GPU利用率接近100%!——vGPU在推理過程應用

vGPU torchserve/tfserving latency指標專項性能測試
上篇介紹了 vGPU device plugin for Kubernetes 組件,可實現在k8s集羣裏即插即用,無需更改代碼,即可實現GPU虛擬化(詳細請閲讀http://my.oschina.net/u/5259489/blog/5137710 )。這個組件尤其適合在機器學習推理過程使用,今天介紹下關於torchserve/tfserving 過程延遲等方面的測試結果。
開源地址:http://github.com/4paradigm/k8s-device-plugin
測試目的:
在一張GPU卡虛擬成多張GPU卡的時候,服務因虛擬化對latency造成的影響。尤其是當服務眾多時,驗證通過內存置換顯存所帶來的overhead。
測試結論:
在GPU使用率低於30%的情況下,對延遲的影響很低。使用率在30%到50%之間時,有一定 的影響,大部分場景可接受,在使用率超過50%,服務會受到較大影響,對於時效性要求不高 的場景,有時仍可接受。如果可接受時效性的部分損失,可將GPU利用率提升接近百分之百。
測試方法:
此實驗與多卡無關,所以可以只使用一張卡進行驗證,故以下測試均假設機器只有一張卡。
任務描述:
每個任務為一個deployment,每個replica一個pod,一個pod內有兩個container。 container1是模型服務,分別是tf-serving和torch-serve, container2是jmeter,用來給同屬於自己的pod的container1以固定的qps發壓,同時打印日 志記錄latency等信息。
注意:(這些magic已經在yml的cmd裏了)
注意jmeter的cmd,程序開始先sleep 15s,確保服務已經啟動,如果pull鏡像太慢 的,15s可能不夠程序開始時,需要先發一個請求,預熱服務 需要隨機sleep一段時間,避免所有請求非常整齊的提交,造成GPU瞬時被打滿。
對照組
對照組不做虛擬化,故replica設置為1,設置合理的發送頻率,同時通過nvidia-smi 或者其他方式記錄顯卡利用率,儘量確保GPU的平均利用率不超過30%,記錄下此時的latency為 $lat_1$ ms,QPM(每分鐘請求數)為$qpm_1$。
實驗組
將此卡虛擬 $ n $ 份,例如 $n=10$,對於16G顯存的卡,我們不建議超過10,同時設置任務的replica $m(m \le n)$,調整QPM讓GPU利用率儘量不超過30%(超過了要有latency變高的心理預期),為了公平也可以設置為$qpm_1 / m$,計算得到latency為$lat_M$ ms,對比 $lat_M$與 $lat_1$,期望差距不會顯著增大。
測試用例:
模型列表
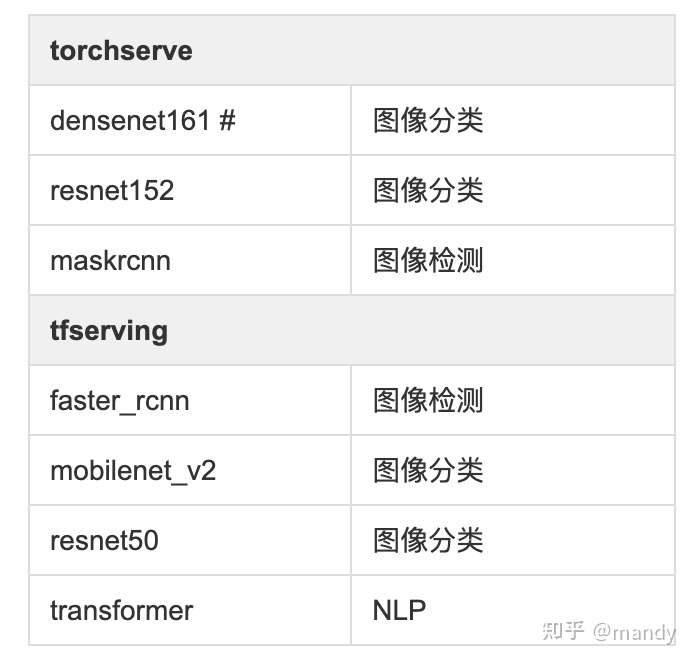
鏡像説明:
| 鏡像 | 説明 | | 4pdosc/tf-serving-benchmark | 這個鏡像基於tf-serving 2.0.0-gpu,內置了4個模型,給定環境變量 MODEL_NAME=XXX 即可serve對應模型 | | 4pdosc/torch-serve-benchmark | 這個鏡像基於torch-serve:gpu-latest,內置了3個模型,給定環境變量 MODEL_NAME=XXX 即可serve對應模型 | | 4pdosc/jmeter-benchmark | 這個鏡像可以發出對應的模型的請求,並打印每個請求的latency等信息,配置參考yaml的環境變量的説明 |
k8s yml以及腳本使用説明:
apiVersion: apps/v1
kind: Deployment
metadata:
name: serving-benchmark
spec:
selector:
matchLabels:
app: serving-benchmark
# 副本數,如果該Node有多張卡,最好讓副本數等於的該Node的所有虛擬卡,保證均勻
# 確保機器內存夠用,tf-serving有時會直接佔滿整張卡,加上limit限制
replicas: 1
template:
metadata:
labels:
app: serving-benchmark
spec:
containers:
- name: serving
image: goblin911/tf_serving_benchmark # 這是dockerhub鏡像,下載後改成內網鏡像
imagePullPolicy: Always
env:
- name: MODEL_NAME
value: resnet50
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
- name: jmeter
image: goblin911/jmeter # 這是dockerhub鏡像,下載後,改成內網鏡像
env:
- name: JMETER_CONFIG_QPM # 每分鐘請求數,根據使用率等酌情修改
value: "60"
- name: MODEL_NAME
value: resnet50
- name: JMETER_CONFIG_DUR_SEC # 測試時間,單位是秒,建議5分鐘以上
value: "300"
command: ["/bin/sh", "-c", "sleep 15; jmeter -n -t tfserving.jmx -JpayloadFile=tfserving/${MODEL_NAME}.json -Jmodel=${MODEL_NAME} -Jduration=1; sleep $((${RANDOM}%10)).${RANDOM}; jmeter -n -t tfserving.jmx -JpayloadFile=tfserving/${MODEL_NAME}.json -Jmodel=${MODEL_NAME} -Jqpm=${JMETER_CONFIG_QPM} -Jduration=${JMETER_CONFIG_DUR_SEC} -l ./result.jtl && ls -ahl && cat ./result.jtl ; sleep infinity"]
workingDir: /test
另外,壓縮包還內置了 calc.sh 與 print_log.sh,calc.sh會獲取namespace下所有的pod的log(請修改腳本第一行),最終計算出平均latency,tp50,tp90,tp99,這幾個latency。print_log.sh會直接打印所有相關log用於debug(當心刷屏)。
測試結果:
測試環境:
centos7 3.10.0-1127.19.1.el7.x86_64
40 cores
1 * T4
Driver Version: 450.51.05
CUDA Version: 11.0
結果:
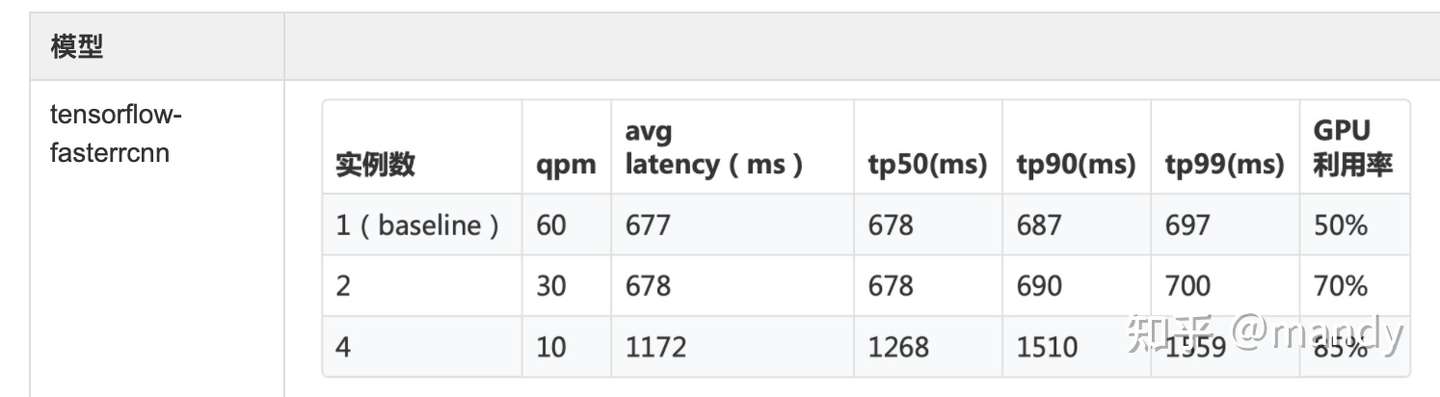
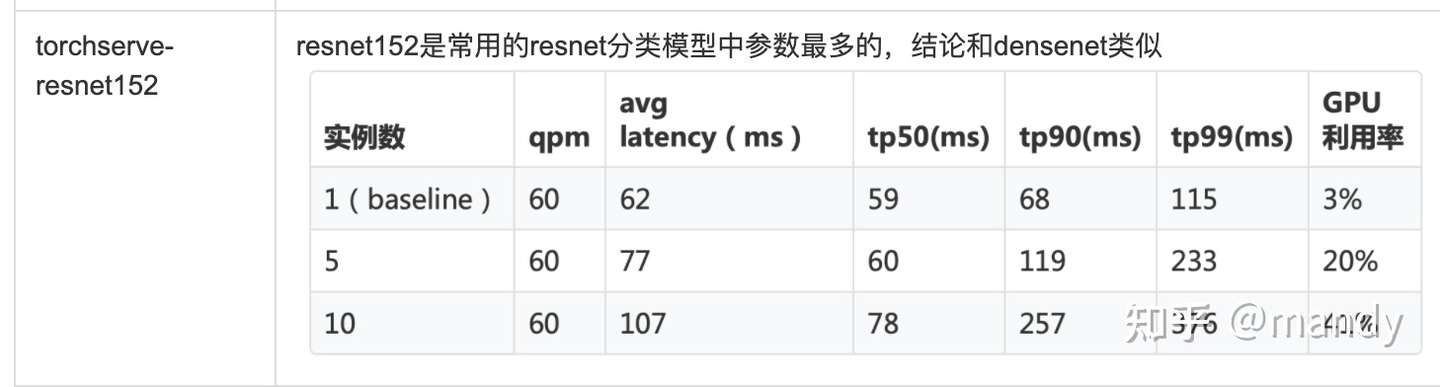
注:復現時,注意調整QPM,因為fasterrcnn這個模型本身計算很重,單併發的延遲已經到達 677ms,GPU達到60%的利用率,不降低QPM會直接導致GPU被打滿,latency也不再具有參 考意義。另,faster-rcnn是經過一系列優化後的模型,對顯存的訪問遠比計算重,這也是目前 對內存置換顯存overhead最大的case
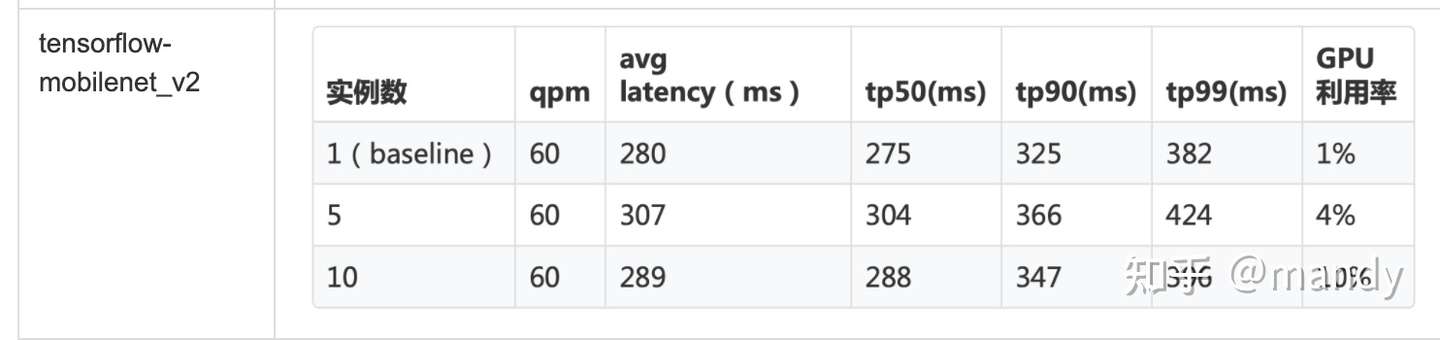
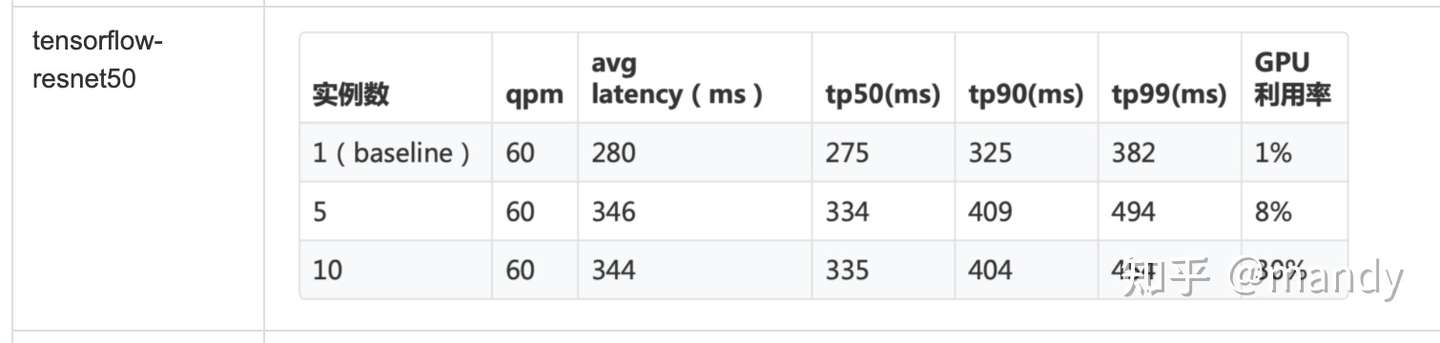
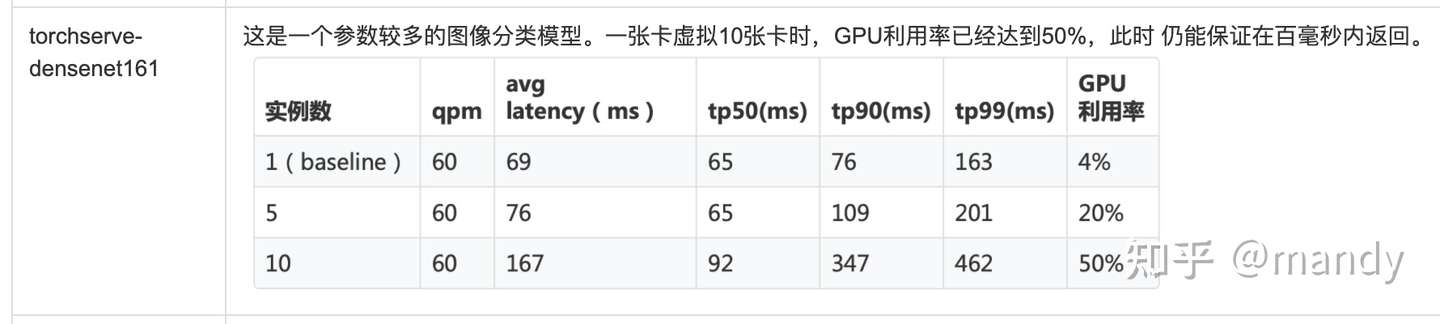
這是一個參數較多的圖像分類模型。一張卡虛擬10張卡時,GPU利用率已經達到50%,此時 仍能保證在百毫秒內返回。
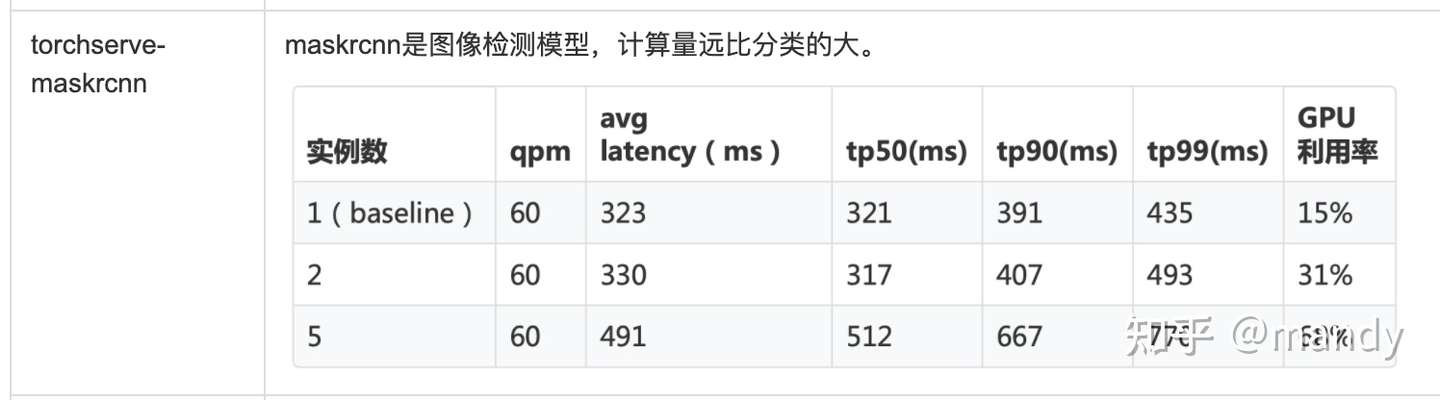
maskrcnn是圖像檢測模型,計算量遠比分類的大。
這個項目github地址:http://github.com/4paradigm/k8s-device-plugin