch, C, W]
x = x.permute(0, 2, 1) # [batch, W, C]
# 將池化後的feature map的每一列輸入lstm網絡
_, (h, _) = self.lstm(x, (h_0, c_0)) # h with shape [layers*1, batch, hidden_uints]
return h[-1] # shape [batch, hidden_units]
# unit test
if __name__ == '__main__':
batch_size = 32
Height = 48
Width = 160
Channel = 3
input_feature = torch.randn(batch_size, Channel, Height, Width)
print("Input feature size is:", input_feature.shape)
encoder_model = encoder(Height, Channel, hidden_units=512, layers=2, keep_prob=1.0)
output_encoder = encoder_model(input_feature)
print("Output feature of encoder size is:", output_encoder.shape) # (batch, hidden_units)運行結果
Input feature size is: torch.Size([32, 3, 48, 160])
Output feature of encoder size is: torch.Size([32, 512])- 解碼器decoder:
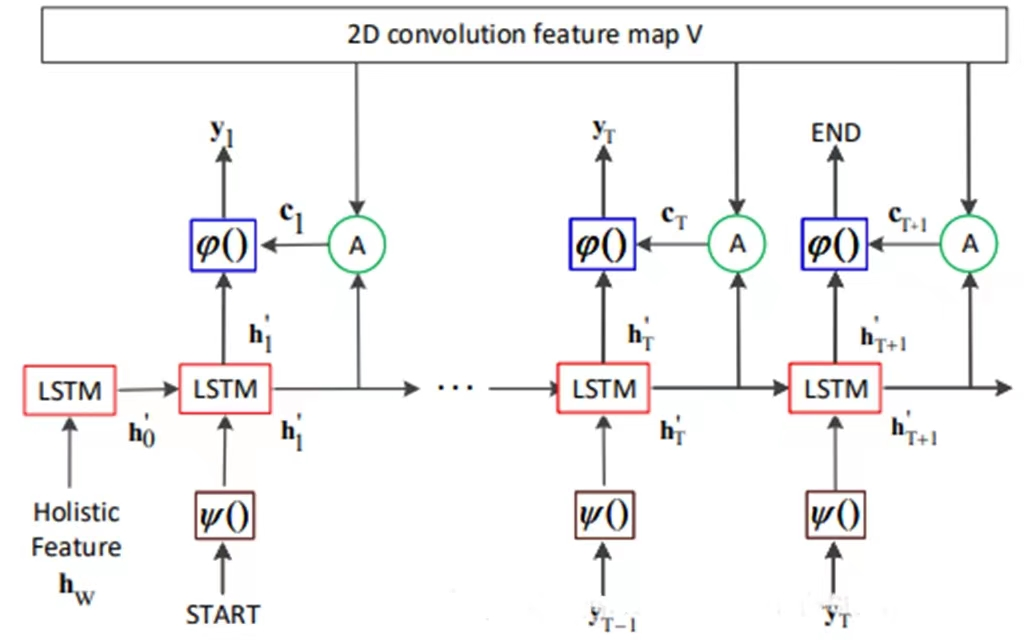
- 2層,每層各512個hidden state的LSTM模型;
- 編碼器和解碼器之間不共享參數;
(初始化的輸入), "START" token,以及前一層 的輸出,依次作為當前step的輸入,直到被"END" token終止;
- 所有的LSTM輸入都是經過one-hot向量表示後,再經過一個線性變化
函數;
- 訓練階段,解碼器LSTM的輸入由 ground truth 的字符序列代替;
- 每一個step的輸出
由當前step的 hidden state 和attention的輸出作為
函數的輸入得到:
, 其中
是當前的 hidden state,
是attention模塊的輸出,
是一個線性變化,將特徵嵌入輸出空間的94個類別(10個數字,26*2 個字符,31個標點符號);