訓練千億引數大模型,離不開四種GPU並行策略


作者|Lilian Weng、Greg Brockman
翻譯|董文文
AI領域的許多最新進展都圍繞大規模神經網路展開,但訓練大規模神經網路是一項艱鉅的工程和研究挑戰,需要協調GPU叢集來執行單個同步計算。
隨著叢集數和模型規模的增長,機器學習從業者開發了多項技術,在多個GPU上進行並行模型訓練。
乍一看,這些並行技術令人生畏,但只需對計算結構進行一些假設,這些技術就會變得清晰——在這一點上,就像資料包在網路交換機之間傳遞一樣,那也只是從A到B傳遞並不透明的位(bits)。
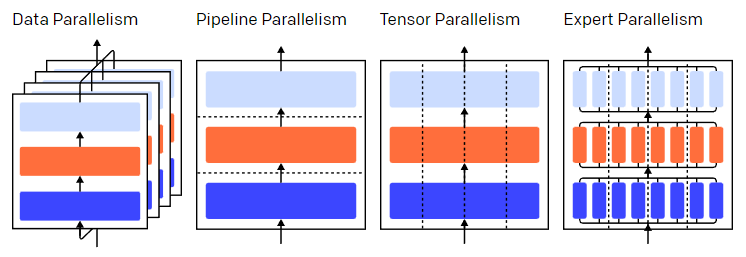
三層模型中的並行策略。每種顏色代表一層,虛線分隔不同的 GPU。
訓練神經網路是一個迭代的過程。在一次迭代過程中,訓練資料通過模型的layer(層)進行前向傳遞,對一批資料中的訓練樣本進行計算得到輸出。然後再通過layer進行反向傳遞,其中,通過計算引數的梯度,可以得到各個引數對最終輸出的影響程度。
批量平均梯度、引數和每個引數的優化狀態會傳遞給優化演算法,如Adam,優化演算法會計算下一次迭代的引數 ( 效能更佳)並更新每個引數的優化狀態。隨著對資料進行多次迭代訓練,訓練模型會不斷優化,得到更加精確的輸出。
不同的並行技術將訓練過程劃分為不同的維度,包括:
-
資料並行(Data Parallelism)——在不同的GPU上運行同一批資料的不同子集;
-
流水並行(Pipeline Parallelism)——在不同的GPU上執行模型的不同層;
-
模型並行(Tensor Parallelism)——將單個數學運算(如矩陣乘法)拆分到不同的GPU上執行;
-
專家混合(Mixture-of-Experts)——只用模型每一層中的一小部分來處理資料。
本文以GPU訓練神經網路為例,並行技術同樣也適用於使用其他神經網路加速器進行訓練。作者為OpenAI華裔工程師Lilian Weng和聯合創始人&總裁Greg Brockman。
1
資料並行
資料並行是指將相同的引數複製到多個GPU上,通常稱為“工作節點(workers)”,併為每個GPU分配不同的資料子集同時進行處理。
資料並行需要把模型引數載入到單GPU視訊記憶體裡,而讓多個GPU計算的代價就是需要儲存引數的多個副本。話雖如此,還有一些方法可以增加GPU的RAM,例如在使用的間隙臨時將引數解除安裝(offload)到CPU的記憶體上。
更新資料並行的節點對應的引數副本時,需要協調節點以確保每個節點具有相同的引數。
最簡單的方法是在節點之間引入阻塞通訊:(1)單獨計算每個節點上的梯度;(2) 計算節點之間的平均梯度;(3) 單獨計算每個節點相同的新引數。其中,步驟 (2) 是一個阻塞平均值,需要傳輸大量資料(與節點數乘以引數大小成正比),可能會損害訓練吞吐量。
有一些非同步更新方案可以消除這種開銷,但是會損害學習效率;在實踐中,通常會使用同步更新方法。
2
流水並行
流水並行是指按順序將模型切分為不同的部分至不同的GPU上執行。每個GPU上只有部分引數,因此每個部分的模型消耗GPU的視訊記憶體成比例減少。
將大型模型分為若干份連續的layer很簡單。但是,layer的輸入和輸出之間存在順序依賴關係,因此在一個GPU等待其前一個GPU的輸出作為其輸入時,樸素的實現會導致出現大量空閒時間。這些空閒時間被稱作“氣泡”,而在這些等待的過程中,空閒的機器本可以繼續進行計算。
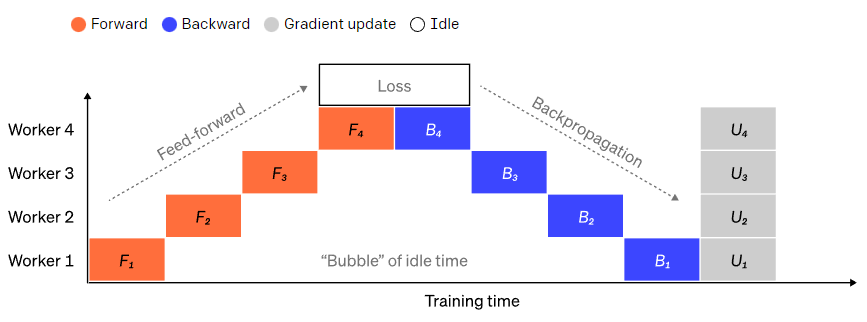
一個樸素的流水並行設定,其中模型按layer垂直分成 4 個部分。worker 1託管網路第一層(離輸入最近)的模型引數,而 worker 4 託管第 4 層(離輸出最近)的模型引數。“F”、“B”和“U”分別代表前向、反向和更新操作。下標指示資料在哪個節點上執行。由於順序依賴性,資料一次只能在一個節點上執行,從而會導致大量空閒時間,即“氣泡”。
為了減少氣泡的開銷,在這裡可以複用資料並行的打法,核心思想是將大批次資料分為若干個微批次資料(microbatches),每個節點每次只處理一個微批次資料,這樣在原先等待的時間裡可以進行新的計算。
每個微批次資料的處理速度會成比例地加快,每個節點在下一個小批次資料釋放後就可以開始工作,從而加快流水執行。有了足夠的微批次,節點大部分時間都在工作,而氣泡在程序的開頭和結束的時候最少。梯度是微批次資料梯度的平均值,並且只有在所有小批次完成後才會更新引數。
模型拆分的節點數通常被稱為流水線深度(pipeline depth)。
在前向傳遞過程中,節點只需將其layer塊的輸出(啟用)傳送給下一個節點;在反向傳遞過程中,節點將這些啟用的梯度傳送給前一個節點。如何安排這些程序以及如何聚合微批次的梯度有很大的設計空間。GPipe 讓每個節點連續前向和後向傳遞,在最後同步聚合多個微批次的梯度。PipeDream則是讓每個節點交替進行前向和後向傳遞。
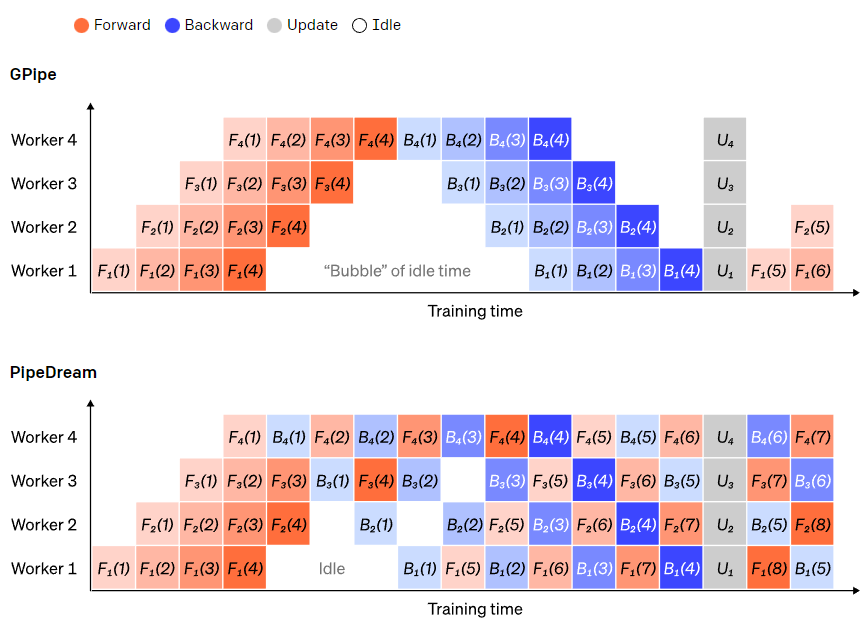
GPipe 和 PipeDream 流水方案對比。每批資料分為4個微批次,微批次1-8對應於兩個連續大批次資料。圖中,“(編號)”表示在哪個微批次上執行操作,下標表示節點 ID。其中,PipeDream使用相同的引數執行計算,可以獲得更高的效率。
3
模型並行
在流水並行中,模型沿layer被“垂直”拆分,如果在一個layer內“水平”拆分單個操作,這就是模型並行。許多現代模型(如 Transformer)的計算瓶頸是將啟用值與權重相乘。
矩陣乘法可以看作是若干對行和列的點積:可以在不同的 GPU 上計算獨立的點積,也可以在不同的 GPU 上計算每個點積的一部分,然後相加得到結果。
無論採用哪種策略,都可以將權重矩陣切分為大小均勻的“shards”,不同的GPU負責不同的部分。要得到完整矩陣的結果,需要進行通訊將不同部分的結果進行整合。
Megatron-LM在Transformer的self-attention和MLP layer進行並行矩陣乘法;PTD-P同時使用模型、資料和流水並行,其中流水並行將多個不連續的layer分配到單裝置上執行,以更多網路通訊為代價來減少氣泡開銷。
在某些場景下,網路的輸入可以跨維度並行,相對於交叉通訊,這種方式的平行計算程度較高。如序列並行,輸入序列在時間上被劃分為多個子集,通過在更細粒度的子集上進行計算,峰值記憶體消耗可以成比例地減少。
4
混合專家(MoE)
混合專家(MoE)模型是指,對於任意輸入只用一小部分網路用於計算其輸出。在擁有多組權重的情況下,網路可以在推理時通過門控機制選擇要使用的一組權重,這可以在不增加計算成本的情況下獲得更多引數。
每組權重都被稱為“專家(experts)”,理想情況是,網路能夠學會為每個專家分配專門的計算任務。不同的專家可以託管在不同的GPU上,這也為擴大模型使用的GPU數量提供了一種明確的方法。
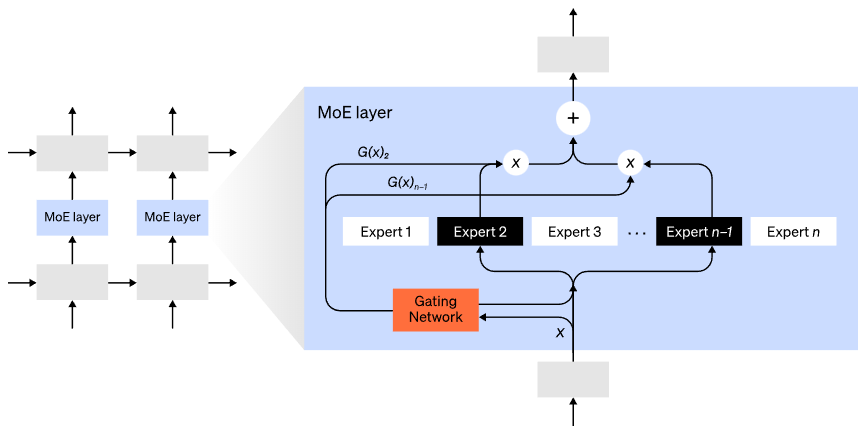
混合專家(MoE)層。門控網路只選擇了n個專家中的2個(圖片改編自:Shazeer et al., 2017)。
GShard將MoE Transformer擴充套件到6000億個引數,其中MoE layers被拆分到多個TPU上,其他layers是完全重複的。 Switch Transformer將輸入只路由給一個專家,將模型大小擴充套件到數萬億個引數,具有更高的稀疏性。
5
其他節省記憶體的設計
除了以上的並行策略,還有很多其他的計算策略可以用於訓練大規模神經網路:
-
要計算梯度,需要儲存原始啟用值,而這會消耗大量裝置視訊記憶體。 Checkpointing (也稱為啟用重計算)儲存啟用的任何子集,並在反向傳播時及時重新計算中間的啟用。這可以節省大量記憶體,而計算成本最多就是增加一個完整的前向傳遞。還可以通過選擇性啟用重計算( http://arxiv.org/abs/2205.05198 )在計算和記憶體成本之間不斷權衡,也就是對那些儲存成本相對較高但計算成本較低的啟用子集進行檢查。
-
混合精度訓練 ( http://arxiv.org/abs/1710.03740 )是使用較低精度的數值(通常為FP16)來訓練模型。現代加速器可以用低精度的數值完成更高的FLOP計數,同時還可以節省裝置視訊記憶體。處理得當的話,幾乎不會損失生成模型的精度。
-
Offloading 是將未使用的資料臨時解除安裝到CPU或其他裝置上,在需要時再將其讀回。樸素實現會大幅降低訓練速度,而複雜的實現會預取資料,這樣裝置不需要再等待資料。其中一個實現是ZeRO( http://arxiv.org/abs/1910.02054 ),它將引數、梯度和優化器狀態分割到所有可用硬體上,並根據需要將它們實現。
-
記憶體效率優化器 可減少優化器維護的執行狀態的記憶體,例如Adafactor。
-
壓縮 可用於儲存網路的中間結果。例如,Gist可以壓縮為反向傳遞而儲存的啟用;DALL·E可以在同步梯度之前壓縮梯度。
(原文:
http://openai.com/blog/techniques-for-training-large-neural-networks/)
其他人都在看
歡迎下載體驗OneFlow v0.7.0:http://github.com/Oneflow-Inc/oneflow

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- 左益豪:用程式碼創造一個新世界|OneFlow U
- OneFlow原始碼解析:運算元指令在虛擬機器中的執行
- OneFlow原始碼解析:Op、Kernel與直譯器
- 18張圖,直觀理解神經網路、流形和拓撲
- 一種分散式深度學習程式設計新正規化:Global Tensor
- OneFlow v0.8.0正式釋出
- OneFlow原始碼一覽:GDB編譯除錯
- 大模型訓練難於上青天?效率超群、易用的“李白”模型庫來了
- 平行計算的量化模型及其在深度學習引擎裡的應用
- Geoffrey Hinton:我的五十年深度學習生涯與研究心法
- 圖解OneFlow的學習率調整策略
- 鍾珊珊:被爆錘後的工程師會起飛|OneFlow U
- 深度學習概述:從基礎概念、計算步驟到調優方法
- 訓練千億引數大模型,離不開四種GPU並行策略
- 一個運算元在深度學習框架中的旅程
- 一個運算元在深度學習框架中的旅程
- 李飛飛:我更像物理學界的科學家,而不是工程師|深度學習崛起十年
- 一個運算元在深度學習框架中的旅程
- 關於併發和並行,Go和Erlang之父都弄錯了?
- LLVM之父Chris Lattner:模組化設計決定AI前途,不服來辯