JDK 從8升級到11,使用 G1 GC,HBase 效能下降近20%。JDK 到底幹了什麼?
編者按:筆者在 HBase 業務場景中嘗試將 JDK 從 8 升級到 11,使用 G1 GC 作為垃圾回收器,但是效能下降 20%。到底是什麼導致了效能衰退?又該如何定位解決?本文介紹如果通過使用 JFR、火焰圖等工具確定問題,最後通過版本逐一驗證找到了引起效能問題的程式碼。在畢昇 JDK 中率先修復問題最後將修復推送到上游社群中。希望通過本文的介紹讓讀者瞭解到如何解決大版本升級中遇到的效能問題;同時也提醒 Java 開發者要正確地使用引數(使用前要理解引數的含義)。
HBase 從 2.3.x 開始正式預設的支援 JDK 11,HBase 對於 JDK 11 的支援指的是 HBase 本身可以通過 JDK 11 的編譯、同時相關的測試用例全部通過。由於 HBase 依賴 Hadoop 和 Zookeeper,而目前最新的 Hadoop 和 Zookeeper 尚未支援 JDK 11,所以 HBase 中仍然有一個 jira 來關注 JDK 11 支援的問題,具體參考:http://issues.apache.org/jira/browse/HBASE-22972。
G1 GC 從 JDK 9 以後就成為預設的 GC,而且 HBase 在新的版本中也採用 G1 GC,對於 HBase 是否可以在生產環境中使用 JDK 11?筆者嘗試使用 JDK 11 來執行新的 HBase,驗證 JDK 11 是否比 JDK 8 有優勢。
環境介紹
驗證的方式非常簡單,搭建一個 3 節點的 HBase 叢集,安裝 HBase,採用的版本為 2.3.2,關於 HBase 環境搭建可以參考官網。
另外為了驗證,使用一個額外的客戶端機器,通過 HBase 自帶的 PerformanceEvaluation 工具(簡稱 PE)來驗證 HBase 讀、寫效能。PE 支援隨機的讀、寫、掃描,順序讀、寫、掃描等。
例如一個簡單的隨機寫命令如下:
hbase org.apache.hadoop.hbase.PerformanceEvaluation --rows=10000 --valueSize=8000 randomWrite 5
該命令的含義是:建立 5 個客戶端,並且執行持續的寫入測試。每個客戶端每次寫入 8000 位元組,共寫入 10000 行。
PE 使用起來非常簡單,是 HBase 壓測中非常流行的工具,關於 PE 更多的用法可以參考相關手冊。
本次測試為了驗證讀寫效能,採用如下配置:
org.apache.hadoop.hbase.PerformanceEvaluation --writeToWAL=true --nomapred --size=256 --table=Test1 --inmemoryCompaction=BASIC --presplit=50 --compress=SNAPPY sequentialWrite 120
JDK 採用 JDK 8u222 和 JDK 11.0.8 分別進行測試,當切換 JDK 時,客戶端和 3 臺 HBase 伺服器統一切換。JDK 的執行引數為:
-XX:+PrintGCDetails -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:-ResizePLAB
注意:這裡禁止 ResizePLAB 是業務根據 HBase 優化資料設定。
測試結果:JDK 11 效能下降
通過 PE 進行測試,執行結束有 TPS 資料,表示效能。

在相同的硬體環境、相同的 HBase,僅僅使用不同的 JDK 來執行。同時為了保證結果的準確性,多次執行,取平均值。測試結果如下:

從表中可以快速地計算得到吞吐量下降,執行時間增加。

結論:使用 G1 GC,JDK 11 相對於 JDK 8 來說效能明顯下降。
原因分析
從 JDK 8 到 JDK 11, G1 GC 做了非常多的優化用於提高效能。為什麼 JDK 11 對於應用者來說更不友好?簡單的總結一下從 JDK 8 到 JDK 11 做的一些比較大的設計變化,如下表所示:
| 優化點 | 描述 |
|---|---|
| IHOP 啟發式設定 | IHOP 用於控制併發標記的啟動時機,在 JDK 9 中引入該優化,根據應用執行的情況,計算 IHOP 的值,確保在記憶體耗盡之前啟動併發標記。對於效能和執行時間理論上都是正優化,特殊情況下可能會導致效能下降 |
| Full GC 的並行話 | 在 JDK10 中將 Full GC 從序列實現優化為並行實現,該優化不會產生負面影響 |
| 動態執行緒調整 | 根據 GC 工作執行緒的負載情況,引入動態的執行緒數來處理任務。該優化會帶來正效果,注意不是 GC 工作執行緒數目越多 GC 的效果越好(GC 會涉及到多執行緒的任務竊取和同步機制,過多的執行緒會導致效能下降) |
| 引用集的重構 | 引用集處理優化,設定處理大小、將並行修改為併發等 |
統一 JDK 8 和 JDK 11 的引數,驗證效果
由於 JDK 11 和 JDK 8 實現變化很多,部分功能完全不同,但是這些變化的功能一般都有引數控制,一種有效的嘗試:梳理 JDK 8 和 JDK 11 關於 G1 的引數,將它們設定為相同的值,比如關閉 IHOP 的自適應,關閉執行緒調整等。這裡簡單的給出 JDK 8 和 JDK 11 不同引數的比較,如下圖所示:
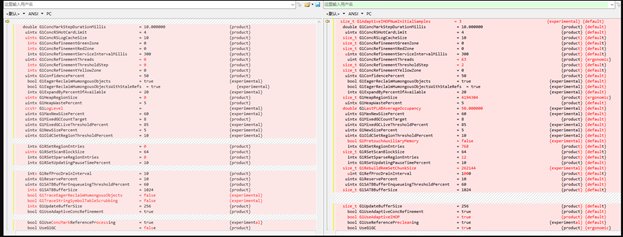
將兩者引數都設定為和 JDK 8 一樣的值,重新驗證測試,結果不變,JDK 11 效能仍然下降。
GC 日誌分析,確定 JDK 11 效能下降點
對於 JDK 8 和 JDK 11 同時配置日誌收集功能,重新測試,獲得 GC 日誌。通過 GC 日誌分析,我們發現差異主要在 G1 young gc 的 object copy 階段(耗時基本在這),JDK 11 的 Young GC 耗時大概 200ms,JDK 8 的 Young GC 耗時大概 100ms,兩者設定的目標停頓時間都是 100ms。
JDK 11 中 GC 日誌片段:

JDK 8 中 GC 日誌片段:
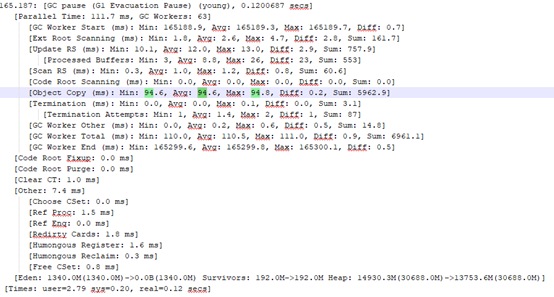
我們對整個日誌做了統計,有以下發現:
-
併發標記時機不同,混合回收的時機也不同;
-
單次 GC 中物件複製的耗時不同,JDK 11 明顯更長;
-
總體 GC 次數 JDK 11 的更多,包括了併發標記的停頓次數;
-
總體 GC 的耗時 JDK 11 更多。

針對 Young GC 的效能劣化,我們重點關注測試了和 Young GC 相關的引數,例如:調整 UseDynamicNumberOfGCThreads、G1UseAdaptiveIHOP 、GCTimeRatio 均沒有效果。
下面我們嘗試使用不同的工具來進一步定位到底哪裡出了問題。
JFR 分析-確認日誌分析結果
畢昇 JDK 11 和畢昇 JDK 8 都引入了 JFR,JFR 作為 JVM 中問題定位的新貴,我們也在該案例進行了嘗試,關於 JFR 的原理和使用,參考本系列的技術文章:Java Flight Recorder - 事件機制詳解
JDK 11 總體資訊

JDK 8 中通過 JFR 收集資訊。
JDK 8 總體資訊
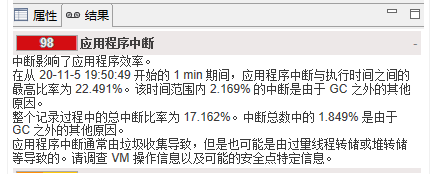
JFR 的結論和我們前面分析的結論一致,JDK 11 中中斷比例明顯高於 JDK 8。
JDK 11 中垃圾回收發生的情況

JDK 8 中垃圾回收發生的情況

從圖中可以看到在 JDK 11 中應用消耗記憶體的速度更快(曲線速率更為陡峭),根據垃圾回收的原理,記憶體的消耗和分配相關。
JDK 11 中 VM 操作
JDK 8 中 VM 操作
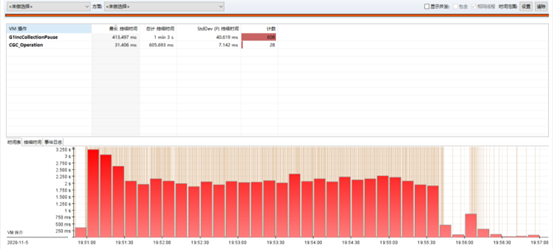
通過 JFR 整體的分析,得到的結論和我們前面的一致,確定了 Young GC 可能存在問題,但是沒有更多的資訊。
火焰圖-發現熱點
為了進一步的追蹤 Young GC 裡面到底發生了什麼導致物件賦值更為耗時,我們使用 Async-perf 進行了熱點採集。關於火焰圖的使用參考本系列的技術文章:使用 perf 解決 JDK8 小版本升級後效能下降的問題[1]
JDK 11 的火焰圖

JDK 11 GC 部分火焰圖

圖片 JDK 8 的火焰圖
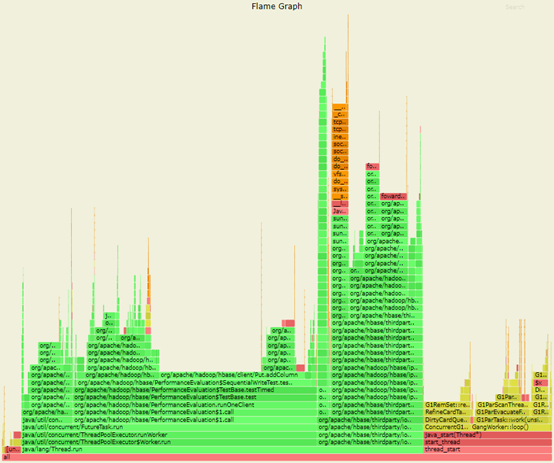
JDK 8 GC 部分火焰圖
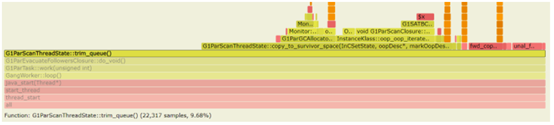
通過分析火焰圖,並比較 JDK 8 和 JDK 11 的差異,可以得到:
在 JDK 11 中,耗時主要在:
-
G1ParEvacuateFollowersClosure::do_void() -
G1RemSet::scan_rem_set
在 JDK 8 中,耗時主要在:
-
G1ParEvacuateFollowersClosure::do_void()
更一步,我們對 JDK 11 裡面新出現的 scan_rem_set() 進行更進一步分析,發現該函式僅僅和引用集相關,通過修改 RSet 相關引數(修改 G1ConcRefinementGreenZone ),將 RSet的處理儘可能地從Young GC的操作中移除。火焰圖中引數不再成為熱點,但是 JDK 11 仍然效能下降。
比較 JDK 8 和 JDK 11 中 G1ParEvacuateFollowersClosure::do_void() 中的不同,除了陣列處理外其他的基本沒有變化,我們將 JDK 11 此處的程式碼修改和 JDK 8 完全一樣,但是效能仍然下降。
結論:雖然 G1ParEvacuateFollowersClosure::do_void() 是效能下降的觸發點,但是此處並不是問題的根因,應該是其他的原因造成了該函式呼叫次數增加或者耗時增加。
逐個版本驗證-最終確定問題
我們分析了所有可能的情況,仍然無法快速找到問題的根源,只能使用最笨的辦法,逐個版本來驗證從哪個版本開始效能下降。
在大量的驗證中,對於 JDK 9、JDK 10,以及小版本等都重新做了構建(關於 JDK 的構建可以參考官網),我們發現 JDK 9-B74 和 JDK 9-B73 有一個明顯的區別。為此我們分析了 JDK 9-B73 合入的程式碼。發現該程式碼和 PLAB 的設定相關,為此梳理了所有 PLAB 相關的變動:
-
B66 版本為了解決 PLAB size獲取不對的問題(根據 GC 執行緒數量動態調整,但是開啟UseDynamicNumberOfGCThreads後該值有問題,預設是關閉)修復了 bug。具體見 jira: Determining the desired PLAB size adjusts to the the number of threads at the wrong place [2] -
B74 發現有問題( desired_plab_sz可能會有相除截斷問題和沒有對齊的問題),重新修改,具體見 8079555: REDO - Determining the desired PLAB size adjusts to the the number of threads at the wrong place [3] -
B115 中發現 B74 的修改,動態調整 PLAB大小後,會導致很多情況PLAB過小(大概就是不走PLAB,走了直接分配),頻繁的話會導致效能大幅下降,又做了修復 Net PLAB size is clipped to max PLAB size as a whole, not on a per thread basis [4]
重新修改了程式碼,列印 PLAB 的大小。對比後發現 desired_plab_sz 大小,在效能正常的版本中該值為 1024 或者 4096(分別是 YoungPLAB 和 OLDPLAB),在效能下降的版本中該值為 258。由此確認 desired_plab_sz 不正確的計算導致了效能下降。
PALB 為什麼會引起效能下降?
PLAB 是 GC 工作執行緒在並行複製記憶體時使用的快取,用於減少多個並行執行緒在記憶體分配時的鎖競爭。PLAB 的大小直接影響 GC 工作執行緒的效率。
在 GC 引入動態執行緒調整的功能時,將原來 PLABSize 的大小作為多個執行緒的總體 PLAB 的大小,將 PLAB 重新計算,如下面程式碼片段:

其中 desired_plab_sz 主要來自 YoungPLABSize 和 OldPLABSIze 的設定。所以這樣的程式碼修改改變了 YoungPLABSize、OldPLABSize 引數的語義。
另外,在本例中,通過引數顯式地禁止了 ResizePLAB 是觸發該問題的必要條件,當開啟 ResizePLAB 後,PLAB 會根據 GC 工作執行緒晉升物件的大小和速率來逐步調整 PLAB 的大小。
注意,眾多資料說明:禁止 ResziePLAB 是為了防止 GC 工作執行緒的同步,這個說法是不正確的,PLAB 的調整耗時非常的小。PLAB 是 JVM 根據 GC 工作執行緒使用記憶體的情況,根據數學模型來調整大小,由於模型的誤差,可能導致 PLAB 的大小調整不一定有人工調參效果好。如果你沒有對 YoungPLABSize、OldPLABSize 進行調優,並不建議禁止 ResizePLAB。在 HBase 測試中,當開啟 ResizePLAB 後 JDK 8 和 JDK 11 效能基本相同,也從側面說明了該引數的使用情況。
解決方法&修復方法
由於該問題是 JDK 9 引入,在 JDK 9, JDK 10, JDK 11, JDK 12, JDK 13, JDK 14, JDK 15, JDK 16 都會存在效能下降的問題。
我們對該問題進行了修正,並提交到社群,具體見 Jira:http://bugs.openjdk.java.net/browse/JDK-8257145[5];程式碼見:http://github.com/openjdk/jdk/pull/1474[6];該問題在 JDK 17 中被修復。
同時該問題在畢昇 JDK 所有版本中第一時間得到解決。
當然對於短時間內無法切換 JDK 的同學,遇到這個問題,該如何解決?難道要等到 JDK 17?一個臨時的方法是顯式地設定 YoungPLABSize 和 OldPLABSize 的值。YoungPLABSize 設定為 YoungPLABSize* ParallelGCThreads,其中 ParallelGCThreads 為 GC 並行執行緒數。例如 YoungPLABSize 原來為 1024,ParallelGCThreads 為 8,在 JDK 9~16,將 YoungPLABSize 設定為 8192 即可。
其中引數 ParallelGCThreads 的計算方法為:沒有設定該引數時,當 CPU 個數小於等於 8, ParallelGCThreads 等於 CPU 個數,當 CPU 個數大於 8,ParallelGCThreads 等於 CPU 個數的 5/8)。
小結
本文分享了針對 JDK 升級後效能下降的解決方法。Java 開發人員如果遇到此類問題,可以按照下面的步驟嘗試自行解決:
-
對齊不同 JDK 版本的引數,確保引數相同,看是否可以快速重現; -
分析 GC 日誌,確定是否由 GC 引起。如果是,建議將所有的引數重新驗證,包括移除原來的引數。本例中一個最大的失誤是,在分析過程中沒有將原來業務提供的引數 ResizePLAB 移除重新測試,浪費了很多時間。如果執行該步驟後,定位問題可能可以節約很多時間; -
使用一些工具,比如 JFR、NMT、火焰圖等。本例中嘗試使用這些工具,雖然無果,但基本上確認了問題點; -
最後的最後,如果還是沒有解決,請聯絡畢昇 JDK 社群(點選原文進入社群)。畢昇 JDK 社群每雙週週二舉行技術例會,同時有一個技術交流群討論 GCC、LLVM 和 JDK 等相關編譯技術,感興趣的同學可以新增如下微信小助手入群。

參考資料
使用 perf 解決 JDK8 小版本升級後效能下降的問題: http://mp.weixin.qq.com/s/aiuaB_VFw3A2iIexeizENA
[2]Determining the desired PLAB size adjusts to the the number of threads at the wrong place: http://bugs.openjdk.java.net/browse/JDK-8073204
[3]8079555: REDO - Determining the desired PLAB size adjusts to the the number of threads at the wrong place: http://bugs.openjdk.java.net/browse/JDK-8079555
[4]Net PLAB size is clipped to max PLAB size as a whole, not on a per thread basis: http://bugs.openjdk.java.net/browse/JDK-8150952
本文分享自微信公眾號 - openEuler(openEulercommunity)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- 玩轉機密計算從 secGear 開始
- openEuler資源利用率提升之道06:虛擬機器混部OpenStack排程
- openGauss Cluster Manager RTO Test
- JVM 鎖 bug 導致 G1 GC 掛起問題分析和解決【畢昇JDK技術剖析 · 第 2 期】
- 手把手帶你玩轉 openEuler | openEuler 的使用
- 681名學生中選!暑期2021開啟火熱“開源之夏”!
- 手把手帶你玩轉 openEuler | 初識 openEuler
- StratoVirt 中的 PCI 裝置熱插拔實現
- 使用 NMT 和 pmap 解決 JVM 資源洩漏問題
- JNI 中錯誤的訊號處理導致 JVM 崩潰問題分析
- Java Flight Recorder - 事件機制詳解
- 畢昇 JDK 8u292、11.0.11 釋出!
- StratoVirt 中的虛擬網絡卡是如何實現的?
- openEuler結合ebpf提升ServiceMesh服務體驗的探索
- 我的openEuler社群參與之旅
- StratoVirt 的中斷處理是如何實現的?
- 看看畢昇 JDK 團隊是如何解決 JVM 中 CMS 的 Crash
- 使用 perf 解決 JDK8 小版本升級後效能下降的問題【畢昇JDK技術剖析 · 第 1 期】
- 2021年畢昇 JDK 的第一個重要更新來了
- 漏洞盒子 × openEuler | 廣邀白帽共築安全的Linux開放應用生態