在昇騰平台上對TensorFlow網絡進行性能調優
摘要:本文就帶大家瞭解在昇騰平台上對TensorFlow訓練網絡進行性能調優的常用手段。
本文分享自華為雲社區《在昇騰平台上對TensorFlow網絡進行性能調優》,作者:昇騰CANN 。
用户將TensorFlow訓練網絡遷移到昇騰平台後,如果存在性能不達標的問題,就需要進行調優。本文就帶大家瞭解在昇騰平台上對TensorFlow訓練網絡進行性能調優的常用手段。
首先了解下性能調優的全流程:
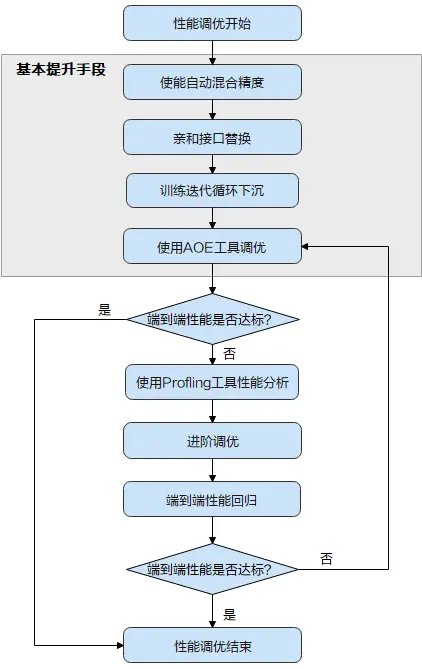
當TensorFlow訓練網絡性能不達標時,首先可嘗試昇騰平台提供的“三板斧”操作,即上圖中的“基本提升手段”:使能自動混合精度 > 進行親和接口的替換 > 使能訓練迭代循環下沉 > 使用AOE工具進行調優。
基本調優操作完成後,需要再次執行模型訓練並評估性能,如果性能達標了,調優即可結束;如果未達標,需要使用Profling工具採集詳細的性能數據進一步分析,從而找到性能瓶頸點,並進一步針對性的解決,這部分調優操作需要用户有一定的經驗,難度相對較大,我們將這部分調優操作稱為進階調優。
本文主要帶大家詳細瞭解基本調優操作,即上圖中的灰色底紋部分。
使能自動混合精度
混合精度是業內通用的性能提升方式,通過降低部分計算精度提升數據計算的並行度。混合計算訓練方法通過混合使用float16和float32數據類型來加速深度神經網絡的訓練過程,並減少內存使用和存取,從而可以提升訓練網絡性能,同時又能基本保證使用float32訓練所能達到的網絡精度。
Ascend平台提供了“precision_mode”參數用於配置網絡的精度模式,用户可以在訓練腳本的運行配置中添加此參數,並將取值配置為“allow_mix_precision”,從而使能自動混合精度,下面以手工遷移的訓練腳本為例,介紹配置方法。
- Estimator模式下,在NPURunConfig中添加precision_mode參數設置精度模式:
npu_config=NPURunConfig(
model_dir=FLAGS.model_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps, session_config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=False),
precision_mode="allow_mix_precision"
)- sess.run模式下,通過session配置項precision_mode設置精度模式:
config = tf.ConfigProto(allow_soft_placement=True)
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
…
with tf.Session(config=config) as sess:
print(sess.run(cost))親和接口替換
針對TensorFlow訓練網絡中的dropout、gelu接口,Ascend平台提供了硬件親和的替換接口,從而使網絡獲得更優性能。
- 對於訓練腳本中的nn.dropout,建議替換為Ascend對應的API實現,以獲得更優性能:
layers = npu_ops.dropout()- 若訓練腳本中存在layers.dropout、tf.layers.Dropout、tf.keras.layers.Dropout、tf.keras.layers.SpatialDropout1D、tf.keras.layers.SpatialDropout2D、tf.keras.layers.SpatialDropout3D接口,建議增加頭文件引用:
from npu_bridge.estimator.npu import npu_convert_dropout- 對於訓練腳本中的gelu接口,建議替換為Ascend提供的gelu接口,以獲得更優性能。
例如,TensorFlow原始代碼:
遷移後的代碼:
from npu_bridge.estimator.npu_unary_ops import npu_unary_ops
layers = npu_unary_ops.gelu(x)訓練迭代循環下沉
訓練迭代循環下沉是指在Host調用一次,在Device執行多次迭代,從而減少Host與Device間的交互次數,縮短訓練時長。用户可通過iterations_per_loop參數指定訓練迭代的次數,該參數取值大於1即可使能訓練迭代循環下沉的特性。
使用該特性時,要求訓練腳本使用TF Dataset方式讀數據,並開啟數據預處理下沉,即enable_data_pre_proc開關配置為True,例如sess.run配置示例如下:
custom_op.parameter_map["enable_data_pre_proc"].b = True其他使用約束,用户可參見昇騰文檔中心的《TensorFlow模型遷移和訓練指南》。
Estimator模式下,通過NPURunConfig中的iterations_per_loop參數配置訓練迭代循環下沉的示例如下:
session_config=tf.ConfigProto(allow_soft_placement=True)
config = NPURunConfig(session_config=session_config, iterations_per_loop=10)AOE自動調優
昇騰平台提供了AOE自動調優工具,可對網絡進行子圖調優、算子調優與梯度調優,生成最優調度策略,並將最優調度策略固化到知識庫。模型再次訓練時,無需開啟調優,即可享受知識庫帶來的收益。
建議按照如下順序使用AOE工具進行調優:
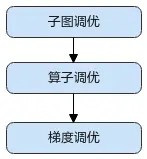
訓練場景下使能AOE調優有兩種方式:
- 通過設置環境變量啟動AOE調優。
# 1:子圖調優
# 2:算子調優
# 4:梯度調優
export AOE_MODE=2- 修改訓練腳本,通過“aoe_mode”參數指定調優模式,例如:
sess.run模式,訓練腳本修改方法如下:
custom_op.parameter_map["aoe_mode"].s = tf.compat.as_bytes("2")estimator模式下,訓練腳本修改方法如下:
config = NPURunConfig(
session_config=session_config,
aoe_mode=2)以上就是TensorFlow網絡在昇騰平台上進行性能調優的常見手段。關於更多文檔介紹,可以在昇騰文檔中心查看,您也可在昇騰社區在線課程板塊學習視頻課程,學習過程中的任何疑問,都可以在昇騰論壇互動交流!
相關參考:
[1]昇騰文檔中心
[2]昇騰社區在線課程
[3]昇騰論壇
- 使用卷積神經網絡實現圖片去摩爾紋
- 內核不中斷前提下,Gaussdb(DWS)內存報錯排查方法
- 簡述幾種常用的排序算法
- 自動調優工具AOE,讓你的模型在昇騰平台上高效運行
- GaussDB(DWS)運維:導致SQL執行不下推的改寫方案
- 詳解目標檢測模型的評價指標及代碼實現
- CosineWarmup理論與代碼實戰
- 淺談DWS函數出參方式
- 代碼實戰帶你瞭解深度學習中的混合精度訓練
- python進階:帶你學習實時目標跟蹤
- Ascend CL兩種數據預處理的方式:AIPP和DVPP
- 詳解ResNet 網絡,如何讓網絡變得更“深”了
- 帶你掌握如何查看並讀懂昇騰平台的應用日誌
- InstructPix2Pix: 動動嘴皮子,超越PS
- 何為神經網絡卷積層?
- 在昇騰平台上對TensorFlow網絡進行性能調優
- 介紹3種ssh遠程連接的方式
- 分佈式數據庫架構路線大揭祕
- DBA必備的Mysql知識點:數據類型和運算符
- 5個高併發導致數倉資源類報錯分析