TiDB 故障診斷與效能排查:發生即看見,一切可回溯,Continuous Profiling 應用實踐

在企業遭遇的 IT 故障中,約有 30% 與資料庫相關。當這些故障涉及到應用系統、網路環境、硬體裝置時,恢復時間可能達到數小時,對業務連續性造成破壞,影響使用者體驗甚至營收。在複雜分散式系統場景下,如何提高資料庫的可觀測性,幫助運維人員快速診斷問題,優化故障處理流程一直是困擾著企業的一大難題。
一次海量資料場景下的效能排查經歷
沒有 Continuous Profiling 的客戶故障排查案例
-
19:15 新節點上線
-
19:15 - 19:32 上線的節點由於 OOM 反覆重啟,導致其他節點上 snapshot 檔案積累,節點狀態開始異常
-
19:32 收到響應時間過長業務報警
-
19:56 客戶聯絡 PingCAP 技術支援,反映情況如下:
-
-
叢集響應延遲很高,一個 TiKV 節點加入集群后發生掉量,而後刪除該節點,但其他 TiKV 節點出現 Disconnect Store 現象,同時發生大量 Leader 排程,叢集響應延遲高,服務掛掉
-
-
20:00 PingCAP 技術支援上線排查
-
20:04 - 21:08 技術支援對多種指標進行排查,從 metrics 的 iotop 發現 raftstore 執行緒讀 io 很高,通過監控發現有大量的 rocksdb snapshot 堆積,懷疑是 region snapshot 的生成導致的,建議使用者刪掉之前故障 TiKV 節點上的 pending peer,並重啟叢集
-
20:10 - 20:30 技術支援同時對 profiling 資訊排查,抓取火焰圖,但因為抓取過程中出問題的函式沒有執行,沒有看到有用的資訊
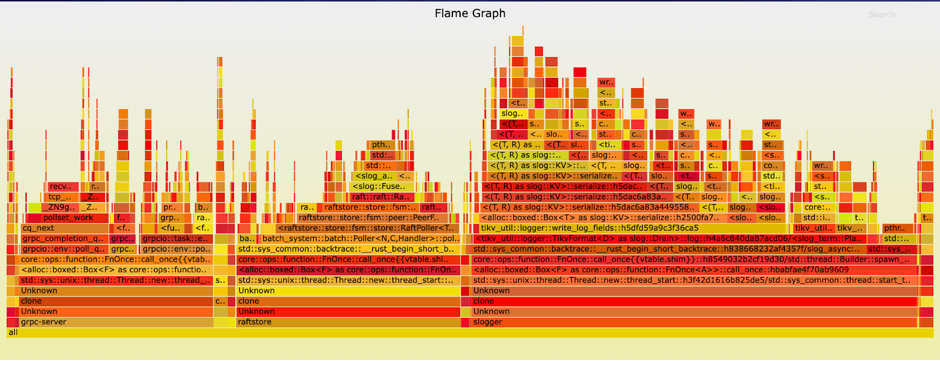
火焰圖的檢視方式:(源自:http://www.brendangregg.com/flamegraphs.html)
y 軸表示呼叫棧,每一層都是一個函式。呼叫棧越深,火焰就越高,頂部就是正在執行的函式,下方都是它的父函式。
x 軸表示抽樣數,如果一個函式在 x 軸佔據的寬度越寬,就表示它被抽到的次數多,即執行的時間長。注意,x 軸不代表時間,而是所有的呼叫棧合併後,按字母順序排列的。火焰圖就是看頂層的哪個函式佔據的寬度最大。只要有 "平頂"(plateaus),就表示該函式可能存在效能問題。顏色沒有特殊含義,因為火焰圖表示的是 CPU 的繁忙程度,所以一般選擇暖色調。
從以上檢視方式可以發現,這次抓取到的火焰圖並沒有一個大的 “平頂”,所有函式的寬度(執行時間長)都是不會太大。在這個階段,沒能直接從火焰圖發現效能瓶頸是令人失望的。這時候客戶對於恢復業務已經比較著急。
-
21:10 通過刪除 pod 的方式重啟了某個 TiKV 節點之後,發現 io 並沒有降下來
-
21:10 - 21:50 客戶繼續嘗試通過刪除 pod 的方式重啟 TiKV 節點
-
21:50 再次抓取火焰圖,發現 raftstore::store::snap::calc_checksum_and_size 函式處佔用的大量的 CPU,確認根因
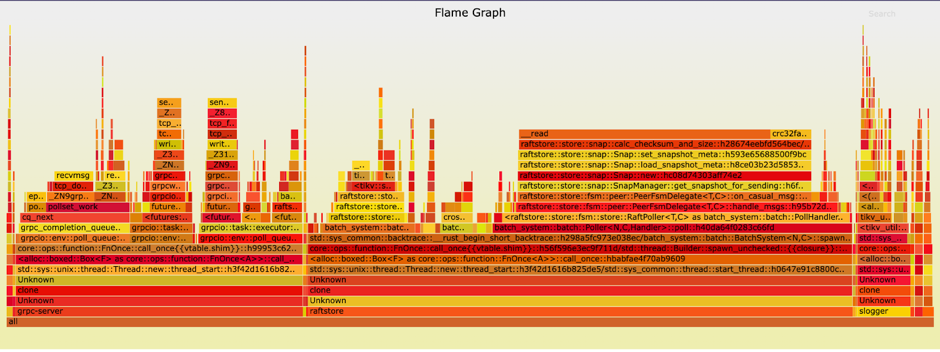
這次抓取到的火焰圖發現一個明顯的 “大平頂”,可以明顯看到是 raftstore::store::snap::calc_checksum_and_size 函式。這個函式佔用了大量的 CPU 執行時長,可以確定整體效能瓶頸就在這裡函式相關的功能。到這一步,我們確定了根因,並且也可以根據根因確定恢復方案。
-
22:04 採取操作:停止 TiKV pod,刪除流量大的 TiKV 節點 snap 資料夾下所有 gen 檔案。目前逐漸恢復中
-
22:25 業務放量,QPS 恢復原先水平,說明操作有效
-
22:30 叢集完全恢復
叢集恢復耗時:19:56 - 22:30,共 2 小時 34 分(154 分)。
確認根因,提出有效操作耗時:19:56 - 22:04,共 2 小時 8 分(128 分)。
在這個案例中,如果我們能夠有一個在故障前、中、後期,連續性地對叢集進行效能分析的能力,我們就可以直接對比故障發生時刻和故障前的火焰圖,快速發現佔用 CPU 執行時間較多的函式,極大節約這個故障中發現問題根因的時間。
因此,同樣的案例,如果有 Continuous Profiling 功能:
-
19:15 新節點上線
-
19:15 - 19:32 上線的節點由於 OOM 反覆重啟,導致其他節點上 snapshot 檔案積累,節點狀態開始異常
-
19:32 收到響應時間過長業務報警
-
19:56 客戶聯絡 PingCAP 技術支援,反映情況如下:
-
叢集響應延遲很高,一個 TiKV 節點加入集群后發生掉量,而後刪除該節點,但其他 TiKV 節點出現 Disconnect Store 現象,同時發生大量 Leader 排程,叢集響應延遲高,服務掛掉
-
20:00 PingCAP 技術支援上線排查
-
20:04 - 20:40 技術支援對多種指標進行排查,從 metrics 的 iotop 發現 raftstore 執行緒讀 io 很高,通過監控發現有大量的 rocksdb snapshot 堆積,懷疑是 region snapshot 的生成導致的
-
20:10 - 20:40 技術支援同時對 continuous profiling 資訊排查,檢視故障發生時刻的多個火焰圖,與未發生故障的正常火焰圖對比,發現 raftstore::store::snap::calc_checksum_and_size 函式佔用的大量的 CPU,確認根因
-
20:55 採取操作:停止 TiKV pod,刪除流量大的 TiKV 節點 snap 資料夾下所有 gen 檔案。目前逐漸恢復中
-
21:16 業務放量,QPS 恢復原先水平,說明操作有效
-
21:21 叢集完全恢復
叢集恢復(預期)耗時:19:56 - 21:21,共 1 小時 25 分(85 分),相比下降 44.8%。
確認根因,提出有效操作(預期)耗時:19:56 - 20:55,共 59 分,相比下降 53.9%。
可以看到該功能可以極大縮短確定根因時間,儘可能幫助客戶挽回因效能故障造成的業務停擺損失。
“持續效能分析” 功能詳解
在剛剛釋出的 TiDB 5.3 版本中,PingCAP 率先在資料庫領域推出 “持續效能分析”(Continuous Profiling)功能(目前為實驗特性),跨越分散式系統可觀測性的鴻溝,為使用者帶來資料庫原始碼水平的效能洞察,徹底解答每一個數據庫問題。“持續效能分析”是一種從系統呼叫層面解讀資源開銷的方法,通過火焰圖的形式幫助研發、運維人員定位效能問題的根因,無論過去現在皆可回溯。
持續效能分析以低於 0.5% 的效能損耗實現了對資料庫內部執行狀態持續打快照(類似 CT 掃描),以火焰圖的形式從系統呼叫層面解讀資源開銷,讓原本黑盒的資料庫變成白盒。在 TiDB Dashboard 上一鍵開啟持續效能分析後,運維人員可以方便快速地定位效能問題的根因。
火焰圖示例
主要應用場景
當資料庫意外宕機時,可降低至少 50% 診斷時間
在網際網路行業的一個案例中,當客戶叢集出現報警業務受影響時,因缺少資料庫連續效能分析結果,運維人員難以發現故障根因,耗費 3 小時才定位問題恢復叢集。如果使用 TiDB 的持續效能分析功能,運維人員可比對日常和故障時刻的分析結果,僅需 20 分鐘就可恢復業務,極大減少損失。
在日常執行中,可提供叢集巡檢和效能分析服務,保障叢集持續穩定執行
持續效能分析是 TiDB 叢集巡檢服務的關鍵,為商業客戶提供了叢集巡檢和巡檢結果資料上報。客戶可以自行發現和定位潛在風險,執行優化建議,保證每個叢集持續穩定執行。
在資料庫選型時,提供更高效的業務匹配
在進行資料庫選型時,企業往往需要在短時間內完成功能驗證、效能驗證的流程。持續效能分析功能能夠協助企業更直觀地發現效能瓶頸,快速進行多輪優化,確保資料庫與企業的業務特徵適配,提高資料庫的選型效率。
深入瞭解和體驗 “持續效能分析”:http://docs.pingcap.com/zh/tidb/stable/continuous-profiling
- 基於tidbV6.0探索索引優化思路
- TiDB HTAP特性的應用場景簡析
- 記憶體悲觀鎖
- 用一個性能提升了666倍的小案例說明在TiDB中正確使用索引的重要性
- TiDB 6.0 新特性解讀 | Collation 規則
- 一個小操作,SQL查詢速度翻了1000倍。
- 中國技術出海,TiDB 資料庫海外探索之路 | 卓越技術團隊訪談錄
- 一個小操作,SQL查詢速度翻了1000倍。
- TiDB 查詢優化及調優系列(三)慢查詢診斷監控及排查
- TiDB 查詢優化及調優系列(三)慢查詢診斷監控及排查
- TiDB 查詢優化及調優系列(二)TiDB 查詢計劃簡介
- TiFlash 原始碼閱讀(一) TiFlash 儲存層概覽
- 簡單瞭解 TiDB 架構
- Oceanbase和TiDB粗淺對比之 - 執行計劃
- TiKV 縮容不掉如何解決?
- 簡單瞭解 TiDB 架構
- Oceanbase 和 TiDB 粗淺對比之 - 執行計劃
- TiDB 6.0 的「元功能」:Placement Rules in SQL 是什麼?
- TiDB 在連鎖快餐企業丨海量交易與實時分析的應用探索
- 對Indexlookup的理解誤區