攜程分佈式圖數據庫Nebula Graph運維治理實踐—大規模集羣部署與二開優化
一、背景
隨着互聯網世界產生的數據越來越多,數據之間的聯繫越來越複雜層次越來越深,人們希望從這些紛亂複雜的數據中探索各種關聯的需求也在與日遞增。為了更有效地應對這類場景,圖技術受到了越來越多的關注及運用。

DB-ENGINES 趨勢報告顯示圖數據庫趨勢增長遙遙領先
在攜程,很早就有一些業務嘗試了圖技術,並將其運用到生產中,以Neo4j和JanusGraph為主。2021年開始,我們對圖數據庫進行集中的運維治理,期望規範業務的使用,並適配攜程已有的各種系統,更好地服務業務方。經過調研,我們選擇分佈式圖數據庫Nebula Graph作為管理的對象,主要基於以下幾個因素考慮:
1)Nebula Graph開源版本即擁有橫向擴展能力,為大規模部署提供了基本條件;
2)使用自研的原生存儲層,相比JanusGraph這類構建在第三方存儲系統上的圖數據庫,性能和資源使用效率上具有優勢;
3)支持兩種語言,尤其是兼容主流的圖技術語言Cypher,有助於用户從其他使用Cypher語言的圖數據庫(例如Neo4j)中遷移;
4)擁有後發優勢(2019起開源),社區活躍,且主流的互聯網公司都有參與(騰訊,快手,美團,網易等);
5)使用技術主流,代碼清晰,技術債較少,適合二次開發;
二、Nebula Graph架構及集羣部署
Nebula Graph是一個分佈式的計算存儲分離架構,如下圖:

其主要由Graphd,Metad和Storaged三部分服務組成,分別負責計算,元數據存取,圖數據(點,邊,標籤等數據)的存取。在攜程的網絡環境中,我們提供了三種部署方式來支撐業務:
2.1 三機房部署
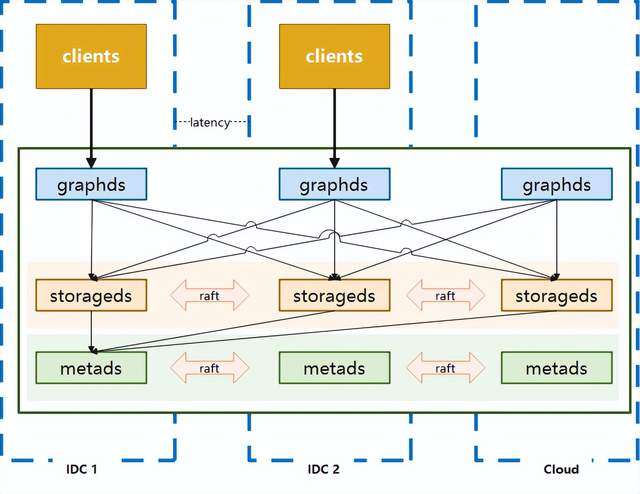
用於滿足一致性和容災的要求,優點是任意一個機房發生機房級別故障,集羣仍然可以使用,適用於核心應用。但缺點也是比較明顯的,數據通過raft協議進行同步的時候,會遇到跨機房問題,性能會受到影響。
2.2 單機房部署

集羣所有節點都在一個機房中,節點之間通訊可以避免跨機房問題(應用端與服務端之間仍然會存在跨機房調用),由於機房整體出現問題時該部署模式的系統將無法使用,所以適用於非核心應用進行訪問。
2.3 藍綠雙活部署
在實際使用中,以上兩種常規部署方式並不能滿足一些業務方的需求,比如性能要求較高的核心應用,三機房的部署方式所帶來的網絡損耗可能會超出預期。根據攜程酒店某個業務場景真實測試數據來看,本地三機房的部署方式延遲要比單機房高50%+,但單機房部署無法抵抗單個IDC故障,此外還有用户希望能存在類似數據回滾的能力,以應對應用發佈,集羣版本升級可能導致的錯誤。
考慮到使用圖數據庫的業務大多數據來自離線系統,通過離線作業將數據導入到圖數據庫中,數據一致的要求並不高,在這種條件下使用藍綠部署能夠在災備和性能上得到很好的滿足。

與此同時我們還增加了一些配套的輔助功能,比如:
- 分流:可以按比例分配機房的訪問,也可以主動切斷對某個機房的流量訪問
- 災備:在發生機房級故障時,可自動切換讀訪問的流量,寫訪問的流量切換則通過人工進行操作
藍綠雙活方式是在性能、可用性、一致性上的一個折中的選擇,使用此方案時應用端架構也需要有更多的調整以配合數據的存取。
生產上的一個例子:

三機房情況

藍綠部署
三、中間件及運維管理
我們基於k8s crd和operator來進行Nebula Graph的部署,同時通過服務集成到現有的部署配置頁面和運維管理頁面,來獲得對pod的執行和遷移的控制能力。基於sidecar模式監控收集Nebula Graph的核心指標並通過telegraf發送到攜程自研的Hickwall集中展示,並設置告警等一系列相關工作。
此外我們集成了跨機房的域名分配功能,為節點自動分配域名用於內部訪問(域名只用於集羣內部,集羣與外部連通是通過ip直連的),這樣做是為了避免節點漂移造成ip變更,影響集羣的可用性。
在客户端上,相比原生客户端,我們主要做了以下幾個改進和優化:
3.1 Session管理功能
原生客户端Session管理比較弱,尤其是2.x早期幾個版本,多線程訪問Session並不是線程安全的,Session過期或者失效都需要調用方來處理,不適合大規模使用。同時雖然官方客户端創建的Session是可以複用的,並不需要release,官方也鼓勵用户複用,但是卻沒有提供統一的Session管理功能來幫助用户複用,因此我們增加了Session Pool的概念來實現複用。
其本質上是管理一個或多個Session Object Queue,通過borrow-and-return的方式(下圖),確保了一個Session在同一時間只會由一個執行器在使用,避免了共用Session產生的問題。同時通過對隊列的管理,我們可以進行Session數量和版本的管理,比如預生成一定量的Session,或者在管理中心發出消息之後變更Session的數量或者訪問的路由。

3.2 藍綠部署(包括讀寫分離)
上面章節中介紹了藍綠部署,相應的客户端也需要改造以支持訪問2個集羣。由於生產中,讀和寫的邏輯往往不同,比如讀操作希望可以由2個集羣共同提供數據,而寫的時候只希望影響單邊,所以我們在進行藍綠處理的時候也增加了讀寫分離(下圖)。

3.3 流量分配
如果要考慮到單邊切換以及讀寫不同的路由策略,就需要增加流量分配功能。我們沒有采用攜程內廣泛使用的Virtual IP作為訪問路由,希望有更為強大的定製管理能力及更好的性能。
a)通過直連而不是Virtual IP中轉可以減少一次轉發的損耗
b)在維持長連接的同時也能實現每次請求使用不同的鏈路,平攤graphd的訪問壓力
c)完全自主控制路由,可以實現更為靈活的路由方案
d)當存在節點無法訪問的時候,客户端可以自動臨時排除有問題的IP,在短時間內避免再次使用。而如果使用Virtual IP的話,由於一個Virtual IP會對應多個物理IP,就沒有辦法直接這樣操作。
通過構造面向不同idc的Session Pool,並根據配置進行權重輪詢,就可以達到按比例分配訪問流量的目的(下圖)。

將流量分配集成進藍綠模式,就基本實現了基本的客户端改造(下圖)。

3.4 結構化語句查詢
圖DSL目前主流的有兩種,Gremlin和Cypher,前者是過程式語言而後者是聲明式語言。Nebula Graph支持了openCypher(Cypher的開源項目)語法和自己設計的nGQL原生語法,這兩種都是聲明式語言,在風格上比較類似SQL。儘管如此,對於一些較為簡單的語句,類似Gremlin風格的過程式語法對用户會更為友好,並且有利用監控埋點。基於這個原因,我們封裝了一個過程式的語句生成器。
例如:
| Cypher風格 | MATCH (v:user{name:"XXX"})-[e:follow|:serve]->(v2) RETURN v2 AS Friends; |
| 新增的過程式風格 | Builder.match().vertex("v").hasTag("user").property("name", "XXX", DataType.String()).edge("e", Direction.OUTGOING).type("follow").type("serve").vertex("v2").ret("v2", "Friends") |
四、系統調優實踐
由於建模,使用場景,業務需求的差異,使用Nebula Graph的過程中所遇到的問題很可能會完全不同,以下以攜程酒店信息圖譜線上具體的例子進行説明,在整個落地過程我們遇到的問題及處理過程(文中以下內容是基於Nebula Graph 2.6.1進行的)。
關於酒店該業務的更多細節,可以閲讀《信息圖譜在攜程酒店的應用》這篇文章。
4.1 酒店集羣不穩定
起因是酒店應用上線後發生了一次故障,大量的訪問超時,並伴隨着“The leader has changed”這樣的錯誤信息。稍加排查,我們發現metad集羣有問題,metad0的local ip和metad_server_address的配置不一致,所以metad0實際上一直沒有工作。
但這本身並不會導致系統問題,因為3節點部署,只需要2個節點工作即可,後來metad1容器又意外被漂移了,導致ip變更,這個時候實際上metad集羣已經無法工作(下圖),導致整個集羣都受到了影響。

在處理完以上故障並重啟之後,整個系統卻並沒有恢復正常,cpu的使用率很高。此時外部應用並沒有將流量接入進來,但整個metad集羣內部網絡流量卻很大,如下圖所示:


監控顯示metad磁盤空間使用量很大,檢查下來WAL在不斷增加,説明這些流量主要是數據的寫入操作。我們打開WAL數據的某幾個文件,其大部分都是Session的元數據,因為Session信息是會在Nebula集羣內持久化的,所以考慮問題可能出在這裏。閲讀源碼我們注意到,graphd會從metad中同步所有的session信息,並在修改之後將數據再全部回寫到metad中,所以如果流量都是session信息的話,那麼問題就可能:
a)Session沒有過期
b)創建了太多的Session
檢查發現該集羣沒有配置超時時間,所以我們修改以下配置來處理這個問題:
| 類型 | 配置項 | 原始值 | 修改值 | 説明 |
| Graphd | session_idle_timeout_secs | 默認(0) | 86400 | 此配置控制session的過期,由於初始我們沒有設置這個參數,這意味着session永遠不會過期,這會導致過去訪問過該graphd的session會永遠存在於metad存儲層,造成session元數據累積。 |
| session_reclaim_interval_secs | 默認(10) | 30 | 原設置説明每10s graphd會將session信息發送給metad持久化。這也會導致寫入數據量過多。考慮到即使down機也只是損失部分的Session元數據更新,這些損失帶來的危害比較小,所以我們改成了30s以減少於metad之間同步元數據的次數。 | |
| Metad | wal_ttl | 默認(14400) | 3600 | wal用於記錄修改操作的,一般來説是不需要保留太久的,況且nebula graph為了安全,都至少會為每個分片保留最後2個wal文件,所以減少ttl加快wal淘汰,將空間節約出來 |
修改之後,metad的磁盤空間佔用下降,同時通信流量和磁盤讀寫也明顯下降(下圖):

系統逐步恢復正常,但是還有一個問題沒有解決,就是為什麼有如此之多的session數據?查看應用端日誌,我們注意到session創建次數超乎尋常,如下圖所示:

通過日誌發現是我們自己開發的客户端中的bug造成的。我們會在報錯時讓客户端釋放對應的session,並重新創建,但由於系統抖動,這個行為造成了比較多的超時,導致更多的session被釋放並重建,引起了惡性循環。針對這個問題,對客户端進行了如下優化:
| 修改 | |
| 1 | 將創建session行為由併發改為串行,每次只允許一個線程進行創建工作,不參與創建的線程監聽session pool |
| 2 | 進一步增強session的複用,當session執行失敗的時候,根據失敗原因來決定是否需要release。原有的邏輯是一旦執行失敗就release當前session,但有些時候並非是session本身的問題,比如超時時間過短,nGQL有錯誤這些應用層的情況也會導致執行失敗,這個時候如果直接release,會導致session數量大幅度下降從而造成大量session創建。根據問題合理的劃分錯誤情況來進行處理,可以最大程度保持session狀況的穩定 |
| 3 | 增加預熱功能,根據配置提前創建好指定數量的session,以避免啟動時集中創建session導致超時 |
4.2 酒店集羣存儲服務CPU使用率過高
酒店業務方在增加訪問量的時候,每次到80%的時候集羣中就有少數storaged不穩定,cpu使用率突然暴漲,導致整個集羣響應增加,從而應用端產生大量超時報錯,如下圖所示:

和酒店方排查下來初步懷疑是存在稠密點問題(在圖論中,稠密點是指一個點有着極多的相鄰邊,相鄰邊可以是出邊或者是入邊),部分storaged被集中訪問引起系統不穩定。由於業務方強調稠密點是其業務場景難以避免的情況,我們決定採取一些調優手段來緩解這個問題。
1)嘗試通過Balance來分攤訪問壓力
回憶之前的官方架構圖,數據在storaged中是分片的,且raft協議中只有leader才會處理請求,所以重新進行數據平衡操作,是有可能將多個稠密點分攤到不同的服務上意減輕單一服務的壓力。同時我們對整個集羣進行compaction操作(由於Storaged內部使用了RocksDB作為存儲引擎,數據是通過追加來進行修改的,Compaction可以清楚過時的數據,提高訪問效率)。
操作之後集羣的整體cpu是有一定的下降,同時服務的響應速度也有小幅的提升,如下圖。


但在運行一段時間之後仍然遇到了cpu突然增加的情況,稠密點顯然沒有被平衡掉,也説明在分片這個層面是沒法緩解稠密點帶來的訪問壓力的。
2)嘗試通過配置緩解鎖競爭
進一步調研出現問題的storaged的cpu的使用率,可以看到當流量增加的時候,內核佔用的cpu非常高,如下圖所示:

抓取perf看到,鎖競爭比較激烈,即使在“正常”情況下,鎖的佔比也很大,而在競爭激烈的時候,出問題的storaged服務上這個比例超過了50%。如下圖所示:

所以我們從減少衝突入手,對nebula graph集羣主要做了如下改動:
| 類型 | 配置項 | 原始值 | 修改值 | 説明 |
| Storaged | rocksdb_block_cache | 默認(4) | 8192 | block cache用緩存解壓縮之後的數據,cache越大,數據淘汰情況越低,這樣就越可能更快的命中數據,減少反覆從page cache加載及depress的操作 |
| enable_rocksdb_prefix_filtering | false | true | 在內存足夠的情況下,我們打開prefix過濾,是希望通過其通過前綴更快的定位到數據,減少查詢非必要的數據,減少數據競爭 | |
| RocksDB | disable_auto_compactions | 默認 | false | 打開自動compaction,緩解因為數據碎片造成的查詢cpu升高 |
| write_buffer_size | 默認 | 134217728 | 將memtable設置為128MB,減少其flush的次數 | |
| max_background_compactions | 默認 | 4 | 控制後台compactions的線程數 |
重新上線之後,整個集羣服務變得比較平滑,cpu的負載也比較低,正常情況下鎖競爭也下降不少(下圖),酒店也成功的將流量推送到了100%。

但運行了一段時間之後,我們仍然遇到了服務響應突然變慢的情況,熱點訪問帶來的壓力的確超過了優化帶來的提升。
3)嘗試減小鎖的顆粒度
考慮到在分片級別的balance不起作用,而cpu的上升主要是因為鎖競爭造成的,那我們想到如果減小鎖的顆粒度,是不是就可以儘可能減小競爭?RocksDB的LRUCache允許調整shared數量,我們對此進行了修改:
| 版本 | LRUCache默認分片數 | 方式 |
| 2.5.0 | 28 | 修改代碼,將分片改成210 |
| 2.6.1及以上 | 28 | 通過配置cache_bucket_exp = 10,將分片數改為210 |
觀察下來效果不明顯,無法解決熱點競爭導致的雪崩問題。其本質同balance操作一樣,只是粒度的大小的區別,在熱點非常集中的情況下,在數據層面進行處理是走不通的。
4)嘗試使用ClockCache
競爭的鎖來源是block cache造成的。nebula storaged使用rocksdb作為存儲,其使用的是LRUCache作為block cache等一系列cache的存儲模塊,LRUCache在任何類型的訪問的時候需要需要加鎖操作,以進行一些LRU信息的更新,排序的調整及數據的淘汰,存在吞吐量的限制。

由於我們主要面臨的就是鎖競爭,在業務數據沒法變更的情況下,我們希望其他cache模塊來提升訪問的吞吐。按照rocksdb官方介紹,其還支持一種cache類型ClockCache,特點是在查詢時不需要加鎖,只有在插入時才需要加鎖,會有更大的訪問吞吐,考慮到我們主要是讀操作,看起來ClockCache會比較合適。
LRU cache和Clock cache的區別:
http://rocksdb.org.cn/doc/Block-Cache.html
經過修改源碼和重新編譯,我們將緩存模塊改成了ClockCache,如下圖所示:

但集羣使用時沒幾分鐘就core, 查找資料我們發現目前ClockCache支持還存在問題(
http://github.com/facebook/rocksdb/pull/8261), 此方案目前無法使用。
5)限制線程使用
可以看到整個系統在當前配置下,是存在非常多的線程的,如下圖所示。

如果是單線程,就必然不會存在鎖競爭。但作為一個圖服務,每次訪問幾乎會解析成多個執行器來併發訪問,強行改為單線程必然會造成訪問堆積。
所以我們考慮將原有的線程池中的進程調小,以避免太多的線程進行同步等待帶來的線程切換,以減小系統對cpu的佔用。
| 類型 | 配置項 | 原始值 | 修改值 | 説明 |
|---|---|---|---|---|
| Storaged | num_io_threads | 默認(16) | 4或者8 | |
| num_worker_threads | 默認(32) | 4或者8 | ||
| reader_handlers | 默認(32) | 8或者12 | 官方未公開配置 |
調整之後整個系統cpu非常平穩,絕大部分物理機cpu在20%以內,且沒有之前遇到的突然上下大幅波動的情況(瞬時激烈鎖競爭會大幅度提升cpu的使用率),説明這個調整對當前業務來説是有一定效果的。
隨之又遇到了下列問題,前端服務突然發現nebula的訪問大幅度超時,而從系統監控的角度卻毫無波動(下圖24,19:53系統其實已經響應出現問題了,但cpu沒有任何波動)。

原因是在於,限制了thread 確實有效果,減少了競爭,但隨着壓力的正大,線程吞吐到達極限,但如果增加線程,資源的競爭又會加劇,無法找到平衡點。
6)關閉數據壓縮,關閉block cache
在沒有特別好的方式避免鎖競爭的情況,我們重新回顧了鎖競爭的整個發生過程,鎖產生本身就是由cache自身的結構帶來的,尤其是在讀操作的時候,我們並不希望存在什麼鎖的行為。
使用block cache,是為了在合理的緩存空間中儘可能的提高緩存命中率,以提高緩存的效率。但如果緩存空間非常充足,且命中長期的數據長期處於特定的範圍內,實際上並沒有觀察到大量的緩存淘汰的情況,且當前服務的緩存實際上也並沒有用滿,所以想到,是不是可以通過關閉block cache,而直接訪問page cache來避免讀操作時的加鎖行為。
除了block cache,存儲端還有一大類內存使用是Indexes and filter blocks,與此有關的設置在RocksDB中是
cache_index_and_filter_blocks。當這個設置為true的時候,數據會緩存到block cache中,所以如果關閉了block cache,我們就需要同樣關閉cache_index_and_filter_blocks(在Nebula Graph中,通過配置項enable_partitioned_index_filter替代直接修改RocksDB的cache_index_and_filter_blocks)。
但僅僅修改這些並沒有解決問題,實際上觀察perf我們仍然看到鎖的競爭造成的阻塞(下圖):
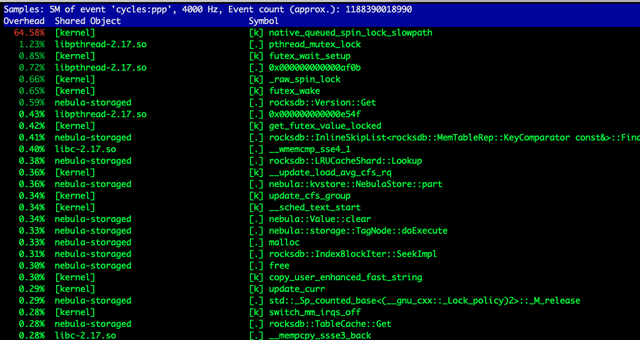
這是因為當cache_index_and_filter_blocks為false的時候,並不代表index和filter數據不會被加載到內存中,這些數據其實會被放進table cache裏,仍然需要通過LRU來維護哪些文件的信息需要淘汰,所以LRU帶來的問題並沒有完全解決。處理的方式是將max_open_files設置為-1,以提供給系統無限制的table cache的使用,在這種情況下,由於沒有文件信息需要置換出去,算法邏輯被關閉。
總結下來核心修改如下表:
| 類型 | 配置項 | 原始值 | 修改值 | 説明 |
| Storaged | rocksdb_block_cache | 8192 | -1 | 關閉block cache |
| rocksdb_compression_per_level | lz4 | no:no:no:no:lz4:lz4:lz4 | 在L0~L3層關閉壓縮 | |
| enable_partitioned_index_filter | true | false | 避免將index和filter緩存進block cache | |
| RocksDB | max_open_files | 4096 | -1 | 避免文件被table cache淘汰,避免文件描述符被關閉,加快文件的讀取 |
關閉了block cache後,整個系統進入了一個非常穩定的狀態,線上集羣在訪問量增加一倍以上的情況下,系統的cpu峯值反而穩定在30%以下,且絕大部分時間都在10%以內(下圖)。

需要説明的是,酒店場景中關閉block cache是一個非常有效的手段,能夠對其特定情況下的熱點訪問起到比較好的效果,但這並非是一個常規方式,我們在其他業務方的nebula graph集羣中並沒有關閉block cache。
4.3 數據寫入時服務down機
起因酒店業務在全量寫入的時候,即使量不算很大(4~5w/s),在不特定的時間就會導致整個graphd集羣完全down機,由於graphd集羣都是無狀態的,且互相之間沒有關係,如此統一的在某個時刻集體down機,我們猜測是由於訪問請求造成。通過查看堆棧發現了明顯的異常(下圖):

可以看到上圖中的三行語句被反覆執行,很顯然這裏存在遞歸調用,並且無法在合理的區間內退出,猜測為堆棧已滿。在增加了堆棧大小之後,整個執行沒有任何好轉,説明遞歸不僅層次很深,且可能存在指數級的增加的情況。同時觀察down機時的業務請求日誌,失敗瞬間大量執行失敗,但有一些執行失敗顯示為null引用錯誤,如下圖所示:

這是因為返回了報錯,但沒有error message,導致發生了空引用(空引用現象是客户端未合理處理這種情況,也是我們客户端的bug),但這種情況很奇怪,為什麼會沒有error message,檢查其trace日誌,發現這些請求執行nebula時間都很長,且存在非常大段的語句,如下圖所示:

預感是這些語句導致了graphd的down機,由於執行被切斷導致客户端生成了一個null值。將這些語句進行重試,可以必現down機的場景。檢查這樣的請求發現其是由500條語句組成(業務方語句拼接上限500),並沒有超過配置設置的最大執行語句數量(512)。
看起來這是一個nebula官方的bug,我們已經將此問題提交給官方。同時業務方語句拼接限制從500降為200後順利避免該問題導致的down機。
五、Nebula Graph二次開發
當前我們對Nebula Graph的修改主要集中的幾個運維相關的環節上,比如新增了命令來指定遷移Storaged中的分片,以及將leader遷移到指定的實例上(下圖)。

六、未來規劃
- 與攜程大數據平台整合,充分利用Spark或者Flink來實現數據的傳輸和ETL,提高異構集羣間數據的遷移能力。
- 提供Slowlog檢查功能,抓取造成slowlog的具體語句。
- 參數化查詢功能,避免依賴注入。
- 增強可視化能力,增加定製化功能。
【作者簡介】
Patrick Yu,攜程雲原生研發專家,關注非關係型分佈式數據存儲及相關技術。
- 圖數據庫在中國移動金融風控的落地應用
- 記一次 rr 和硬件斷點解決內存踩踏問題
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網絡應用
- 用圖技術搞定附近好友、時空交集等 7 個典型社交網絡應用
- 圖數據庫中的“分佈式”和“數據切分”(切圖)
- 揭祕可視化圖探索工具 NebulaGraph Explore 是如何實現圖計算的
- 連接微信羣、Slack 和 GitHub:社區開放溝通的基礎設施搭建
- 圖數據庫認證考試 NGCP 錯題解析 vol.02:這 10 道題竟無一人全部答對
- 如何判斷多賬號是同一個人?用圖技術搞定 ID Mapping
- 複雜場景下圖數據庫的 OLTP 與 OLAP 融合實踐
- 如何運維多集羣數據庫?58 同城 NebulaGraph Database 運維實踐
- 有了 ETL 數據神器 dbt,表數據秒變 NebulaGraph 中的圖數據
- 基於圖的下一代入侵檢測系統
- 從實測出發,掌握 NebulaGraph Exchange 性能最大化的祕密
- 讀 NebulaGraph源碼 | 查詢語句 LOOKUP 的一生
- 當雲原生網關遇上圖數據庫,NebulaGraph 的 APISIX 最佳實踐
- 從全球頂級數據庫大會 SIGMOD 看數據庫發展趨勢
- 「實操」結合圖數據庫、圖算法、機器學習、GNN 實現一個推薦系統
- 如何輕鬆做數據治理?開源技術棧告訴你答案
- 圖算法、圖數據庫在風控場景的應用