推理加速性能超越英偉達FasterTransformer 50%,開源方案打通大模型落地關鍵路徑

AI大模型推理部署的困難
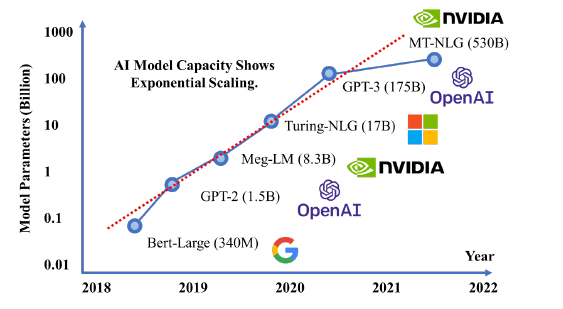
模型參數的迅速增長[http://arxiv.org/abs/2111.14247]
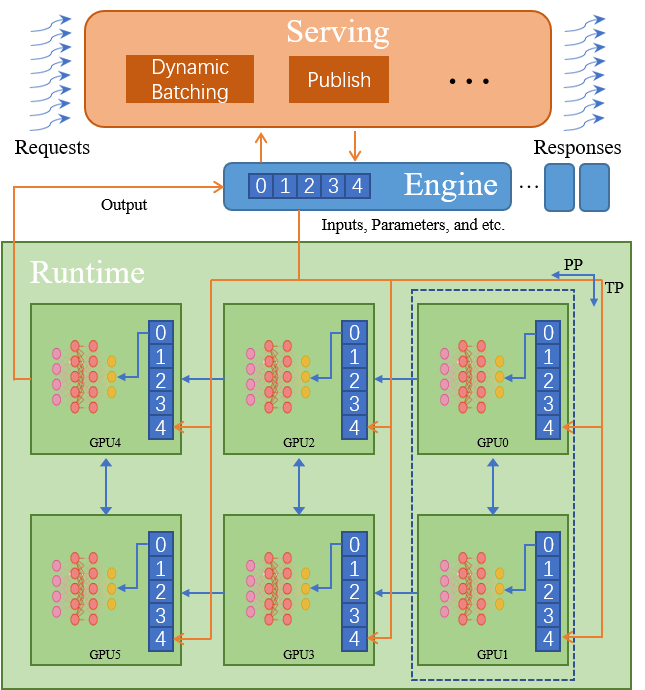
- Runtime:在運行時系統設計過程中我們發現,當模型規模不斷增大,通用矩陣乘的時間佔比逐漸增大,而訪存密集型算子與Kernel Launch的時間佔比則逐漸降低,推理過程進一步從訪存密集型向計算密集型方向遷移,TensorRT以及專用推理系統對訪存密集型操作的優化效果被極大削減。Energon-AI Runtime依賴於Colossal-AI實現張量並行,同時設計了流水線並行包裝方法用於顯存不足的情況。此外,我們引入了大量推理專用算子及方法。如,面對NLP中輸入變長的特點,我們引入了transpose_padding_rebulid與transpose_padding_remove等算子用以高效支持Encoder和Decoder模型中MLP層的宂餘計算消除方法。
- Engine:單設備推理中程序有相同的數據入口與出口,分佈式訓練的主要目標是模型參數,因此無須對多個進程的輸入輸出進行管理,而多設備推理則不同。我們希望通過良好的封裝使得Engine具有與單設備推理完全相同的行為。我們採用了半中心化方法,主進程中使用RPC在每個設備調用初始化或推理方法,使得分佈式推理可以得到中心化的控制,同時每個設備則保有自己的Tensor Parallel與Pipeline Parallel通信邏輯。我們在每個進程中設計並維護了分佈式消息隊列,用以保證多個進程中多線程調用執行的一致性。
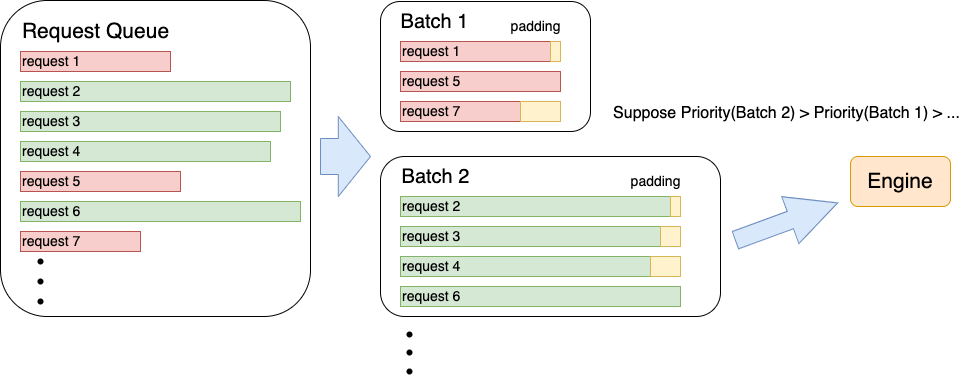
- Serving:針對用户請求分散和變長的特點及大模型推理對GPU並行運算的依賴之間的矛盾,Energon-AI引入了動態Batching機制,將請求隊列中的請求按照機器性能進行最優打包後,根據等候時間、batch大小、batch的擴展可能性(根據padding後的句子長度)等挑選優先級最高的batch處理,最大化GPU使用率的同時規避飢餓問題,減小平均請求時延。
性能測試
並行推理超線性擴展
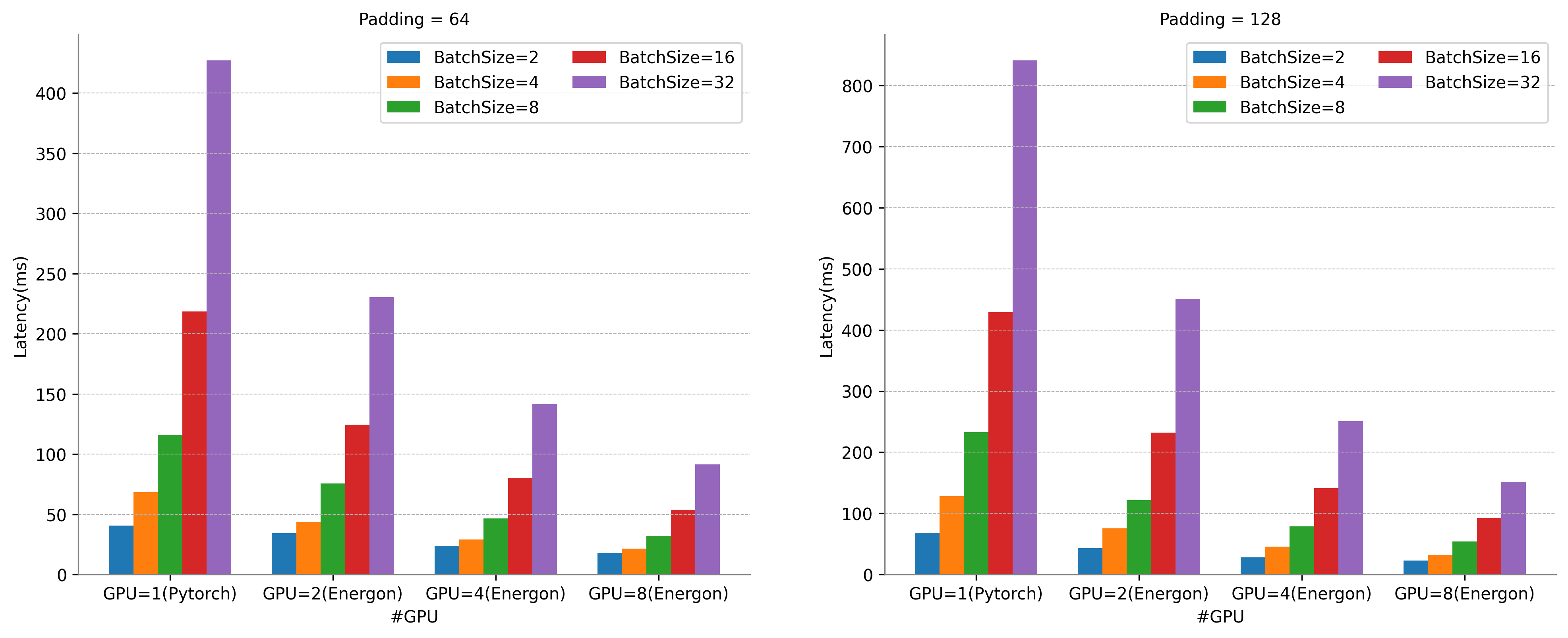
張量並行可擴展性測試結果展示。硬件環境:8 * A100 GPU 80GB。由於單設備顯存無法滿足GPT-3推理需求,此處為GPT-3 12層的測試結果,設置句長為Padding的1/2。
Energon-AI八卡並行推理在Batch Size為32時,相比於單卡Pytorch直接推理,可獲得8.5倍的超線性加速。
運行時推理性能提升50%
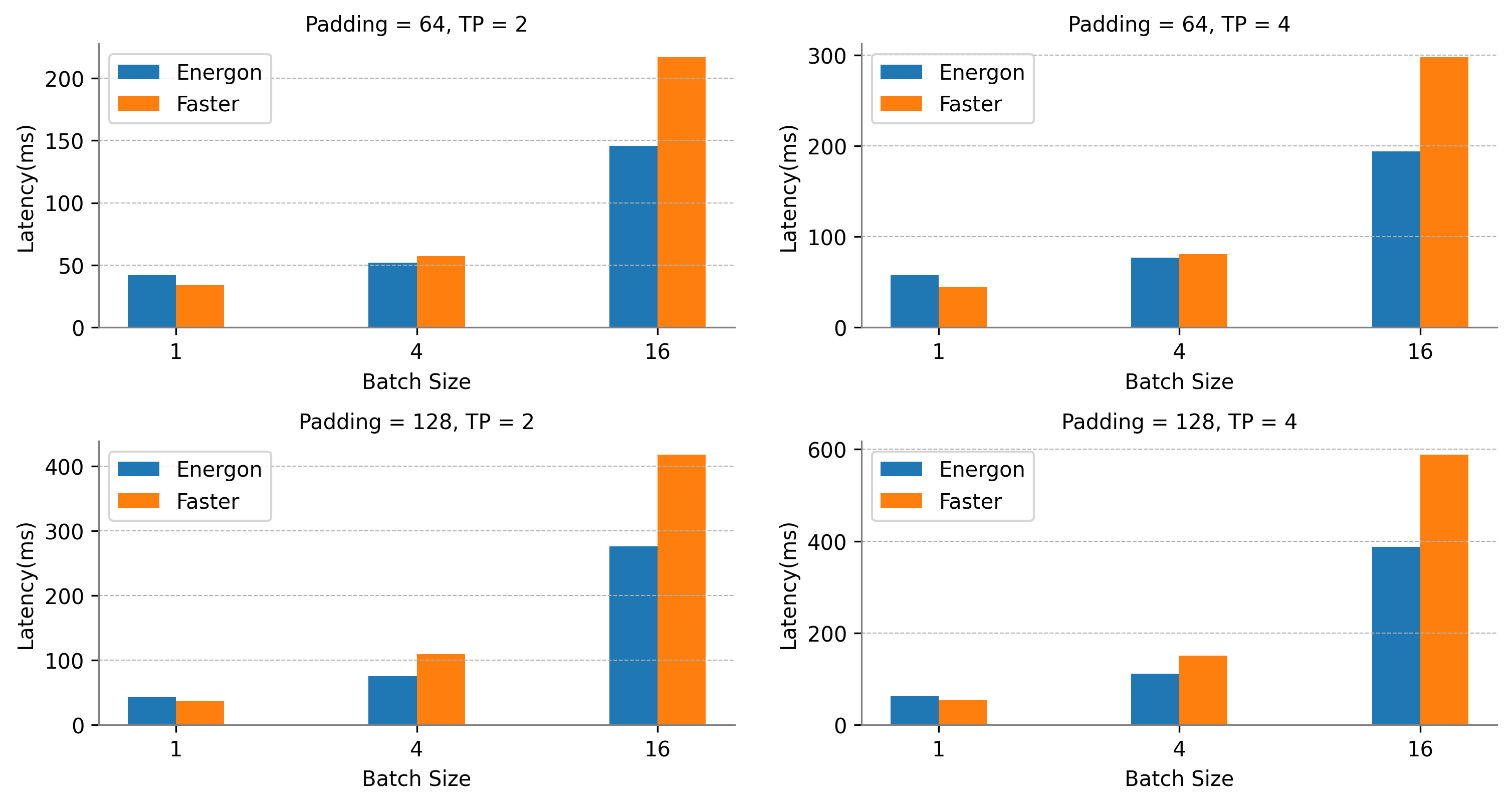
張量並行運行時系統推理時延對比。硬件環境:8 * A100 GPU 80GB。
設置句長為Padding的1/2。GPT-3-24-Layers for TP=2, GPT-3-48-Layers for TP=4。
我們選擇高度優化的英偉達FasterTransformer GPT-3作為對比方案。FasterTransformer在其4.0版本中推出了分佈式推理特性,目前支持GPT-3模型的分佈式推理,但由於其純C++代碼高度耦合的特點,靈活度與易用性相對較低。此外,對於NLP推理輸入句長不同的特點,其分佈式推理無宂餘計算消除功能。
對於GPT-3模型,Energon-AI的運行時系統在Batch Size為1時性能略低於FasterTransformer,而在Batch Size較大時能夠實現超過50%的性能提升。
Dynamic Batching吞吐量增加30%
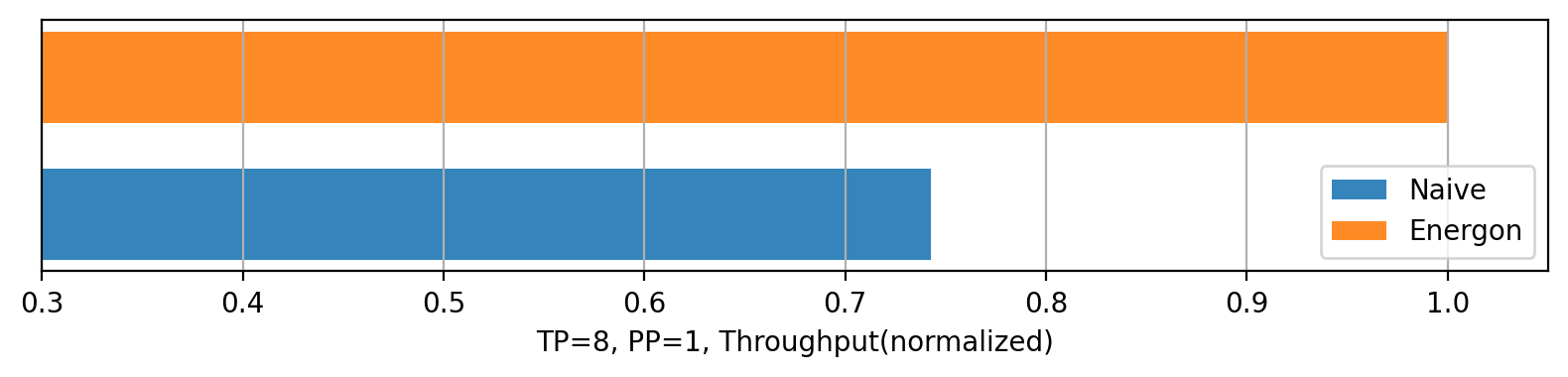
Dynamic batching與直接打包batch吞吐量對比。硬件環境:8 * A100 GPU 80GB。測試使用的模型為GPT-3, 測試句長為256以內隨機生成,padding策略為batch內最長padding。
我們模擬真實場景下多用户同時發送大量變長推理請求的情況,將我們的動態batch規劃方法與傳統的FIFO(先入先出)隊列打包方法進行了吞吐量對比。由於dynamic batching的算法緩解了直接padding造成的大量宂餘計算問題,在該策略下dynamic batching的吞吐量實現了34.7%的提升。
易用性
from gpt import gpt3
from gpt_server import launch_engine
# for engine
model_class = gpt3
model_type = "gpt"
host = "127.0.0.1"
port = 29400
half = True
backend = "nccl"
# for parallel
tp_init_size = 4
pp_init_size = 2
# for server
engine_server = launch_engine
server_host = "127.0.0.1"
server_port = 8020
rm_padding = Trueenergonai service init --config_file=gpt_config.py在追求性能的同時,Energon-AI希望保持系統使用的靈活度與易用性,用户僅需自定義【並行模型】、【並行參數】以及【服務請求邏輯】加入到配置文件中,即可啟動推理服務。目前,我們提供了最常見的GPT、BERT和ViT模型作為示例,更詳盡的教程將會在近期完善。
在構建新的並行模型時,Energon-AI使用Python,且使用方式與Pytorch相似,有層的概念且初始化與執行邏輯清晰,用户無需考慮內存管理,並行通信等行為。如下代碼展示了兩層Linear層組成的模型並行運行的完整代碼。
class MLP(nn.Module):
def __init__(self, dim, dtype, bias):
super().__init__()
self.dense_0 = Linear1D_Col(dim, dim, dtype=dtype, bias=bias, gather_output=False)
self.dense_1 = Linear1D_Row(dim, dim, dtype=dtype, bias=bias, parallel_input=True)
def forward(self, x):
x = self.dense_0(x)
x = self.dense_1(x)
return x與之相對,在構建新的並行模型時,FasterTransformer需要使用C++代碼並且需要用户自行進行內存管理,定義通信等底層行為組織。受篇幅限制,如下代碼展示兩層Linear層模型並行運行的內存管理,具體執行,通信的部分代碼。除此之外,用户想要代碼正確執行,還需要花費大量時間精力對內存管理、執行邏輯、通信行為之間的配合進行調試,C++代碼還需要額外編譯工作。這些都對用户的並行知識與編程能力提出了嚴峻挑戰。
// Memory Allocation (only for a single paramerter).
T *d_inter_kernel = NULL
param_.ffn.intermediate_weight.kernel = d_inter_kernel;
device_malloc(&d_inter_kernel, dim * dim);
// Two MLP Layers
cublasMM_cublasLtMM_wrapper(param_.cublaslt_handle, param_.cublas_handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, param_.ffn.intermediate_weight.kernel, AType_, n, attr_matmul_buf_, BType_, k, &beta, (DataType_ *)inter_matmul_buf_, CType_, n, param_.stream, cublasAlgoMap_, sm_, cublas_workspace_);
add_bias_act_kernelLauncher<DataType_>(inter_matmul_buf_, param_.ffn.intermediate_weight.bias, m, n, ActivationType::GELU, param_.stream);
n = k;
cublasMM_cublasLtMM_wrapper(param_.cublaslt_handle, param_.cublas_handle, CUBLAS_OP_N, CUBLAS_OP_N, n, m, k, &alpha, param_.ffn.output_weight.kernel, AType_, n, inter_matmul_buf_, BType_, k, &beta, (DataType_ *)(param_.transformer_out), CType_, n, param_.stream, cublasAlgoMap_, sm_, cublas_workspace_);
add_bias_input_layernorm_kernelLauncher<DataType_>(param_.transformer_out, attr_matmul_buf_, param_.ffn.output_weight.bias, param_.ffn_layernorm.gamma, param_.ffn_layernorm.beta, m, n, param_.stream);
// Communication
if(t_parallel_param_.world_size > 1)
{
all2all_gather(nccl_logits_buf_, nccl_logits_buf_, local_batch * n, t_parallel_param_, decoding_params.stream);
}更多特性
本次發佈的Energon-AI子系統為beta版,近期會根據用户反饋與既定計劃,進行密集的迭代更新,儘早為用户提供正式版,充分滿足用户的不同推理部署需求,歡迎向Energon-AI提出您的需求與建議。
構建AI大模型生態系統
面對AI大模型的時代浪潮,除了本次新增的推理部署特性,針對現有大模型訓練方案並行維度有限、效率不高、通用性差、部署困難、缺乏維護等痛點,Colossal-AI通過高效多維並行和異構並行等技術,讓用户僅需極少量修改,即可高效快速部署AI大模型訓練。
例如對於GPT-3這樣的超大AI模型,相比英偉達方案,Colossal-AI僅需一半的計算資源,即可啟動訓練;若使用相同計算資源,則能提速11%,可降低GPT-3訓練成本超百萬美元。

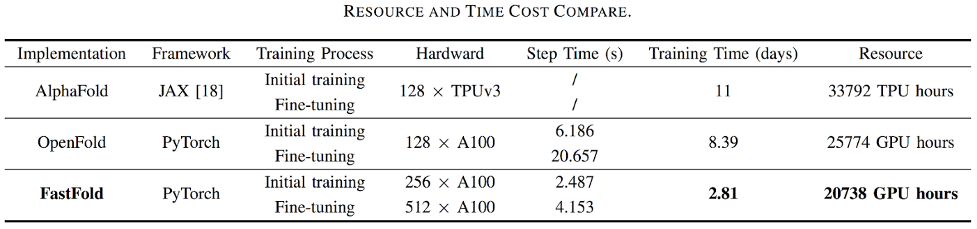
對於蛋白質結構預測應用AlphaFold,基於Colossal-AI的加速方案的FastFold,成功超越谷歌和哥倫比亞大學的方案,將AlphaFold訓練時間從11天減少到67小時,且總成本更低,在長序列推理中也實現9.3~11.6倍的速度提升。
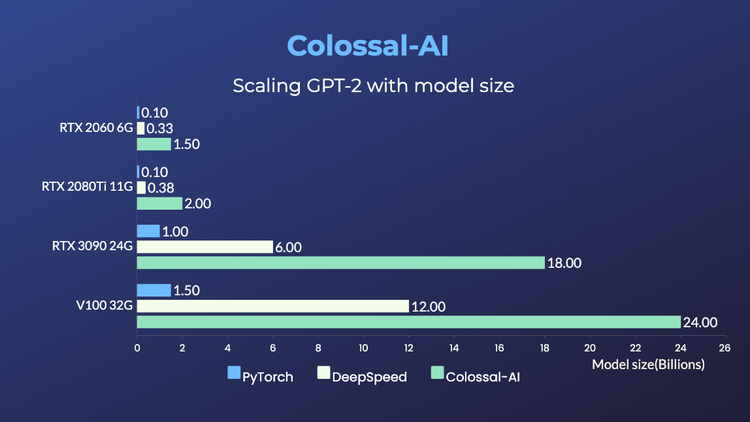
Colossal-AI兼容低端設備,在僅有一塊GPU的個人PC上便能訓練高達180億參數GPT;普通的筆記本電腦,也能訓練十幾億參數的模型,相比現有主流方案,可提升參數容量十餘倍,大幅度降低了AI大模型微調和推理等下游任務和應用部署的門檻。
Colossal-AI注重開源社區建設,提供中文教程,開放用户社羣及論壇,對於用户反饋進行高效交流與迭代更新,不斷添加等前沿特性。
自然開源以來,Colossal-AI已經多次登上GitHub熱榜Python方向世界第一,與眾多已有數萬star的明星開源項目一起受到海內外關注!
在反映機器學習領域熱點的Papers With Code網站上,Colossal-AI也廣受關注,榮登熱榜第一。
項目團隊

△潞晨科技創始人尤洋教授:加州大學伯克利分校博士、IPDPS/ICPP最佳論文、ACM/IEEE George Michael HPC Fellowship、福布斯30歲以下精英(亞洲 2021)、IEEE-CS超算傑出新人獎、UC伯克利EECS Lotfi A. Zadeh優秀畢業生獎 
△潞晨CSO Prof. James Demmel:加州大學伯克利分校傑出教授、ACM/IEEE Fellow,美國科學院、工程院、藝術與科學院三院院士
傳送門
- 開源方案復現ChatGPT流程!1.62GB顯存即可體驗,單機訓練提速7.73倍
- 硬件預算最高直降46倍!低成本上手AIGC和千億大模型,一行代碼自動並行,Colossal-AI再升級
- 潞晨科技完成600萬美元種子及天使輪融資,藍馳領投天使輪
- 無縫支持Hugging Face社區,Colossal-AI低成本輕鬆加速大模型
- 推理加速性能超越英偉達FasterTransformer 50%,開源方案打通大模型落地關鍵路徑
- 在個人電腦用單塊GPU帶動180億參數GPT!熱門開源項目再添新特性
- 使用Colossal-AI分佈式訓練BERT模型
- 使用Colossal-AI復現Pathways Language Model
- 霸榜GitHub熱門第一多日後,Colossal-AI正式版發佈
- 助力藥物研發,低成本加速AlphaFold訓練從11天到67小時,11倍推理加速——開源解決方案FastFold