vivo 推送平臺架構演進
本文根據Li Qingxin老師在“2021 vivo開發者大會"現場演講內容整理而成。公眾號回覆**【2021VDC】**獲取網際網路技術分會場議題相關資料。
一、vivo推送平臺介紹
1.1 從產品和技術角度瞭解推送平臺
推送平臺是做什麼的?
有的小夥伴可能瞭解過,有的可能是第一次接觸到。無論您是哪一種情況都希望通過今天的分享,能夠讓您對我們有新的瞭解。接下來我將從產品和技術兩個不同視角,給大家介紹vivo推送平臺。
首先,從產品角度來看,vivo推送平臺通過和系統的深度結合,建立穩定可靠、安全可控、支援每秒100w推送速度、億級使用者同時線上的訊息推送服務,幫助不同行業的開發者挖掘更多的運營價值。推送平臺的核心能力是利用長連線技術 ,以智慧裝置、手機為載體為使用者提供具備實時、雙向的內容和服務傳輸的能力。
所以如果你是運營人員,可以考慮使用我們推送平臺來運營你們在vivo 手機系統上的APP來提升你們APP的活躍和留存。對於推送平臺的本質是什麼?
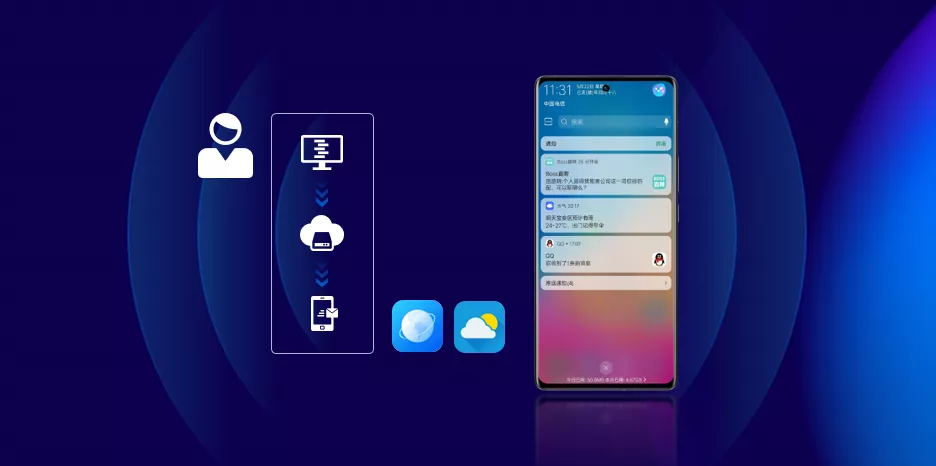
從技術角上來看,我們是一個通過TCP長連線,將訊息傳送給使用者的平臺。所以推送平臺的本質其實就是藉助網路通道,將訊息傳送到使用者裝置上。
大家日常都收到過快遞通知吧!當快遞員將快遞放到快遞櫃中,快遞後臺就會自動推送一條訊息,通知你有快遞。我相信,如果你是一位運營人員,你也會喜歡這種自動下發訊息高效的方式。大家感興趣的,可以在分享結束之後,通過vivo開放平臺入口,選擇訊息推送來更進一步瞭解我們。
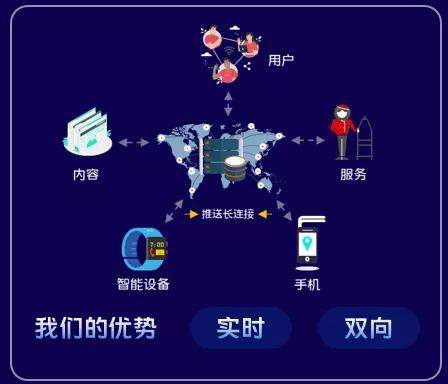
1.2 內容、服務、裝置互聯
在這個萬物互聯的時代,我們平臺也具備連線多的能力,我們通過長連線將內容、服務、使用者連在一起,將內容分發給使用者,為終端裝置提供實時、雙向通訊能力。
這裡有個概念長連線,那麼什麼是長連線?所謂的長連線就是,客戶端與服務端維持的一條,在相對較長的時間裡,都能夠進行網路通訊的網路連線(比如:基於TCP的長連線)。
為什麼我們要採用長連線而不是短連線作為平臺底層的網路通訊。
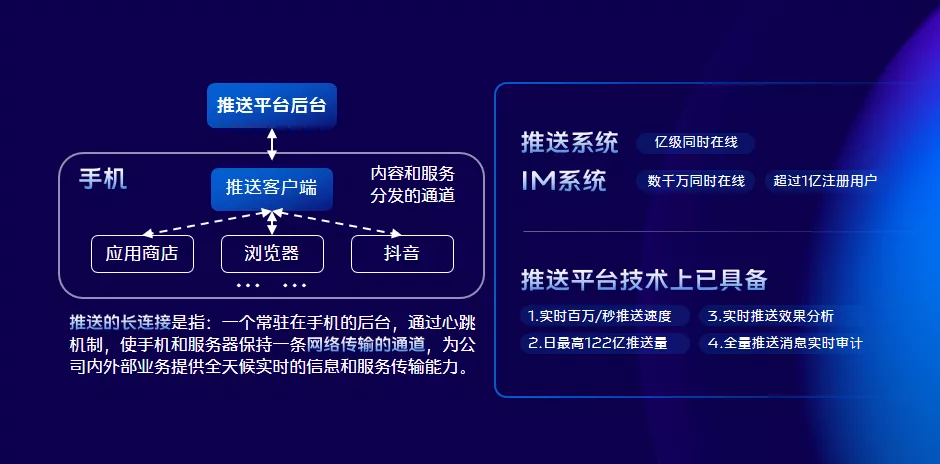
我們先來看看短連線下訊息下發的場景:使用短連線的方式就是輪詢,即客戶端定時的去詢問後臺有沒有裝置A的訊息,當有裝置A的訊息時後臺返回對應的訊息,可能很多情況下都是無功而返,浪費流量;當後臺有訊息需要傳送給裝置A時,因為裝置A沒有過來取導致訊息無法下發。而使用長連線,當有裝置A的訊息時後臺直接傳送給裝置A而不用等裝置A自己過拉取,所以長連線讓資料互動更加自然、高效;除此之外,我們平臺技術上還具備以下優勢:
-
超過億級裝置同時線上;
-
支援百萬每秒的推送速度;
-
支援每天超百億級的訊息吞吐量;
-
實時推送效果分析;
-
全量推送訊息實時審計。
我們推送平臺具備的這些能力能夠為訊息的時效性提供保障,我們平臺具備的這些能力是經過不斷的演進而來的,接下來跟大家分享vivo推送平臺的架構這幾年的變化。
二、vivo推送平臺架構演進
2.1 擁抱業務
IT領域的架構它是動態的,不同階段都可能會發生變化,而推動架構進行演進的推力,主要來自於業務需求,接下來我們一起來回顧,我們平臺的業務發展歷程。
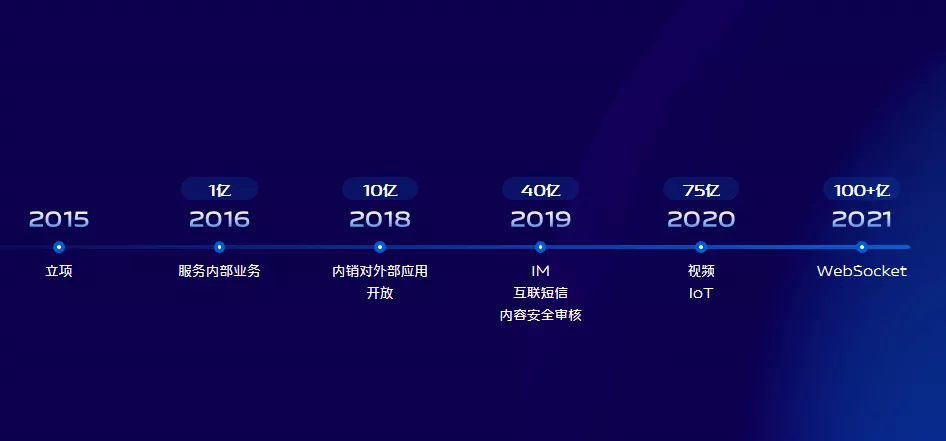
自2015年立項以來,隨著業務量增長,我們不斷為系統添磚加瓦,豐富整個系統的能力使其滿足不同的業務場景需求。比如支援內容完全稽核、支援IM、支援IoT、支援WebSocket 通訊等。
從圖上可以看到,我們業務量幾乎每年都有幾十億的增長,不斷攀高,給系統帶來了挑戰,原有的系統架構存在的問題,也逐漸浮出水面,比如延遲、效能瓶頸。架構服務於業務,2018年之前我們平臺所有服務都放在雲上,但是我們依賴的其他內部業務部署在自建機房。
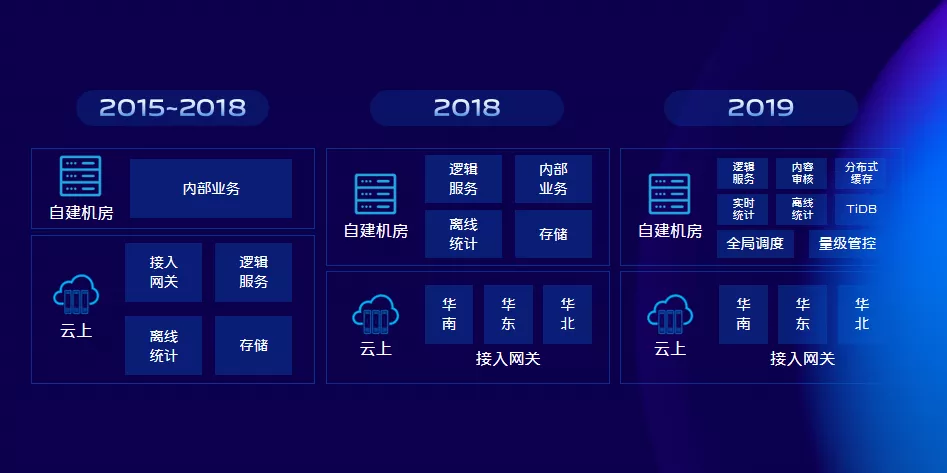
2.2 勇於改變
隨著業務量增長與自建機房的資料傳輸,已經出現了延遲的問題,並且在逐漸惡化,不利於我們平臺功能的拓展。所以在2018年下半年,我們對部署架構進行調整:將所有核心邏輯模組都遷移到自建機房,架構優化之後,資料延遲問題得到徹底解決。同時也為架構進一步演進奠定了基礎。從上面的圖中可以看到我們接入閘道器也進行優化三地部署。
為什麼要進行三地部署而不是更多區域部署呢?主要基於以下三點考慮:
-
第一是基於使用者分佈及成本的考慮;
-
第二是能為使用者提供就近接入;
-
第三是能夠讓接入閘道器具備一定容災能力。
大家可以設想下,如果沒有三地部署,接入閘道器機房故障時,那麼我們平臺就癱瘓了。
隨著我們平臺業務規模的進一步擴大,日吞吐量達到10億的量級,使用者對於時效性、併發要求越來越高,而我們2018年的邏輯服務的系統架構已經無法業務高併發的需求或者需要更高的伺服器成本才能滿足高併發需求。所以從平臺功能、成本優化出發,我們在2019年對系統進行了重構,為使用者提供更加豐富的產品功能及更穩定、更高效能的平臺。
2.3 利用長連線能力給業務賦能
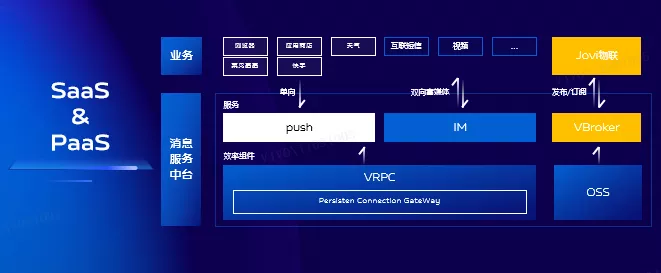
作為公司較大規模的長連線服務平臺,我們積累了非常豐富的長連線經驗。我們也一直在思考,如何讓長連線能力為更多業務賦能。我們平臺服務端各個模組之間通過RPC呼叫,這是一種非常高效的開發模式,不用每個開發人員都去關心底層網路層資料包的。
我們設想下,如果客戶端也能通過RPC呼叫後臺,這一定是非常棒的開發體驗。未來我們將會提供VRPC通訊框架,用於解決客戶端與後臺通訊及開發效率問題,為客戶端與後臺提供一致的開發體驗,讓更多的開發人員不再關心網路通訊問題,專心開發業務邏輯。
三、系統穩定性、高效能、安全
作為一個吞吐量超過百億的推送平臺其穩定性、高效能、安全都非常重要,那麼接下來和大家分享,我們在系統穩定性、高效能、安全方面的實踐經驗。
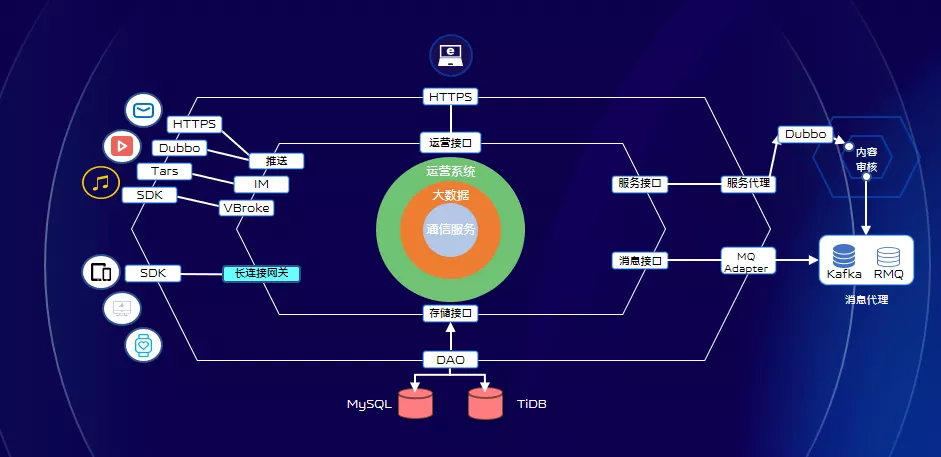
從上圖的領域模型可以看出,我們推送平臺以通訊服務作為核心能力,在核心能力的基礎上我們又提供了,大資料服務以及運營系統,通過不同介面對外提供不同的功能、服務。以通訊服務為核心的推送平臺,其穩定性和效能都會影響訊息的時效性。訊息的時效性是指,訊息從業務方發起用裝置收到的耗時,那麼如何衡量訊息的時效性呢?
3.1 監控與質量度量
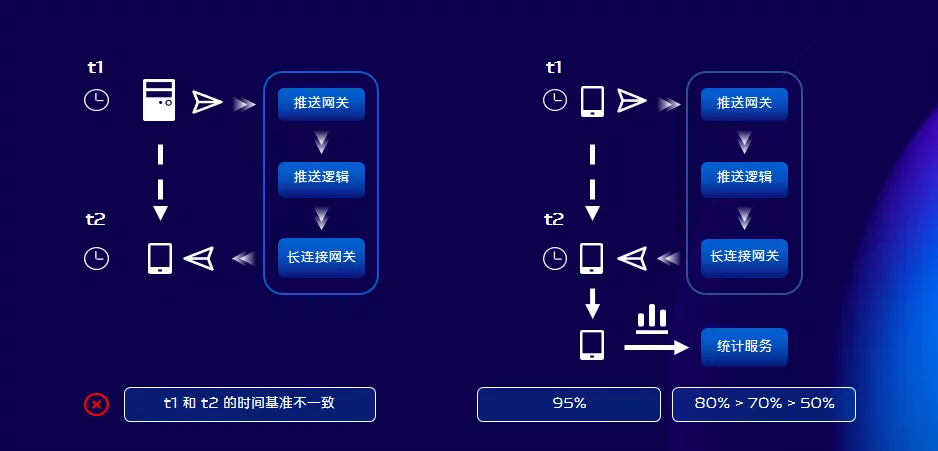
傳統的訊息時效性測量方法如左圖所示,傳送端和接收端在兩個裝置上,在傳送的時候取時間t1、在接收到訊息的時候取時間t2,這兩個時間相減得到訊息的耗時。但是這種方法並不嚴謹,為什麼呢?因為這兩個裝置的時間基準,很有可能是不一致的。我們採用的解決方案如右圖所示,將傳送端和接收端放在同一個裝置上,這樣就可以解決時間基準的問題。我們基於該方案,搭建了一套撥測系統,來主動監控訊息送達耗時分佈。
3.2 高效能、穩定的長連線閘道器
過去10年討論單機長連線效能時面對的是單機一萬連線的問題,作為一個上億級裝置同時線上的平臺,我們要面對的是單機100萬連線的問題。

作為長連線閘道器,主要職責是維護與裝置端的TCP連線及資料包轉發。對於長連線閘道器,我們應該儘可能使其輕量化,所以我們從架構設計、編碼、作業系統配置、以及硬體特性,自上而下穿透整個層次來進行重構優化。
-
調整系統最大檔案控制代碼數、單個程序最大的檔案控制代碼數;
-
調整系統網絡卡軟中斷負載均衡或者開啟網絡卡多佇列、RPS/RFS;
-
調整TCP相關引數比如keepalive(需要根據宿主機的session時間進行調整)、關閉timewait recycles;
-
硬體上使用AES-NI指令加速資料的加解密。
經過我們優化之後,線上8C32GB 的伺服器可以穩定支援170萬的長連線。

另外一大難點在於,連線保活,一條端到端的 TCP連線,中間經過層層路由器、閘道器,而每個硬體的資源都是有限的,不可能將所有TCP連線狀態都長期儲存。所以為了避免TCP資源,被中間路由器回收導致連線斷開,我們需要定時傳送心跳請求,來保持連線的活躍狀態。
心跳的傳送頻率多高才合適?傳送太快了會引起功耗、流量問題,太慢了又起不到效果,所以為了減少不必要的心跳及提升連線穩定性,我們採用智慧心跳,為不同網路環境採用差異性的頻率。
3.3 億級裝置負載均衡
我們平臺超過億級裝置同時線上,各個裝置連線長連線閘道器時是通過流量排程系統進行負載均衡的。當客戶端請求獲取IP時,流量排程系統會下發多個就近接入閘道器IP。

那麼排程系統是如何確保下發的ip是可用的呢?大家可以簡單思考下,而我們採用四種策略:就近接入 、公網探測 、 機器負載以及介面成功率。採用這幾種策略呢?大家可以想下,這兩個問題:
-
內網正常,公網就一定能聯通嗎?
-
連線數少伺服器,就一定是可用的嗎?
答案是否定的,因為長連線閘道器與流量排程系統是通過內網進行心跳保活的,所以在流量排程系統上看到的長連線閘道器是正常的,但是很有可能長連線閘道器公網連線是異常的比如沒有開通公網許可權等,所以我們需要結合多種策略,來評估節點的可用性,保障系統的負載均衡、為系統穩定性提供保障。
3.4 如何滿足高併發需求
有這麼一個場景:以每秒一千的推送速度,將一條新聞傳送給幾億使用者,那麼有的使用者可能是幾天後才收到這條訊息,這就非常影響使用者體驗,所以高併發對訊息的時效性來說是非常重要的。
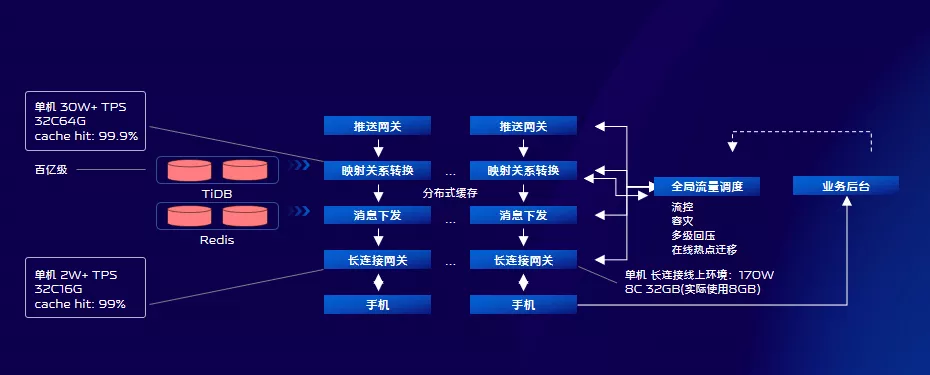
大家從圖上的推送流程來看,會不會覺得TiDB會成為推送的效能瓶頸?其實不會,初步看可能會覺得它們作為中心儲存,因為我們採用分散式快取,將中心儲存的資料,根據一定的策略快取到各個業務節點,充分利用伺服器資源,提升系統性能、吞吐量。我們線上的分散式快取命中率99.9% 為中心儲存擋住了絕大部分請求,即使TiDB短時間故障,對我們影響也比較小。
3.5 如何保障系統穩定性
作為推送平臺,我們平臺的流量主要分為外部呼叫及內部上下游之間的呼叫。它們大幅波動都會影響系統的穩定性,所以我們要進行限流、控速,保障系統穩定執行。

3.5.1 推送閘道器限流
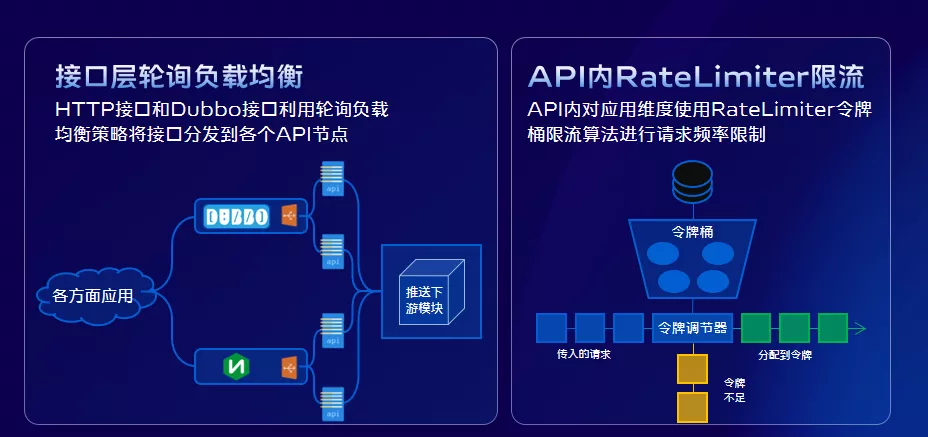
推送閘道器作為流量入口其穩定性非常重要,要讓推送閘道器穩定執行,我們首先要解決流量均衡的問題即避免流量傾斜的問題。因為流量傾斜之後,很有可能會引起雪崩的情況。
我們是採用輪詢的機制,進行流量的負載均衡,來避免流量傾斜問題。但是這裡有個前提條件,那就是所有推送閘道器節點,伺服器配置要保持一致,否則很有可能會因為某個處理能力不足導致過載問題。其次是我們要控制流入我們系統的併發量,避免流量洪峰穿透推送閘道器導致後端服務過載。我們採用的是令牌桶演算法,控制每個推送閘道器投放速度,進而能夠對下游節點起到保護作用。
那麼令牌數量設定多少才合適呢?設定低了,下游節點資源不能充分利用;設定太高了,下游節點有可能扛不住,我們可以採用主動+被動的動態調整的策略:
1)當流量超過下游叢集處理能力時,通知上游進行限速;
2)當呼叫下游介面超時,達到一定比例是進行限流。
3.5.2 系統內部限速:標籤推送平滑下發
既然推送閘道器已經限流了,為什麼內部節點之間還要限速?這個是由於我們平臺的業務特點決定的,我們平臺支援全量、標籤推送,我們要避免效能較好的模組,把下游節點資源耗盡的情況。我們標籤推送模組(提供全量、標籤推送)就是一個性能較高的服務,為了避免它對下游造成影響。我們基於Redis和令牌桶演算法實現了平滑推送的功能,控制每個標籤任務的推送速度,來保護下游節點。
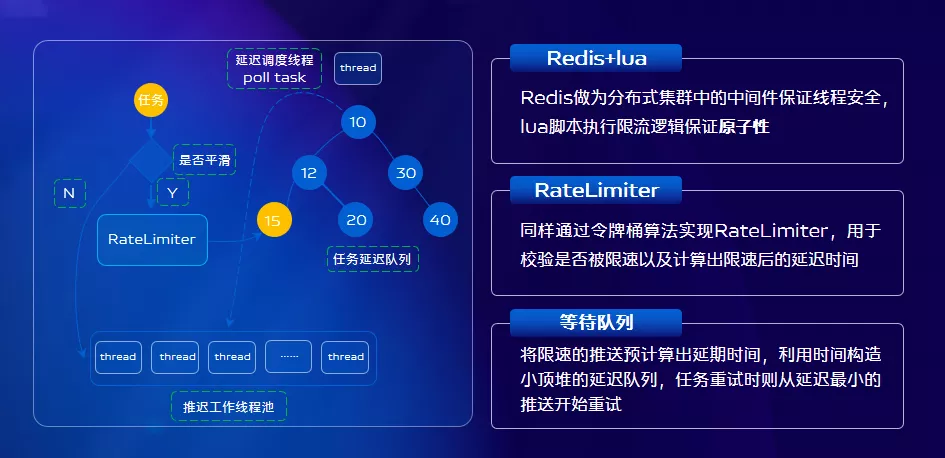
另外我們平臺支援應用建立多個標籤推送,它們的推送速度會疊加,所以僅控制單個標籤任務的平滑推送是不夠的。需要在推送下發模組對應用粒度進行限速,避免推送過快對業務後臺造成壓力。
3.5.3 系統內部限速:訊息下發時限速傳送
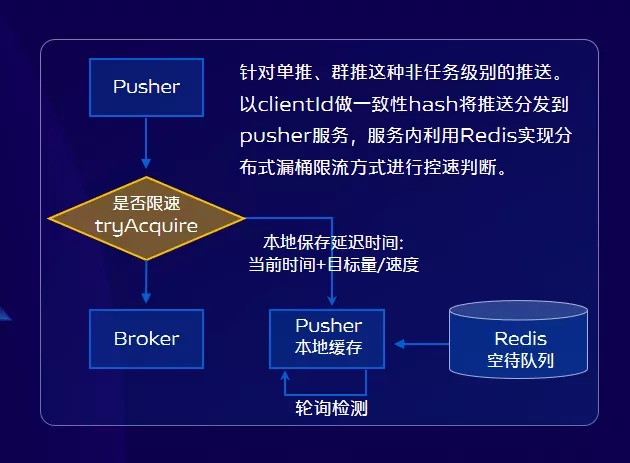
所以為了實現應用級別的限速,我們採用Redis實現分散式漏桶限流的方案,具體方案如上圖所示,這裡我們為什麼採用的是clientId(裝置唯一標識)而不是使用應用ID來做一致性hash?主要是為了負載均衡因為clientId相比應用ID,自從實現了這個功能之後,業務方再也不用擔心推送太快,造成自己伺服器壓力大的問題。
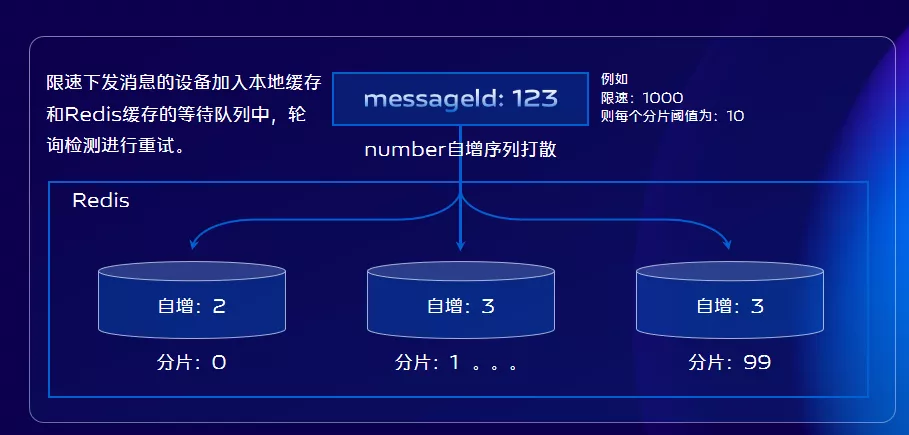
那麼被限速的訊息會被丟掉嗎?當然不會,我們會將這些訊息儲存到本地快取、並且打散儲存到Redis,之所以需要打散儲存主要是為了避免後續出現儲存熱點問題。
3.5.4 熔斷降級
推送平臺,一些突發事件、熱點新聞會給系統帶來較大的突發流量。我們應該如何應對突發流量呢?
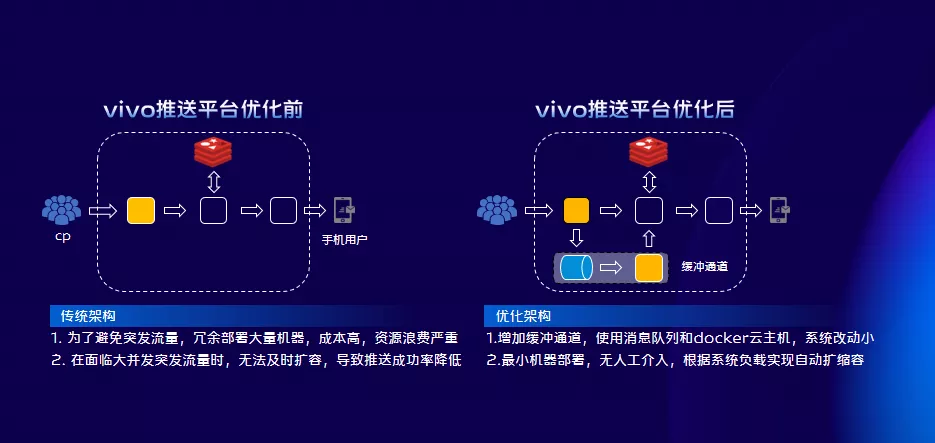
如左圖所示,傳統的架構上為了避免突發流量對系統的衝擊,冗餘部署大量機器,成本高、資源浪費嚴重。在面臨突發流量時,無法及時擴容,導致推送成功率降低。我們是怎麼做的呢?我們採用增加緩衝通道,使用訊息佇列和容器的解決方案,這種方案系統改動小。當無突發流量時以較小量機器部署,當遇到突發流量時我們也不需要人工介入,它會根據系統負載自動擴縮容。
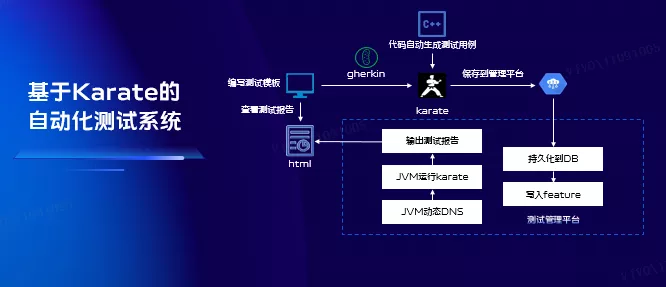
3.6 基於Karate的自動化測試系統
在日常開發中大家為了快速開發需求,大家往往忽視了介面的邊界測試,這將會給線上服務造成很大的質量風險。另外不知道大家有沒有注意到,團隊中不同角色溝通時使用的不同媒介比如使用word、excel、xmind等,會導致溝通的資訊出現不同程度折損。所以為了改善以上問題,我們開發了一個自動化測試平臺,用於提升測試效率與介面用例覆蓋率,我們採用領域統一的語言減少團隊中不同角色溝通訊息折損。另外還可以對測試用例統一集中管理,方便迭代維護。
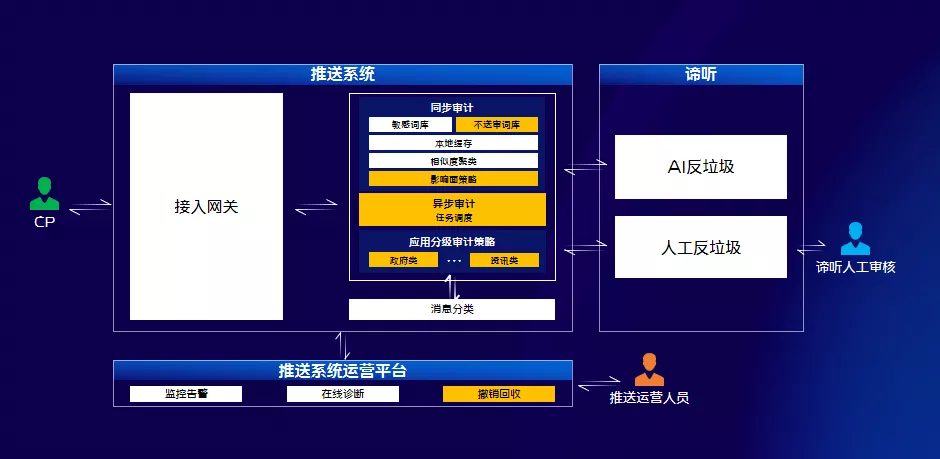
3.7 內容安全
作為推送平臺,我們要為內容安全把好關,我們提供了內容審計的能力。我們採用自動稽核為主、人工稽核為輔機制來提升稽核效率,同時結合基於影響面及應用分級的策略進行內容審計,為內容安全保駕護航。從圖中可以看到業務請求經過接入閘道器轉發給內容審系統進行第一層本地規則的內容審計,如果沒有命中本地規則則呼叫我們諦聽系統進行內容反垃圾審計。
四、平臺未來規劃
到前面主要介紹了我們推送平臺這幾年的架構演進及演進過程中的系統穩定性、高效能、安全等方面的實踐,接下來將給大家介紹我們未來的重點工作。

為了給使用者提供更易用、更穩定、更安全的推送平臺,未來我們將會在以下四個方面持續投入建設:
-
第一在單模組資料一致性的基礎上,實現全系統資料一致性;
-
第二雖然目前我們平臺具備了一定的容災降級的能力,但是還不夠,我們將繼續完善各系統的熔斷降級能力;
-
第三在平臺的易用性方面我們依然會持續優化,為廣大使用者提供更加便捷的平臺服務;
-
第四作為推送平臺,異常流量識別的能力也比較重要,它可以避免異常流量影響系統的穩定性,所以未來我們也會建設異常流量識別的能力。
也希望隨著我們在平臺能力上持續完善,未來我們可以為大家提供更好的服務。
作者:vivo網際網路伺服器團隊-Li Qingxin
- 層層剖析一次 HTTP POST 請求事故
- vivo 萬臺規模 HDFS 叢集升級 HDFS 3.x 實踐
- vivo 萬臺規模 HDFS 叢集升級 HDFS 3.x 實踐
- Redis 記憶體優化在 vivo 的探索與實踐
- Redis 記憶體優化在 vivo 的探索與實踐
- Redis 記憶體優化在 vivo 的探索與實踐
- FastDFS 海量小檔案儲存解決之道
- FastDFS 海量小檔案儲存解決之道
- Spark SQL 欄位血緣在 vivo 網際網路的實踐
- Spark SQL 欄位血緣在 vivo 網際網路的實踐
- FastDFS 海量小檔案儲存解決之道
- Spark SQL 欄位血緣在 vivo 網際網路的實踐
- 高效壓縮點陣圖在推薦系統中的應用
- 探究Presto SQL引擎(2)-淺析Join
- 高效壓縮點陣圖在推薦系統中的應用
- 探究Presto SQL引擎(2)-淺析Join
- 解析分散式系統的快取設計
- 解析分散式系統的快取設計
- 狀態機引擎在vivo營銷自動化中的深度實踐 | 引擎篇02
- 狀態機引擎在vivo營銷自動化中的深度實踐 | 引擎篇02