TCP 三次握手,给我长脸了噢
大家好,我是小富~
前言
之前有个小伙伴在技术交流群里咨询过一个问题,我当时还给提供了点排查思路,是个典型的八股文转实战分析的案例,我觉得挺有意思,趁着中午休息简单整理出来和大家分享下,有不严谨的地方欢迎大家指出。
问题分析
我们先来看看他的问题,下边是他在群里对这个问题的描述,我大致的总结了一下。
他们有很多的 IOT 设备与服务端建立连接,当增加设备并发请求变多,TCP连接数在接近1024个时,可用TCP连接数会降到200左右并且无法建立新连接,而且分析应用服务的GC和内存情况均未发现异常。

从他的描述中我提取了几个关键值,1024、200、无法建立新连接。
看到这几个数值,直觉告诉我大概率是TCP请求溢出了,我给的建议是先直接调大全连接队列和半连接队列的阀值试一下效果。
那为什么我会给出这个建议?
半连接队列和全连接队列又是个啥玩意?
弄明白这些回顾下TCP的三次握手流程,一切就迎刃而解了~
回顾TCP
TCP三次握手,熟悉吧,面试八股里经常全文背诵的题目。
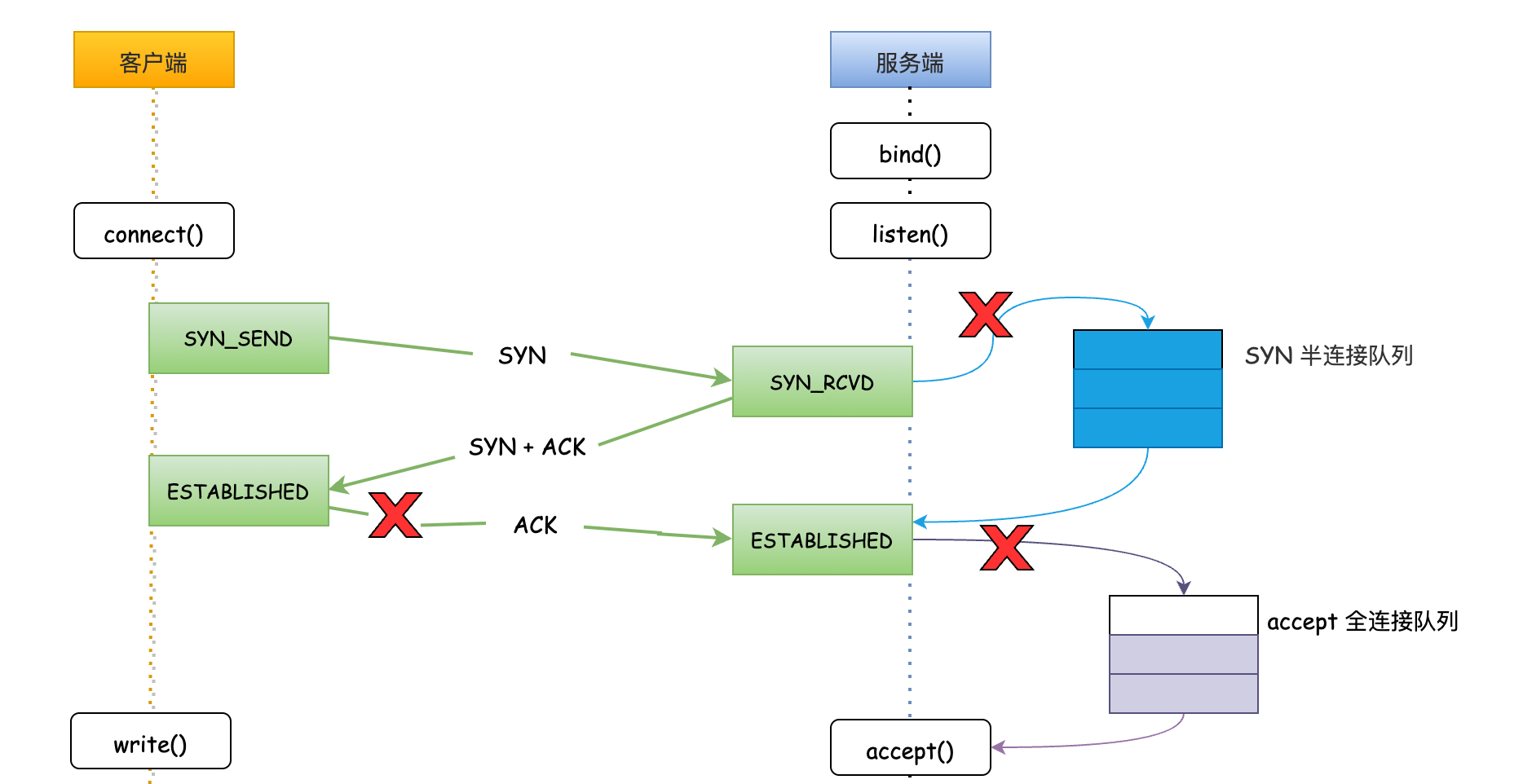
话不多说先上一张图,看明白TCP连接的整个过程。
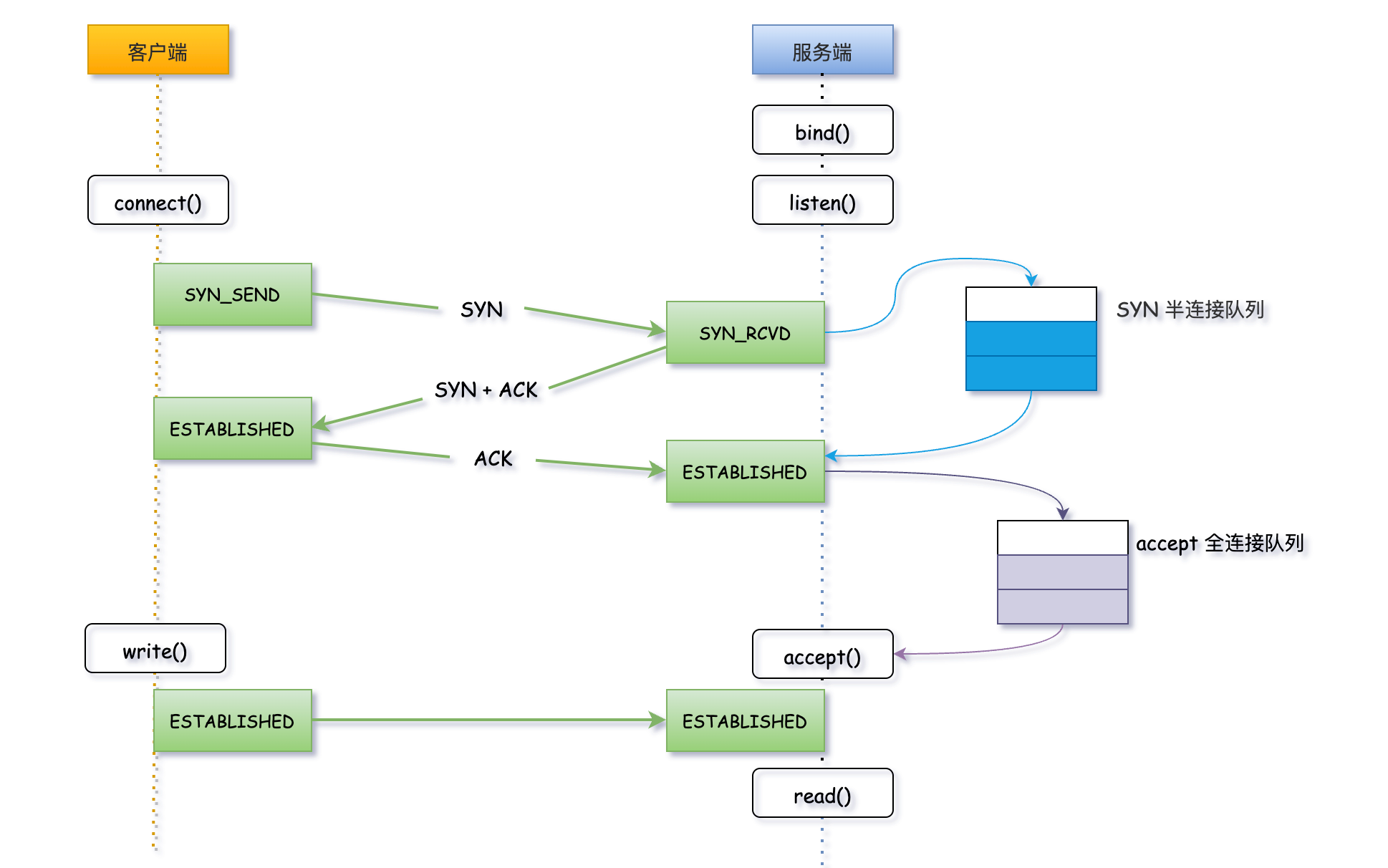
第一步:客户端发起SYN_SEND连接请求,服务端收到客户端发起的SYN请求后,会先将连接请求放入半连接队列;
第二步:服务端向客户端响应SYN+ACK;
第三步:客户端会返回ACK确认,服务端收到第三次握手的 ACK 后标识连接成功。如果这时全连接队列没满,内核会把连接从半连接队列移除,创建新的连接并将其添加到全连接队列,等待客户端调用accept()方法将连接取出来使用;
TCP协议三次握手的过程,Linux内核维护了两个队列,SYN半连接队列和accepet全连接队列。即然叫队列,那就存在队列被压满的时候,这种情况我们称之为队列溢出。
当半连接队列或全连接队列满了时,服务器都无法接收新的连接请求,从而导致客户端无法建立连接。
全连接队列
队列信息
全连接队列溢出时,首先要查看全连接队列的状态,服务端通常使用 ss 命令即可查看,ss 命令获取的数据又分为 LISTEN状态 和 非LISTEN两种状态下,通常只看LISTEN状态数据就可以。
LISTEN状态
Recv-Q:当前全连接队列的大小,表示上图中已完成三次握手等待可用的 TCP 连接个数;
Send-Q:全连接最大队列长度,如上监听8888端口的TCP连接最大全连接长度为128;
# -l 显示正在Listener 的socket
# -n 不解析服务名称
# -t 只显示tcp
[root@VM-4-14-centos ~]# ss -lnt | grep 8888
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 100 :::8888 :::*
非LISTEN 状态下Recv-Q、Send-Q字段含义有所不同
Recv-Q:已收到但未被应用进程读取的字节数;
Send-Q:已发送但未收到确认的字节数;
# -n 不解析服务名称
# -t 只显示tcp
[root@VM-4-14-centos ~]# ss -nt | grep 8888
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 100 :::8888 :::*
队列溢出
一般在请求量过大,全连接队列设置过小会发生全连接队列溢出,也就是LISTEN状态下 Send-Q < Recv-Q 的情况。接收到的请求数大于TCP全连接队列的最大长度,后续的请求将被服务端丢弃,客户端无法创建新连接。
# -l 显示正在Listener 的socket
# -n 不解析服务名称
# -t 只显示tcp
[root@VM-4-14-centos ~]# ss -lnt | grep 8888
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 200 100 :::8888 :::*
如果发生了全连接队列溢出,我们可以通过netstat -s命令查询溢出的累计次数,若这个times持续的增长,那就说明正在发生溢出。
[root@VM-4-14-centos ~]# netstat -s | grep overflowed
7102 times the listen queue of a socket overflowed #全连接队列溢出的次数
拒绝策略
在全连接队列已满的情况,Linux提供了不同的策略去处理后续的请求,默认是直接丢弃,也可以通过tcp_abort_on_overflow配置来更改策略,其值 0 和 1 表示不同的策略,默认配置 0。
# 查看策略
[root@VM-4-14-centos ~]# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow = 0:全连接队列已满时,服务端直接丢弃客户端发送的 ACK,此时服务端仍然是 SYN_RCVD 状态,在该状态下服务端会重试几次向客户端推送 SYN + ACK。
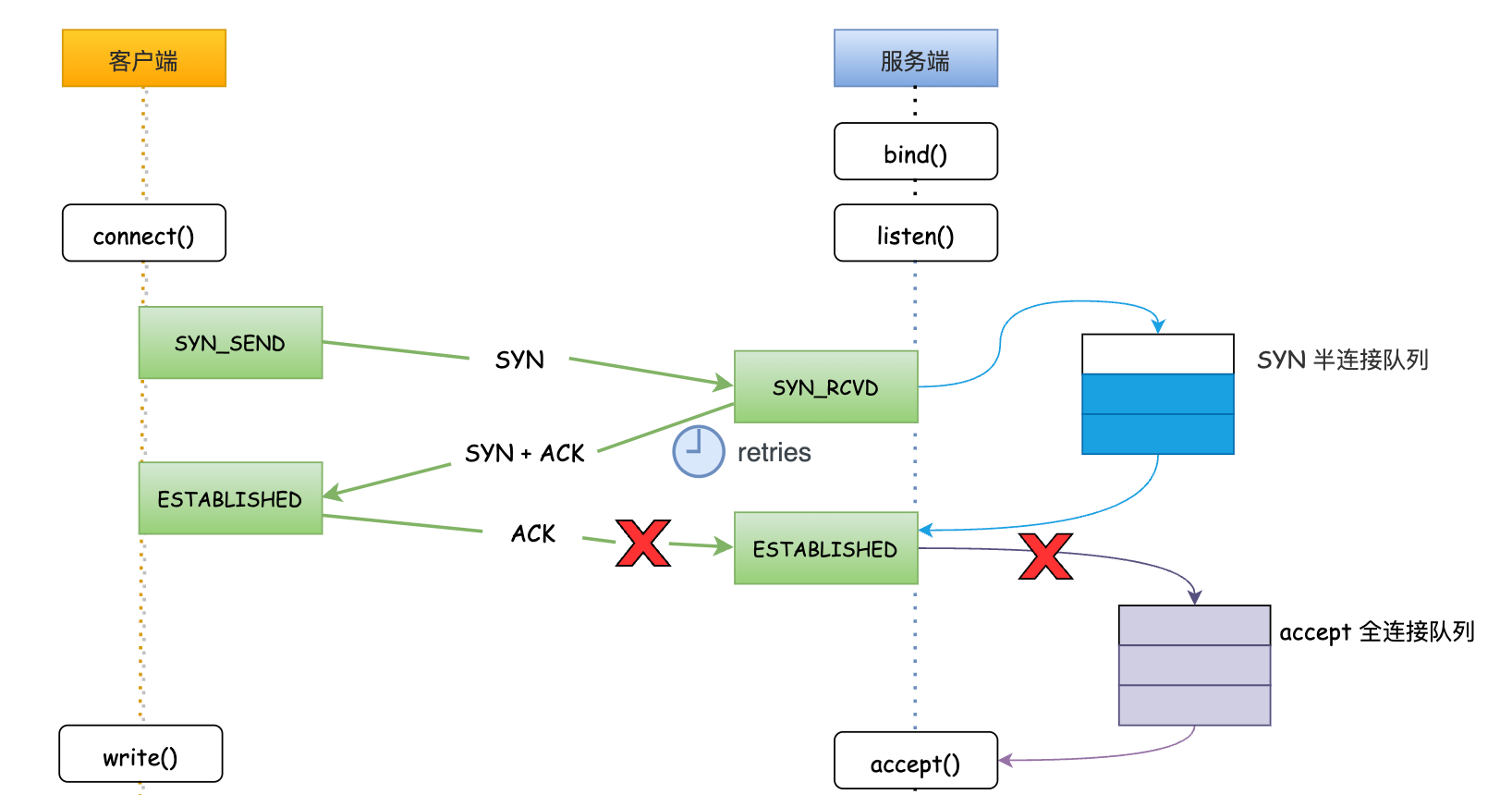
重试次数取决于tcp_synack_retries配置,重试次数超过此配置后后,服务端不在重传,此时客户端发送数据,服务端直接向客户端回复RST复位报文,告知客户端本次建立连接已失败。
RST: 连接 reset 重置消息,用于连接的异常关闭。常用场景例如:服务端接收不存在端口的连接请求;客户端或者服务端异常,无法继续正常的连接处理,发送 RST 终止连接操作;长期未收到对方确认报文,经过一定时间或者重传尝试后,发送 RST 终止连接。
[root@VM-4-14-centos ~]# cat /proc/sys/net/ipv4/tcp_synack_retries
0
tcp_abort_on_overflow = 1:全连接队列已满时,服务端直接丢弃客户端发送的 ACK,直接向客户端回复RST复位报文,告知客户端本次连接终止,客户端会报错提示connection reset by peer。
队列调整
解决全连接队列溢出我们可以通过调整TCP参数来控制全连接队列的大小,全连接队列的大小取决于 backlog 和 somaxconn 两个参数。
这里需要注意一下,两个参数要同时调整,因为取的两者中最小值
min(backlog,somaxconn),经常发生只挑调大其中一个另一个值很小导致不生效的情况。
backlog 是在socket 创建的时候 Listen() 函数传入的参数,例如我们也可以在 Nginx 配置中指定 backlog 的大小。
server {
listen 8888 default backlog = 200
server_name fire100.top
.....
}
somaxconn 是个 OS 级别的参数,默认值是 128,可以通过修改 net.core.somaxconn 配置。
[root@localhost core]# sysctl -a | grep net.core.somaxconn
net.core.somaxconn = 128
[root@localhost core]# sysctl -w net.core.somaxconn=1024
net.core.somaxconn = 1024
[root@localhost core]# sysctl -a | grep net.core.somaxconn
net.core.somaxconn = 1024
如果服务端处理请求的速度跟不上连接请求的到达速度,队列可能会被快速填满,导致连接超时或丢失。应该及时增加队列大小,以避免连接请求被拒绝或超时。
增大该参数的值虽然可以增加队列的容量,但是也会占用更多的内存资源。一般来说,建议将全连接队列的大小设置为服务器处理能力的两倍左右。
半连接队列
队列信息
上边TCP三次握手过程中,我们知道服务端SYN_RECV状态的TCP连接存放在半连接队列,所以直接执行如下命令查看半连接队列长度。
[root@VM-4-14-centos ~] netstat -natp | grep SYN_RECV | wc -l
1111
队列溢出
半连接队列溢出最常见的场景就是,客户端没有及时向服务端回ACK,使得服务端有大量处于SYN_RECV状态的连接,导致半连接队列被占满,得不到ACK响应半连接队列中的 TCP 连接无法移动全连接队列,以至于后续的SYN请求无法创建。这也是一种常见的DDos攻击方式。
查看TCP半连接队列溢出情况,可以执行netstat -s命令,SYNs to LISTEN前的数值表示溢出的次数,如果反复查询几次数值持续增加,那就说明半连接队列正在溢出。
[root@VM-4-14-centos ~]# netstat -s | egrep “listen|LISTEN”
1606 times the listen queue of a socket overflowed
1606 SYNs to LISTEN sockets ignored
队列调整
可以修改 Linux 内核配置 /proc/sys/net/ipv4/tcp_max_syn_backlog来调大半连接队列长度。
[root@VM-4-14-centos ~]# echo 2048 > /proc/sys/net/ipv4/tcp_max_syn_backlog
为什么建议
看完上边对两个队列的粗略介绍,相信大家也能大致明白,为啥我会直接建议他去调大队列了。
因为从他的描述中提到了两个关键值,TCP连接数增加至1024个时,可用连接数会降至200以内,一般centos系统全连接队列长度一般默认 128,半连接队列默认长度 1024。所以队列溢出可以作为第一嫌疑对象。
全连接队列默认大小 128
[root@localhost core]# sysctl -a | grep net.core.somaxconn
net.core.somaxconn = 128
半连接队列默认大小 1024
[root@iZ2ze3ifc44ezdiif8jhf7Z ~]# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
总结
简单分享了一点TCP全连接队列、半连接队列的相关内容,讲的比较浅显,如果有不严谨的地方欢迎留言指正,毕竟还是个老菜鸟。
全连接队列、半连接队列溢出是比较常见,但又容易被忽视的问题,往往上线会遗忘这两个配置,一旦发生溢出,从CPU、线程状态、内存看起来都比较正常,偏偏连接数上不去。
定期对系统压测是可以暴露出更多问题的,不过话又说回来,就像我和小伙伴聊的一样,即便测试环境程序跑的在稳定,到了线上环境也总会出现各种奇奇怪怪的问题。
我是小富,下期见~
技术交流,公众号:程序员小富
本文收录在 Springboot-Notebook 面试锦集