“伯樂”流量調控平臺工程視角 | 得物技術
1研發背景
1.1 我們想要解決什麼問題?
我們期望平臺能夠覆蓋的三類運營訴求如下:
(1)突發事件的應對:包括不限於外部的不可抗力影響,網路上的熱點事件、爆倉等突發事件,在搜尋&推薦等個性化流量場景下,單純依靠演算法模型的學習來適應,時間上不被業務方接受。
(2)新品/新人等缺少資料的情況:在扶持新品、留存新人等問題上,新品召回難、個性化分數低導致排名靠後無法曝光,而新人缺少畫像也會對推薦效果造成影響。因此對於新品的加權、新人定向投放需要頻繁調整的情況,往往需要人工進行變更。
(3)平臺的實驗/探索專案:如品類價格帶分佈控制,一些探索嘗試性的實驗,需要先小流量定向推送指定商品進行實驗,取得一定結果、經驗後,再進行優化、推全等情況。需要在圈品、圈人、AB實驗、資料大盤等多角度進行分析;頻繁的調整策略打法,也需要技術側進行迭代升級。
1.2 為什麼要做成平臺?
不搭建平臺,我們也快速地落地過高UE商品加權、價格力商品扶持等業務方訴求,做法一般是通過對召回引擎中的商品打上標記,在上游系統識別到某次請求複合業務的定向投放規則時,對有標記的商品進行加權。同時統計埋點資料,評估商品實驗組與基準對照組的diff,確保扶持的力度符合業務預期。而平臺化在初期投入大量研發成本的原因主要是針對以下兩點:
(1)研發&時間成本:每個策略的新增都需要從商品打標到引擎,線上鏈路對指定流量的判別、演算法加權、實時資料反饋、離線資料報表等環節進行迭代,需要BI、引擎dump、召回層、預估演算法、實時數倉等多個團隊投入合計至少10~12人日的研發資源,同時PMO、各團隊leader及PM、專案聯調、測試資源、線上變更CR等間接投入也會積少成多。
(2)多場景問題:不同場景重複建設也會帶來成本的增加不再贅述,更多的是相同的使用者在不同場景有各自的分流規則,如何統一的進行AB實驗和資料統計分析也存在著一定問題。一部分商品加權也必然會擠佔其他商品自然曝光的流量,這部分被擠佔的流量是我們的運營成本。如何評估各場景的ROI,在單個場景效果不盡如人意的情況停止投放如何覆盤該場景的資源投入,也是我們需要面對的問題。
1.3我們是怎麼做的?
上述的三類問題其實可以統一抽象為:使用者隨時可以選擇一個商品集,在指定的流量下(人群標籤、query類目、品牌、AB實驗分組、時間段等)進行某項扶持(加權、保量、曝光佔比、按比例提升等)。我們大體將實現該能力的系統劃分為5個模組,如下圖所示:
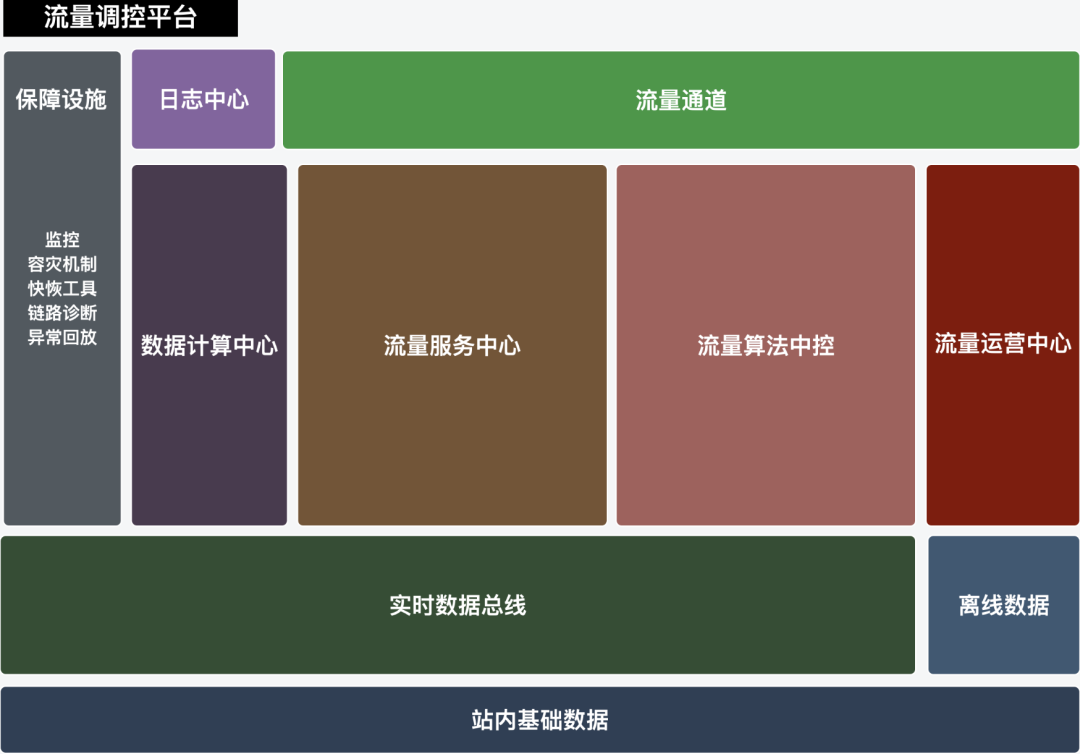
1)流量運營中心:支援運營同學自由配置策略,更換商品集、調整投放條件、完整的審批流程、報表的查閱等等運營操作;策略的新增及變更不再需要需求排期和研發週期的漫長等待。
(2)流量服務中心:用於將運營配置的流量規則與線上請求做匹配,同時負責串聯演算法中控、調控商品召回、埋點上報、容災限流等工作,是調控鏈路的樞紐。
(3)資料計算中心:主要是兩部分職責,其一是將運營配置的商品集、站內基礎資料,商品增量目標完成情況等離線資料全量更新至搜尋引擎。另一部分則是線上鏈路的分鐘級統計實時資料,商品的分實驗、分策略、分場景實時累計資料同步給演算法中控做決策,及搜尋引擎實時更新召回過濾條件的依據。
(4)流量演算法中控:調控鏈路召回的商品需要由中控根據商品特徵、使用者畫像、預估分、目標達成進度及增長速度等係數,實時調整每個被調控品的調控力度,負責平滑控制和過量熔斷等職責,是整個調控系統的大腦。
(5)保障設施:圍繞著穩定性、問題定位效率等角度建設的基礎設施,不做贅述。
下面對技術鏈路進行展開。
2技術鏈路
2.1 業務架構:
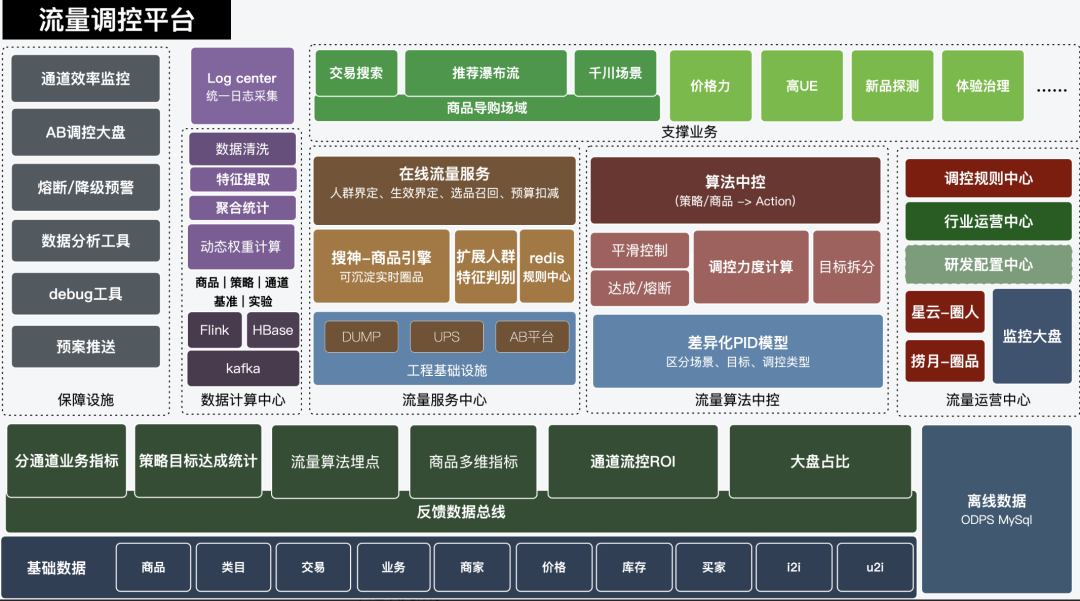
經過2022 Q4季度的研發工作,當前場景已經覆蓋了交易搜尋及部分推薦場景。線上支援業務策略包括:新品保量、高UE商品加權、重複曝光/獵奇商品曝光比例下調等業務訴求。同時調控為了更多個性化流量通道的接入也完成了非文字個性化多路召回等通用能力的建設工作。運營後臺的通用報表、審批流程、變更歷史對比等能力基本建設完成。
2.2 工程鏈路:
- 藍色框為新2022 Q4建設,白色框為Q3季度已完成功能
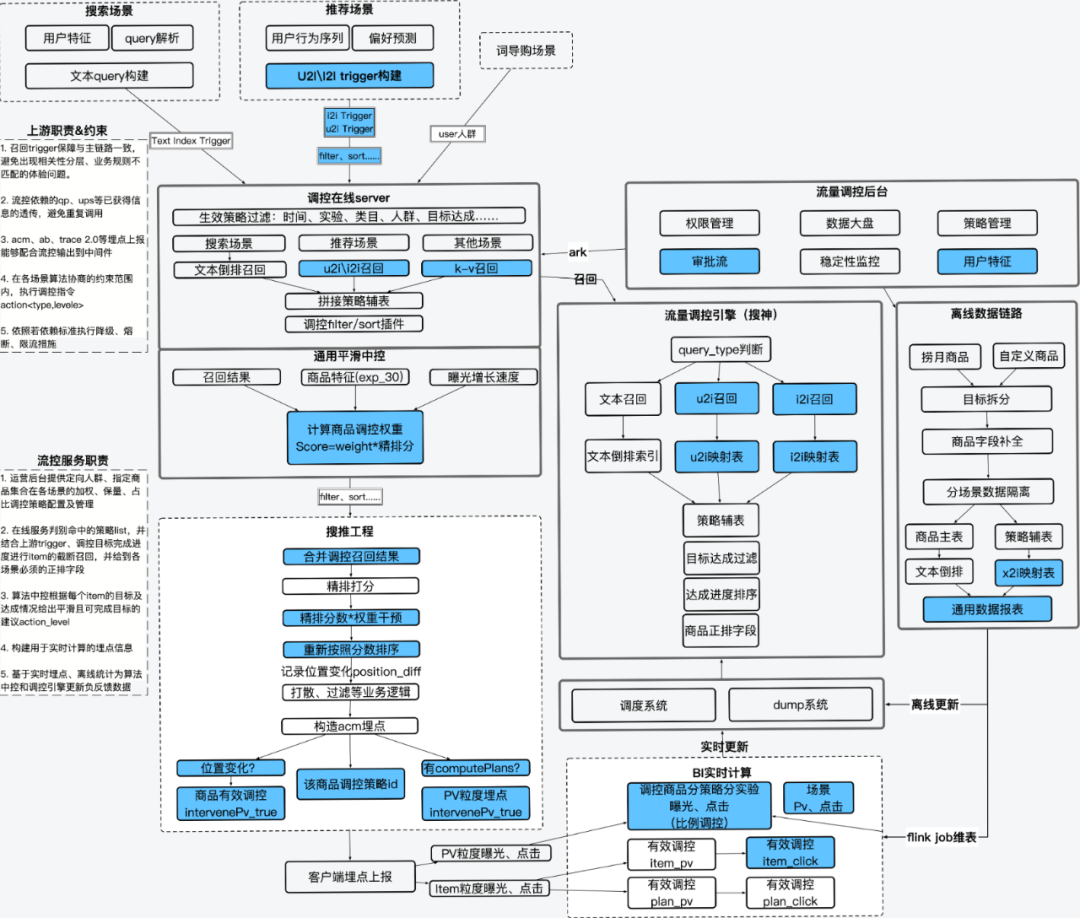
當離線資料小時級更新至引擎後,整個系統的request從左上方各場景進入,攜帶文字query或使用者特徵trigger來到調控server,調控server將根據requestInfo與流控運營後臺推送的plan(針對某些請求調控某商品集抽象為一個plan) list進行匹配。結合生效的策略ID構建query進行調控引擎召回。召回結果配合演算法中控產出<action, weight> (調控方式,力度),給到上游對精排結果進行重排序,同時需要上游協助埋點的資訊也同步落盤。實時數倉採集埋點後按照相應規則進行計算,反饋給中控及實時update調控引擎。
調控server內部職責如下:
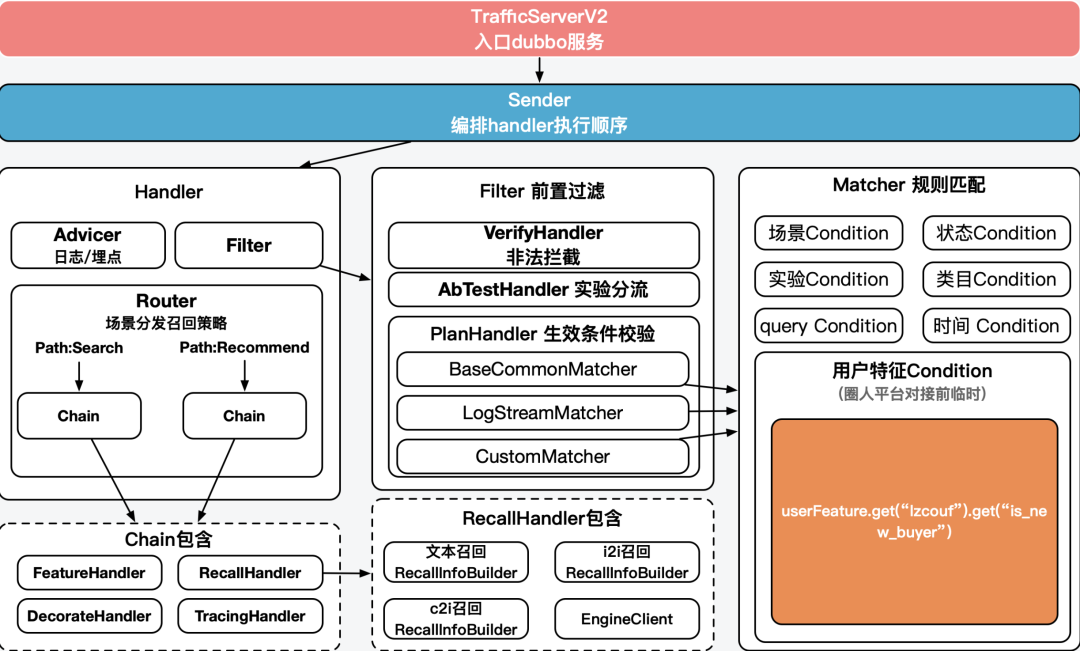
各handler分別負責生效策略判別、召回策略分發,退場兜底機制、AB分桶、實時計算埋點構造,呼叫演算法中控等,詳細實現不做展開。
基於搜神自研引擎的流控召回邏輯:
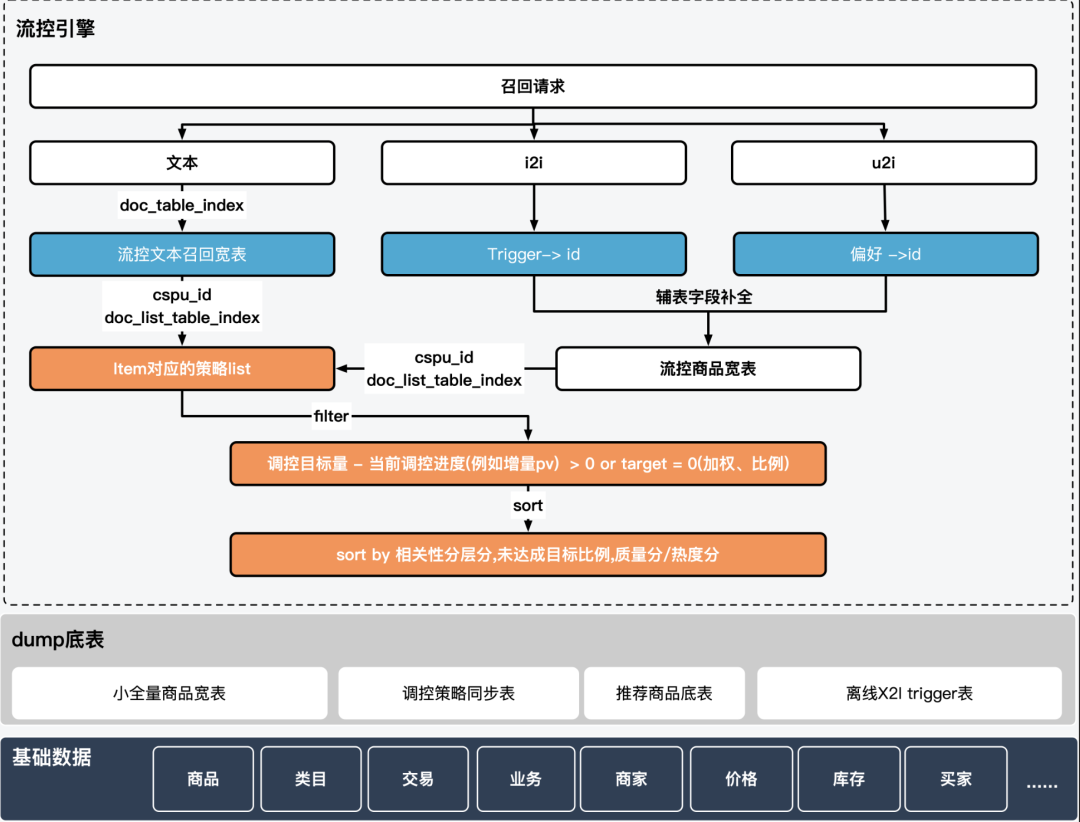
流控引擎當前支援面向搜尋場景的文字召回及面向推薦的X2i兩類召回,trigger -> 商品的對映關係、底層資料與自然召回保持一致,候選集也是搜推場景召回候選集的真子集,可以確保相關性分層、真假曝光過濾等邏輯與各場景對齊;類目預測、貨號識別複用QP結果,推薦trigger和使用者行為序列也是複用的上游結果,因此單獨的調控召回鏈路並不會導致體驗問題。
另外針對於保量型別的新品調控,我們藉助搜神自研引擎的擴充套件能力,定製了目標達成過濾filter以及優先順序低於相關性的sort外掛,一定程度上緩解了新品召回難得問題。
2.3 其他模組:
2.3.1 實時資料:
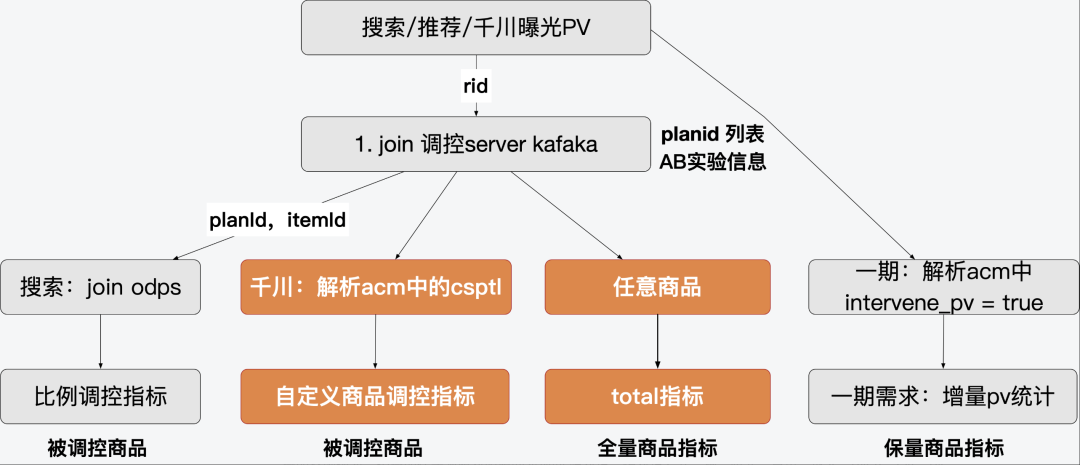
中控的平滑控制、目標達成熔斷機制以及引擎sort/filter外掛依賴的實時資料如下:

以上指標基於客戶端上報的埋點、服務端日誌kafaka、odps維表經實時數倉團隊計算所得,計算邏輯簡化如下:
2.3.2 效果資料:
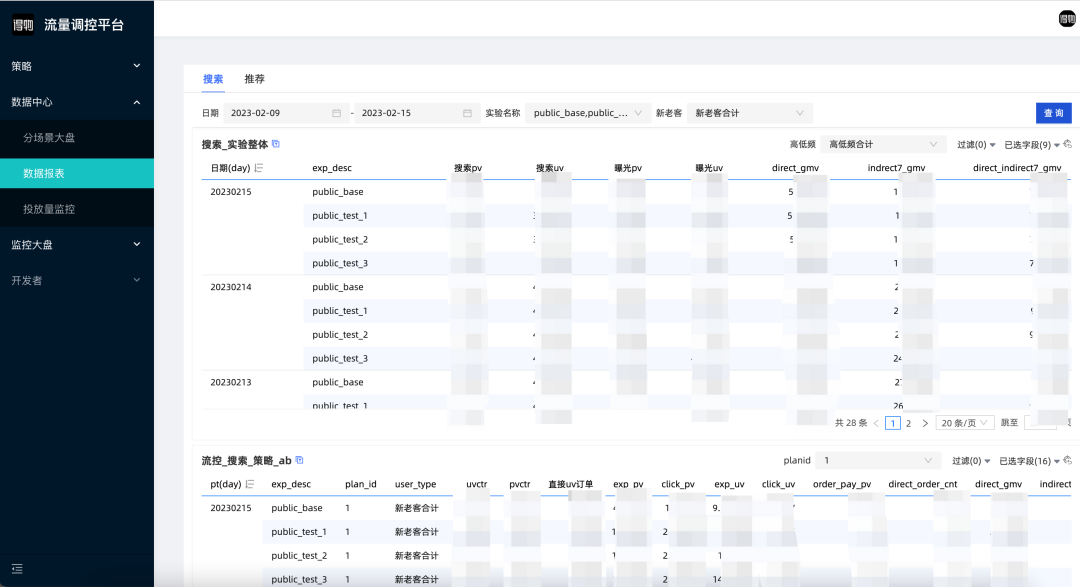
商品效率報表,指商品在實驗組對照組的表現的絕對值、相對值差異,涵蓋曝光、點選、成交、qvctr、cvr,pv 價值等指標。某個調控策略(plan)對這一批商品的影響則需要限制商品是被調控品,流量也必須是在指定的場景、人群特徵、實驗、類目等條件下的效率報表,這部分不難理解。
AB實驗分流,由調控server承接各個來源的請求,並進行統一兩層正交AB,調控分層實驗組對照組邏輯如下:
a. 獨立實驗
i. 對照組:獨立實驗對照組(固定)
ii. 實驗組:策略(plan)配置的實驗組,根據每個策略的配置決定
b. 公共實驗(公共實驗一個流量分組可能疊加多個實驗,根據不同的商品範圍檢視各自對品維度的影響):
i. 對照組:公共實驗對照組(固定)
ii. 實驗組:策略(plan)配置的實驗組,根據每個策略的配置決定
以上,BI團隊可給出針對部分新品的某個扶持策略(plan)為例,可觀測的報表類似如下:
實時+離線的資料鏈路最終服務於調控引擎和演算法中控
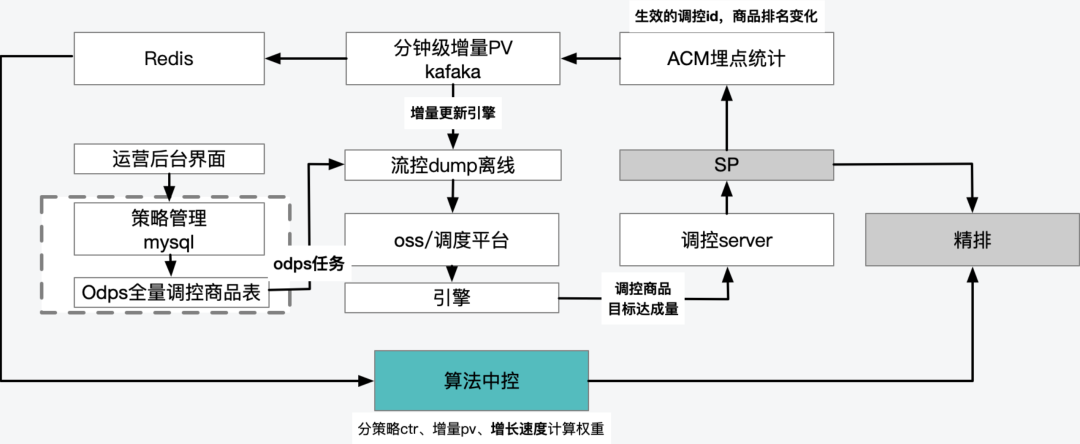
2.3.3 演算法中控 :
應對定量目標的保量需求,演算法中控依託實時反饋資料進行的PID計算邏輯如下:
- 排序依據的score=rs權重+相關性分 或者 score=rspctr/median(pctr)* 權重 +相關性分權重= 1+ pid_score,權重區間 [0.1,10]
pid_score=(當前目標曝光-當前累計曝光量)/當前目標曝光KI
當前目標曝光=計劃目標當前時間曝光比例
應對曝光佔比型別的比例調控需求稍有差異:
佔比低於目標時扶持:
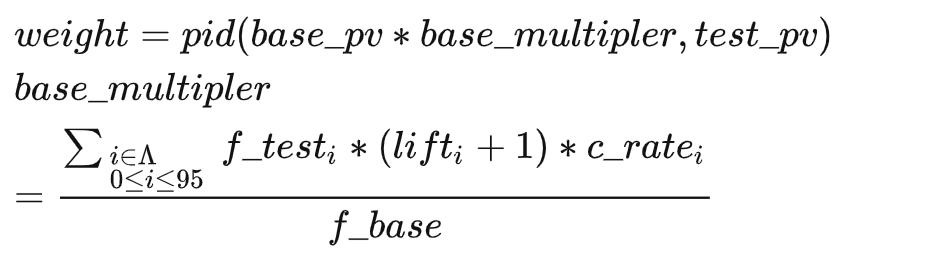
佔比高於目標時打壓:
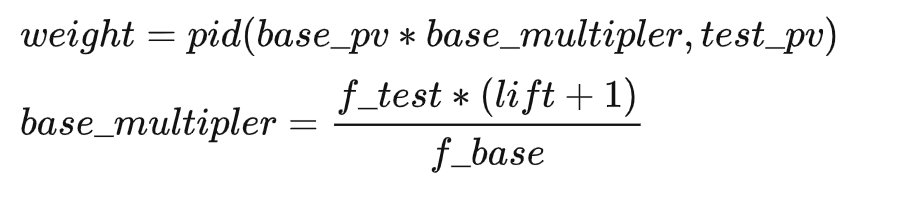
3值得一提的
3.1 借鑑廣告體系的獨立召回鏈路
相比於之前的工作經驗和其他平臺的調研結果來看,類似廣告投放體系的獨立召回鏈路有如下幾點特徵:
(1)在新品扶持等領域,依賴於自然召回後再判斷是否為調控品的邏輯,在針對“召回難”問題上並沒有特別好的方案,往往是通過粗排白名單等方式對粗排進行暴力干預,白名單存在上限以及相關性差的問題並沒有被解決。而獨立的召回鏈路中,我們天然的將底池限定為有且僅有調控商品,在相關性分層符合要求的情況下,調控商品的位置不會被非調控品擠佔。同時依賴搜神自研引擎定製的達成率邏輯,也能防止部分調控商品擠佔其他調控商品流量的問題。線上實際可保障99%的新品能夠獲得調控帶來的有效增量曝光(曝光位置提前),同時整體保量目標達成率也可以滿足業務要求
(2)在增量曝光的判斷上更為準確:自然未能召回,僅調控有招回的概念,可以幫助我們判斷,無論這個商品的坑位是否發生變化,僅調控鏈路召回必然是增量曝光。有助於後續繼續推進基於運營分組預算管理的後臺系統
(3)前置過濾對比後置過濾,可以在有限的召回量內,給予其他商品更多機會
(4)負向上有一定缺陷,獨立鏈路召回的數量小於整體召回數量,會導致打壓效果下降。這一點還是反作弊平臺及風控系統黑名單直接對接商品底池的方式更為專業。
3.2 跨場景統一的AB實驗
各場景各服務單獨對接AB平臺,相互之間是隔離的,雜湊規則也是定製化的。後續我們是期望多場景聯合調控中,增量目標的分配比例可以動態自動最優調配,同時回收各場景的ROI指標。熟悉報表的同學可以看到,即便是去萬三高客單後的AB資料,同一個實驗組多個實驗的情況下,指標仍有差異。獨立統一的調控正交分層可以保證無論是搜尋還是推薦過來的同一個使用者,命中的實驗或者說策略是相同的,聯合調控可據此分層資料做參考。
4後續方向

(1)完善平臺能力:
a;基本能力建設,包括撈月元件的接入,打通圈品集資訊,實現一站式圈品及圈品規則維護;人群規則平臺的接入,簡化線上服務FeatureCondition的判別流程
b:調控平臺運營中心易用性及使用體驗上的建設工作,從資料分析、跨平臺資訊的打通、小工具、去除冗餘操作及預警通知等方面打磨產品,從“能用”到“好用”的長期目標
c:後臺增加配置中心,ark配置視覺化,減少複雜json的變更成本;後期實現一鍵降級等功能;增加debug工具,測試線上系統召回、權重是否符合預期,提升debug及線上問題定位效率
d:異常熔斷機制完善,異常通知能夠傳達到owner及運營負責人,異常損失效果可評估。
(2)非商品調控能力建設:
a:底紋詞&搜尋發現詞、搜尋框下拉推薦詞等詞導購場景覆蓋,與query直達相結合,能夠通過更多低成本的場景支援業務扶持指定貨品的訴求
b:社群內容作為得物的核心場景,且當前社群內容中的商品標籤、動態詳情頁商品卡片已經建立了內容引導交易的良好機制,無論是針對商品標籤的內容調控,還是定向為作者推送待扶持商品的提示等方向,都存在著探索的空間和價值,期待後續可以探索社群&交易聯合調控的落地場景。
(3)支撐場景擴充套件:
a:支援更多推薦場景,期望後續能夠在品牌落地頁、分類tab等場景進行實驗,挖掘不同型別的商品集合在不同場景的ROI最優方案。
b:跨場景聯合調控能力探索,跨場景目標分配、商品質量預估及評估、跨場景核心指標對齊等角度進行探索;幫助業務方在精細化人貨匹配上的探索拿到結果。
- MySQL MVCC實現原理
- 為什麼專案老夭折?這份專案管理指南請收好
- “伯樂”流量調控平臺工程視角 | 得物技術
- 如何評估某活動帶來的大盤增量 | 得物技術
- 得物榜單|全鏈路生產遷移及B/C端資料儲存隔離
- 透過現象看Java AIO的本質 | 得物技術
- 時效準確率提升之承運商路由網路挖掘 | 得物技術
- 存貨庫存模型升級始末 | 得物技術
- 關於加解密、加簽驗籤的那些事 | 得物技術
- GPU推理服務效能優化之路 | 得物技術
- 得物供應鏈複雜業務實時數倉建設之路
- 從 0 到 1,億級訊息推送的穩定性保障 | 得物技術
- 前端監控穩定性資料分析實踐 | 得物技術
- 得物容器SRE探索與實踐
- 得物熱點探測技術架構設計與實踐
- 今年很火的 AI 繪畫怎麼玩
- 得物社群計數系統設計與實現
- 得物商家客服桌面端Electron技術實踐
- 得物商家客服桌面端Electron技術實踐
- 得物染色環境落地實踐