LLVM之父Chris Lattner:編譯器的黃金時代

作者|Chris Lattner
翻譯|胡燕君、周亞坤
摩爾定律失效論的討論與日俱增,2018年,圖靈獎獲得者 John Hennessey 和 David Patterson 在一次演講上更是直言,幾十年來的 RISC(精簡指令集)和 CISC(複雜指令集)孰優孰劣之爭可以終結了,新一輪計算機架構的黃金時代已經到來,為此,他們在2019年的 ACM 期刊上發表了一篇文章裡作專門論述 。
為了打破當前架構發展的桎梏,他們給出的答案是,需要軟硬體協同設計和創新,構建領域專用架構、領域專用語言,從而構建更專業化的硬體,並提升執行速度。
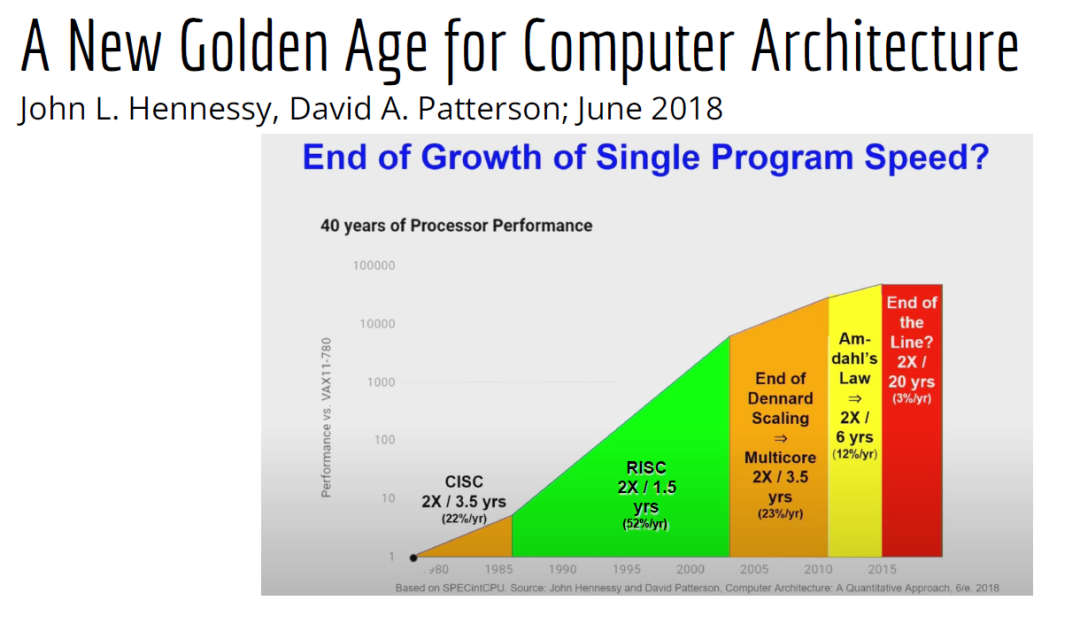
作為驅動計算機架構革新的重要組成部分,編譯器也在迎來它的黃金時代。就在去年4月19日的ASPLOS會議上,編譯器大牛Chris Lattner在主題演講中分享了關於編譯器的發展現狀和未來、程式語言、加速器和摩爾定律失效論,並且討論業內人士如何去協同創新,推動行業發展,實現處理器執行速度的大幅提升。OneFlow社群對其演講內容做了不改變原意的編譯,希望能對AI/編譯器社群有所啟發。
Chris Lattner 畢業於波特蘭大學的計算機科學系,具有建立和領導多個知名大型專案的經驗,其中包括 LLVM、Clang、MLIR和CIRCT等編譯器基礎設施專案,他還帶頭建立了Swift程式語言。
從2005年7月到2017年1月間,他曾領導蘋果的開發者工具部門,隨後,曾短暫領導過特斯拉的自動駕駛團隊。2017年8月,Chris Lattner 在Google Brain團隊領導了TensorFlow基礎設施工作,包括一系列硬體支援(CPU、GPU、TPU),底層執行時和程式語言工作。
2020 年 1 月到 2022 年 1 月,Chris Lattner 在 SiFive 公司領導工程和產品團隊(包括硬體、軟體和平臺工程),SiFive 基於開源指令集 RISC-V,向晶片設計公司提供 IP。去年 6 月,SiFive 收到了英特爾的收購意向,後者提出以超過 20 億美元的價格收購這家公司。2022 年 1 月,Chris Lattner 和 Tim Davis 共同成立了 Modular AI,他本人擔任CEO,目標是重建全球 ML 基礎設施。
以下是Chris Lattner的演講內容。
1
為什麼需要下一代編譯器和程式語言
儘管硬體正在蓬勃發展,新加速器和新技術不斷湧現,但軟體業卻很難真正利用它們。
為什麼會這樣?在加速器的世界裡,比如AI和結構化計算技術發展領域,出現了標量加速和向量加速等多種層面的加速,就像CPU領域也分為標量處理器和向量處理器一樣,當然現在還有多核CPU。這樣一來就會出現多種硬體組合,不同的硬體安裝在同一個資料中心,那這些硬體就必須相互通訊。
但是,很多時候卻沒有一致性的記憶體,導致寫一個C語言程式來執行所有東西是不可行的,這樣的組合執行有點像超級計算機使用多個CPU一樣。
同時,世界正在越來越異質化,出現了各種各樣的應用。機器學習快速發展,但機器學習涉及很多技術,如果你不止研究訓練和推理,還想研究強化學習,那就要了解不同的加速器。如果你想研究強化學習,就要整合主機計算和加速器計算,讓它們協同工作。現在製造的很多新裝置裡的IP和硬體塊都是可配置的,即便是隨儲存器層次深度改變快取大小這麼簡單的事,都會影響這些裝置執行所依賴的核心。
所以,儘管現在硬體越來越多樣,硬體生態迅速壯大,但軟體還是很難充分利用它們來提高效能。而且如果軟硬體協同不到位,效能就會受到巨大影響,那不止是10%左右的浮動,比如,如果弄錯了記憶體層次結構,效能很可能會發生斷崖式下跌,變成正常水平的十分之一。
當今,加速器領域發生爆炸式增長,幾乎每天都會有新公司製造新的加速器。但問題是,怎麼用這個加速器?更關鍵的是,有人想做新應用,但他們想在軟體程式碼庫上下工夫,於是不停地推進和完善軟體程式碼庫。
你無法直接在這個新裝置上使用舊的軟體堆疊,它們的某個部件可能換了供應商,做了流程精簡,導致所需的技術堆疊不一樣。因此,你不得不給每個新的小型裝置都寫一個全新的軟體堆疊。而這樣做又導致了軟體的碎片化,這種碎片化的發展帶來了巨大成本,也會反噬硬體行業,因為硬體用不了了。
我的觀點是,我們需要下一代編譯器和程式語言來幫助解決這種碎片化。首先,計算機行業需要更好的硬體抽象,硬體抽象是允許軟體創新的方式,不需要讓每種不同裝置變得過於專用化。
其次,我們需要支援異構計算,因為要在一個混合計算矩陣裡做矩陣乘法、解碼JPEG、非結構化計算等等。然後,還需要適用專門領域的語言,以及普通人也可以用的程式設計模型。
最後,我們也需要具備高質量、高可靠性和高延展性的架構。 我很喜歡編譯器,很多人根據編譯器在做應用,我也很尊重這一點。可以說,他們在開發下一代神經網路,而不僅僅只想做編譯器。大家可以合作,這樣一來就意味著他們需要可用的環境和可用的工具。
令人興奮的是,編譯器或者程式語言工程師會迎來一個嶄新的時代:過去和現在都有無數的技術誕生,這些技術正在改變世界,有幸參與這場變革浪潮非常令人激動。
接下來,我會談談編譯器行業的早期發展,以及它帶給我們的經驗和對未來的啟發。
2
傳統編譯器的設計和挑戰
當我還是學生時,編譯器是單獨裝盒的,安裝在一個軟盤上,每次使用都要把軟盤插進電腦裡。

當時的行業狀況是,不同的供應商做出不同的處理器、作業系統,都想要通過創新脫穎而出,抓住編譯器的價值。這些編譯器都是專用的,互不相容,不會共享程式碼。所以你會看到Borland C編譯器和Microsoft C編譯器互相競爭,最終造成碎片化生態。這就阻礙了行業發展,但人們還沒有意識到這一點。
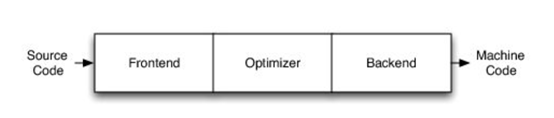
編譯器由前端、優化器和後端組成,這種固定結構已經沿用很多年了。如果一家公司自主研發了一個編譯器,通常的做法是隻研發一套前端和後端,而不會投入太多資金研發多種前端和後端。其他公司也會這麼做,這導致不同公司的優化器和前後端不能通用。
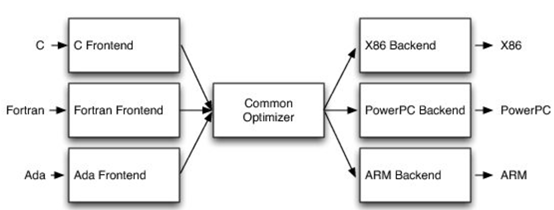
GCC編譯器團隊最早打破了這種模式。GCC通過自由軟體和開放許可證,允許互相合作,這使得人們可以將前端、優化器、後端分開設計,實現“關注點分離”。也因為這個原因,GCC有了多種前端和後端。
這樣的“關注點分離”不但有利於編譯器的研究改進,還改變了編譯器的行業格局。因為GCC有最好的C++前端,所以一大批編譯器工程師都在這個前端的程式碼庫基礎上改進,推動了創新和C++的發展。同時,一大批CPU公司可以直接運用GCC的前端,只需加上自己的後端就能參與市場競爭。因此20世紀90年代到21世紀初這段時間,整個行業的碎片化程度降低。從那時起,GCC為C語言編譯器的發展鋪平了道路,湧現出更多新編譯器。這是行業的巨大成功,因為它點燃了創新的火把。
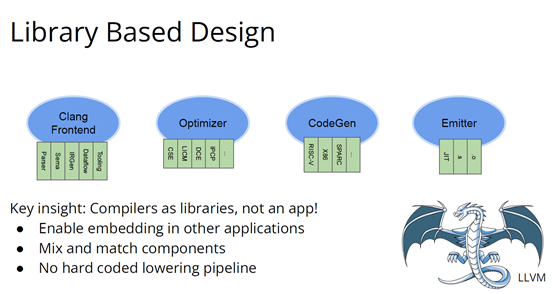
繼GCC的革新之後又出現了一些新技術,其中包括我自己特別喜歡的LLVM,我想講的是它的模組性。它顛覆了編譯器長久以來的“前端+優化器+後端”的三段結構,LLVM編譯器是一系列庫(library)的組合。檢視LLVM程式碼庫會發現,所有程式碼都在lib目錄下。
這些庫可以單獨拎出來,與其他庫組合、搭配使用,也可以重複使用。它可以和電影特效處理引擎、資料庫查詢引擎結合起來,LLVM既是一個優秀的C++編譯器,也可以發揮更廣泛、更有創新性的用途。
LLVM的模組性凸顯了介面和元件的重要性。自LLVM誕生的20多年來,沒有了前端、優化器、後端的劃分,它用一種革新的方式推動了編譯器行業的發展。比如可以把XA6編譯器或者X86後端用到別的地方,還可以集中全世界頂尖專家來專門單獨研究暫存器分配器,而不用管其他編譯器元件,這樣既提高了擴充套件性,也催生了新的合作形式。
LLVM的一大優點就是可以集合更多人的力量,實現更多創新。很多基於LLVM的新前端已經誕生,而且它促進了Julia語言、數字程式設計、Rust和Swift語言、系統程式設計、安全程式設計模型等大力發展,這讓人倍感興奮。LLVM的模組性、IR的獨立性、低碎片化程度也催生了多種語言。
此外,LLVM還讓JIT編譯(即時編譯)能有更多作為。雖然JIT編譯器已經是一種著名的技術,但它一開始是用在其他地方。有了LLVM以後,晶片設計、HLS工具、圖形處理、都更加便捷,還促進了CUDA和GPGPU的誕生,這些都是很了不起的成就。
但更重要的的是,LLVM整合了的碎片化。LLVM出現之前有很多種JIT編譯器框架,但LLVM的存在,提升了JIT編譯器的基線,讓它迸發出更多可能,也讓行業可以實現更高層次的創新。
話說回來,LLVM雖然有很多優點,但它同樣存在很多問題。一開始LLVM的目標是成為一個“萬能”的解決方案,但結果它好像什麼也沒做好。很多人不斷給LLVM加一些“亂七八糟”的東西,你可以對CPU和GPU可以這麼做,但對加速器來說不太行。這種胡亂做“加法”就導致不能很好地用LLVM做並行處理優化。但我喜歡LLVM的一點是,它是一個很好的CPU後端,儘管並不能很好滿足其他需求。
現在我們來到了“摩爾定律失效期”,我們可以發揚LLVM作為CPU後端的優點,但如果要探索CPU以外的功能,應該把目光放到LLVM IR之外。
3
構建適用專用領域的架構
Patterson和Hennessey提出過一個結論:我們來到了計算機架構的文藝復興時代,需要把計算機行業上下游人員垂直整合起來,大家既要懂硬體,也要懂軟體。他們說,因為世界變化得很快,所以思考問題時要回歸第一性原理,要用新的眼光去重新看待舊事物。
接下來我會講講加速器的構建過程,並結合經驗談談加速器未來可能的演變。
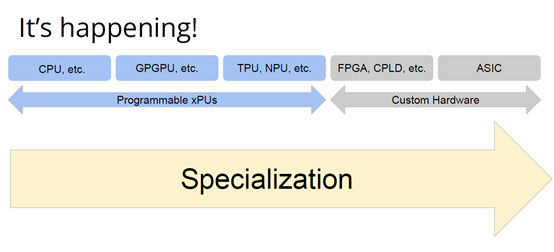
如果觀察硬體領域,會發現專用化架構已成為一種趨勢,分化出一系列的專門品類。關於這個話題,我推薦觀看Mike Urbach的演講。如果把CPU看作通用型處理器,那麼當你想控制所有的門(gate)時,就需要更深的專用化和更多硬編碼能力。
所以一方面CPU是通用的,不像矩陣運算加速器那麼專用化。然後出現了GPGPU,很靈活,功能也很強大,但要對GPU進行程式設計就沒那麼容易了。然後針對機器學習加速又出現了TPU,可以做大矩陣乘法運算和直接卷積等操作。這些是可程式設計的各種“xPU”,除此之外還有FPGA(現場可程式設計門陣列)等固定功能硬體,你可以重新配置block之間的線路;再進一步細分的話還有ASIC,也就是可以應特定需要專門設計積體電路。
總體就這兩個大類,一類是通用的、可程式設計的,另一類是功能比較固定的。每當我思考領域專用架構時,我的腦海裡就會浮現這兩大類。
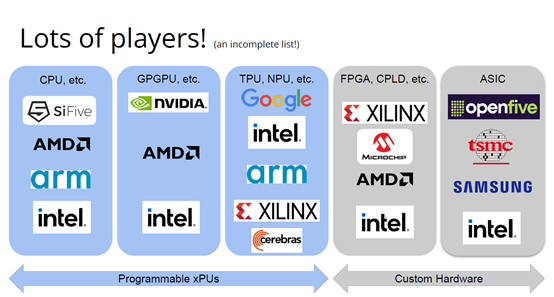
上圖列舉了一些正在做上述硬體的公司(不完全統計),可以看到有不少都是行業巨頭。每個公司研究的時候都會思考:怎麼給它程式設計?而每個公司也會給出不同的答案。比如Google在做XLA和TensorFlow,NVIDIA在做CUDA,Intel在做oneAPI,還有很多硬體公司在做自己的硬體設計工具包等等。

問題是,每個工具針對的都是不同問題,它們不協同,也不相容。因為它們是每個公司的小型團隊自主研發的,共享的程式碼不多,而每個公司也都孜孜不倦地給自己的工具增加新功能,各個工具都瞬息萬變,造成比較混亂的整體局面。這些工具作為行業的基本元件,卻有這麼多不同特點,那從行業層面應該怎麼做?

其實今天的加速器遇到的問題,90年代的C語言編譯器也遇到過。就像人們常說的那樣,歷史是一個輪迴。我們見證了硬體和軟體的多樣性爆發,但如果想要繼續發展,這種多樣性就會成為阻礙。
所以我們需要統一,需要一些類似GCC和LLVM這樣的東西,不然都要忙著為每個特定的裝置開發一個專屬後端,就沒時間進行前端、程式語言和模型的創新了。
業內有許多精英人才,但還不夠多。假如我們能夠減少碎片化,把行業整合起來,就可以促進創新,加快行業發展,持續建立技術堆疊,充分利用硬體,並以全新方式利用異構計算。
接下來談談我對加速器發展的看法,以及發展過程中可能遇到的挑戰。
4
加速器的本質和演進
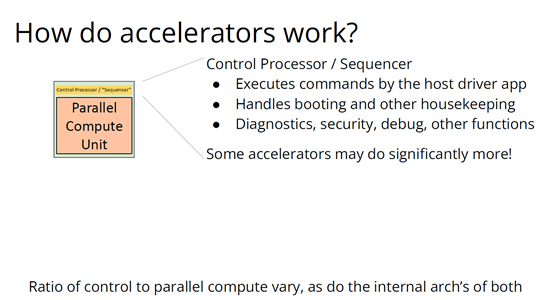
加速器是什麼?可以把它高度簡化成兩個部分,第一個是平行計算單元。因為矽本身的結構也是並行的,加速器要用到許多電晶體,也就需要很多矽來達成這種並行處理能力。
第二個部分起控制作用。它的名字不太統一,有人叫它“控制處理器(Control Processor)”,有人叫它“序列器(Sequencer)”。有人希望它小一點,所以會做狀態機然後嵌入暫存器。這個部分基本上起到編排平行計算單元的作用。如果平行計算單元是一個大型矩陣乘法單元,控制處理器就會命令它執行一些巨集操作,例如從這個記憶體區載入、執行某一操作、執行另一操作、更新SRAM等。
還有一些加速器很不一樣,所以控制邏輯和計算之間的比率也各有不同。正如Patterson和Hennessy所說那樣,你可以選擇不同的點,但每個點都需要一定程度的編排。
但人們常常忘記其他一些相關的工作,比如,你不止需要編排,還要解決啟動問題,比如電源管理,還要不斷除錯排錯。如果你想做得盡善盡美,可以對這些部件進行程式設計;如果你希望簡單一點,可以把這些部件做得很小。

當控制處理器和平行計算單元都齊備之後,怎麼給它們輸入和輸出資訊?這時就需要一個記憶體介面。根據抽象等級的不同,這個記憶體介面可以是小型的block,也可以是支援物聯網的晶片,這樣加速器就可以和該晶片連線整個網路通訊了。這裡需要用到像AMBA或類似的技術。
你可以在更大的粒度(granularity)上構建整個 ASIC,所有的 ASIC 都在加速,在這種情況下,你可能正在與 PCI 通訊,並且正在晶片外直接訪問記憶體,但這種“我有一個控制處理器,有一個計算單元和有一個記憶體介面”的模型,是構建這些東西的一種非常標準的方法。
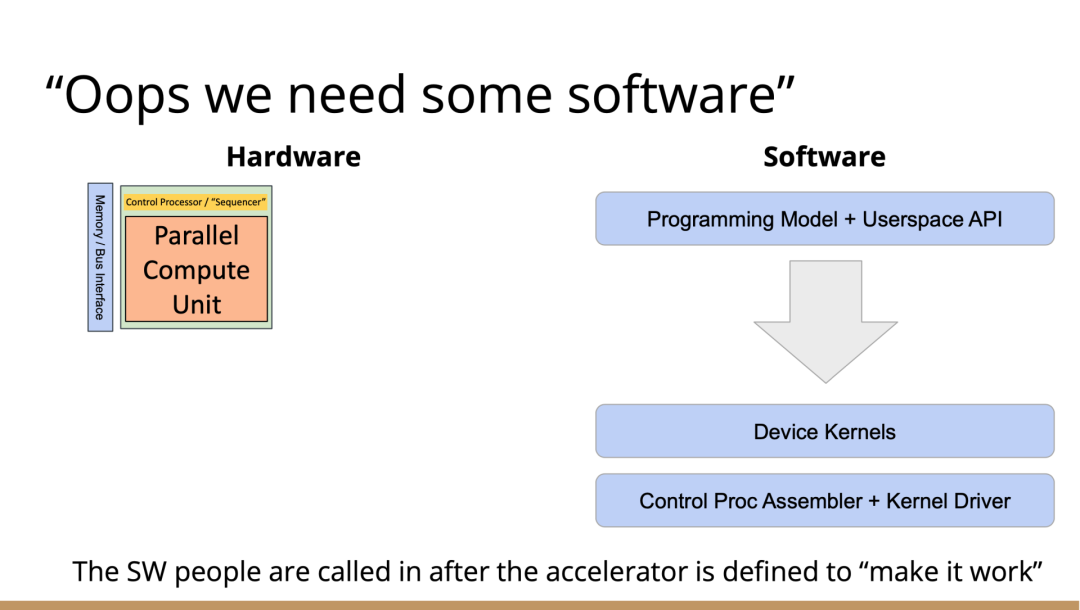
一旦這些結構問題解決了,架構師們就開始大展拳腳,但他們往往忘記還需要軟體人員參與進來。
理想情況下,他們會從最基本的問題開始著手解決,但軟體最終看起來像按照幾個不同的層次來做。最高層次是考慮使用者體驗,使用者如何使用?要如何圍繞它構建一個應用程式?而最低層次則是考慮控制處理器的執行,所以至少需要一個彙編器來完成要處理的控制過程。
然後寫一個執行在某種主機處理器上的驅動程式來控制這個東西,控制它開啟和關閉,進行載入,把程式上傳到控制處理器。之後有一些工作在這些控制處理器上執行,所以這些通常被稱為核心。這個模型很通用,但最終的結果是硬體變得更復雜。所以第一代協同處理器(first generation co-processor)可能很簡單,但後來有人想出了這個絕妙的主意:我們想實現更多。
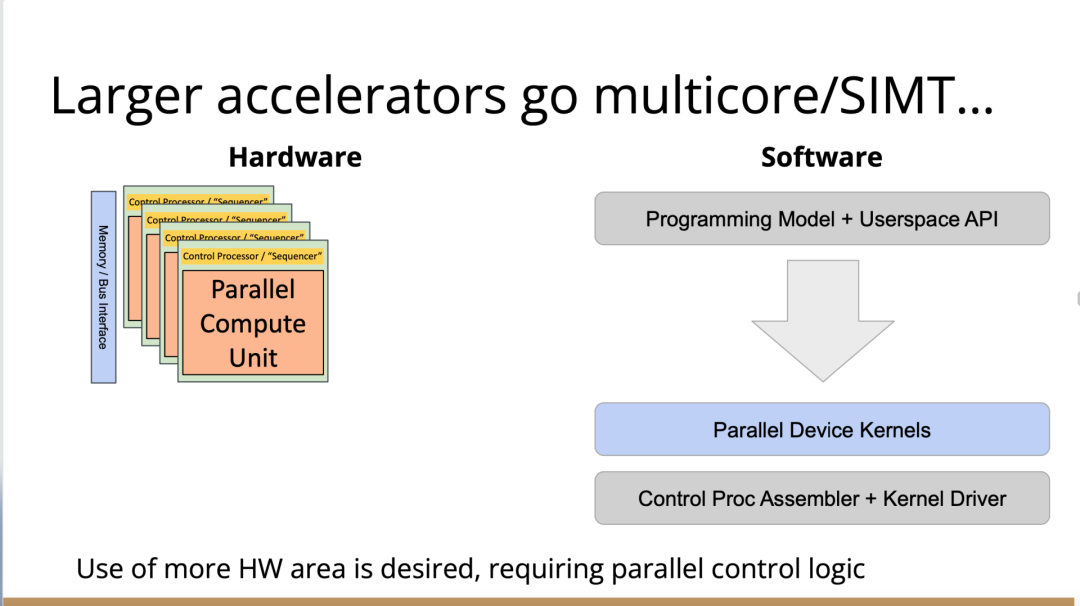
在這種情況下,我們想減小面積來進行加速,想做更多的AI、物理、5G或比特幣等領域的任何值得加速的東西。最終的結果需要更多的控制處理器,因為光速和線延遲等問題會導致不能只用一個控制處理器在一個巨大的晶片上協調所有的電晶體,所以你需要多個控制處理器並行處理。
幸運的是,這很容易放進你的模型裡,因為只需要將這些裝置核心並行化、多執行緒化或做一些展開(tiling),只需做一些簡單的改動就可以了。然後,在這些淡褐色單元上執行的核心就可以一起協作解決問題,把任何問題在空間上進行分解,再並行處理。
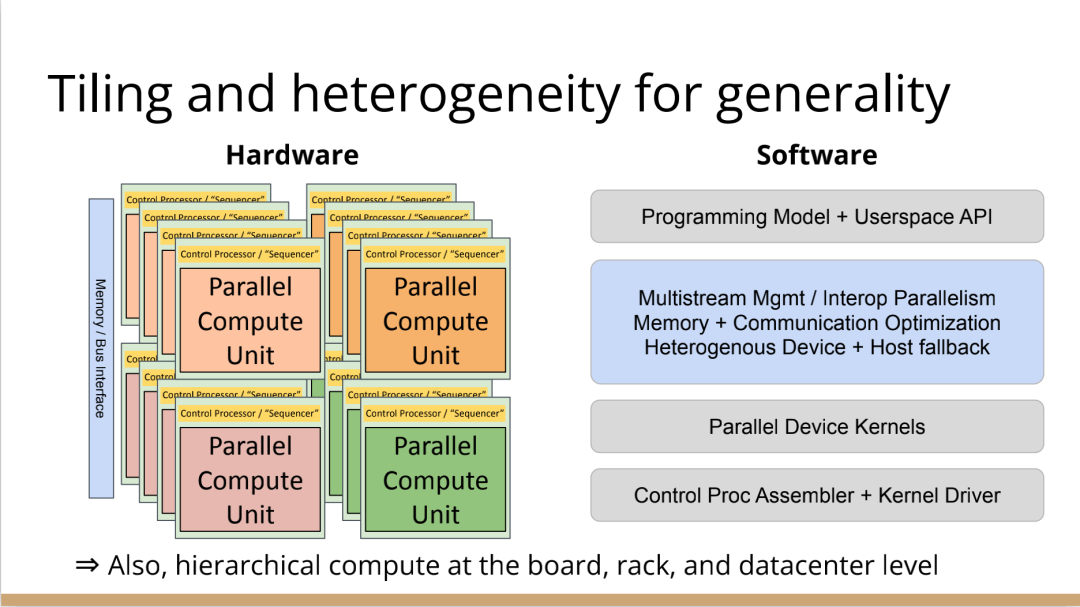
現在開始,事情變得更加複雜。當建立一個像GPU一樣專門的加速器,比如要把數十億個電晶體組裝成一個完整的十字形晶片。這種規模的晶片會產生多方面的問題。
首先,你最終想有多層次的平鋪,所以不會只想擁有492個核,你可以在GPU上有陣列,或者有不同的SMS或類似的東西。或者將有異質性介入,所以在同一物理晶片上將有不同種類的加速器,因為我可能正在做AI,但需要能夠解碼一些JPEG。因此,如果我打算在相機上做推理,需要對相機的感測器資料進行原始解碼,這將得到新的加速器block,它們是硬編碼用於不同操作,而且這些都混在一起。
然後它們需要通過記憶體介面相互通訊,這需要對其進行程式設計,並且變得更加複雜。現在突然需要這個中間層的技術,在加速器上處理多個數據流時,不只是在加速器上不同單元的tile上有並行性。因為現在有多個不同的操作在同時執行,所以要解決工作負載平衡的問題。
此外,還要解決通訊優化問題,光速是一個痛點,因為把資料從晶片的一端傳到另一端需要時間。但是這段時間你不想閒著,而是想在通訊的同時進行另一個通訊過程,或者在做通訊的同時進行計算。
你希望能夠執行像TensorFlow一樣的東西,現在你可能有一個XA6後置處理器,所以希望從加速器回到主機處理器。因為你在做檔案系統操作或其他非常奇怪的事情,就必須能夠協調這一點,突然,這層軟體開始變得非常大,而且相當複雜。
在很多情況下已經證實了這一點,很多加速器都經歷過這種情況。一個問題是,他們一開始都是手工寫的kernel,這些東西有多個不同的進化步驟,從這些硬體供應商的產品中可以看到:隨著時間的推移,他們的硬體不斷進化,變得越來越普遍,軟體堆疊和支援的功能也在不斷進化。
所以kernel的優點是,它是最簡單好用的開始方式。一個硬體人員與一個韌體人員配對,就可以清楚地知道硬體的作用。軟體人員和硬體人員通過協同設計緊密合作,讓你的矩陣乘法在AI工作負荷上執行得非常快。它的抽象程度很低,很容易搞定。
問題是,這並沒有真正擴充套件能力。所以我們也看到,現在想在加速器上執行的工作負載不僅僅是矩陣乘法,他們想要在這些東西上執行成百上千種不同的核運算,涵蓋從卷積和矩陣乘法到重塑(主要是記憶體操作)到元素間操作(element-wise operations),再到各種奇怪的操作,比如Top K和排序,再到非常普遍的新一代研究稀疏演算法的東西和其他新興的不同應用。
隨之而來的問題是,一方面你有這些正在執行的kernel,另一方面,你有硬體的無限通用性。因此,在一個供應商的硬體中,也許你可以把它固定然後看看新一代的技術。
你只需要手寫一百或一千單位的kernel就行了。也許這沒問題,但當你推出了第二代裝置,可能改變了記憶體層次結構,給控制處理器增加了一些新指令,增加了可選的功能,或者你決定做kernel融合,想對卷積進行元素間操作,這時你就有一個n次方的不同kernel的組合需要很好地融合。即使你有成千上萬個軟體工程師,你也不能手寫所有的kernel,因為你希望你的硬體團隊能夠快速推進工作。
我見過這種情況好幾次了,最終人們開始手寫kernel,但後來他們寫了一個Python程式來生成kernel,這些Python程式在某種意義上就像微型編譯器。
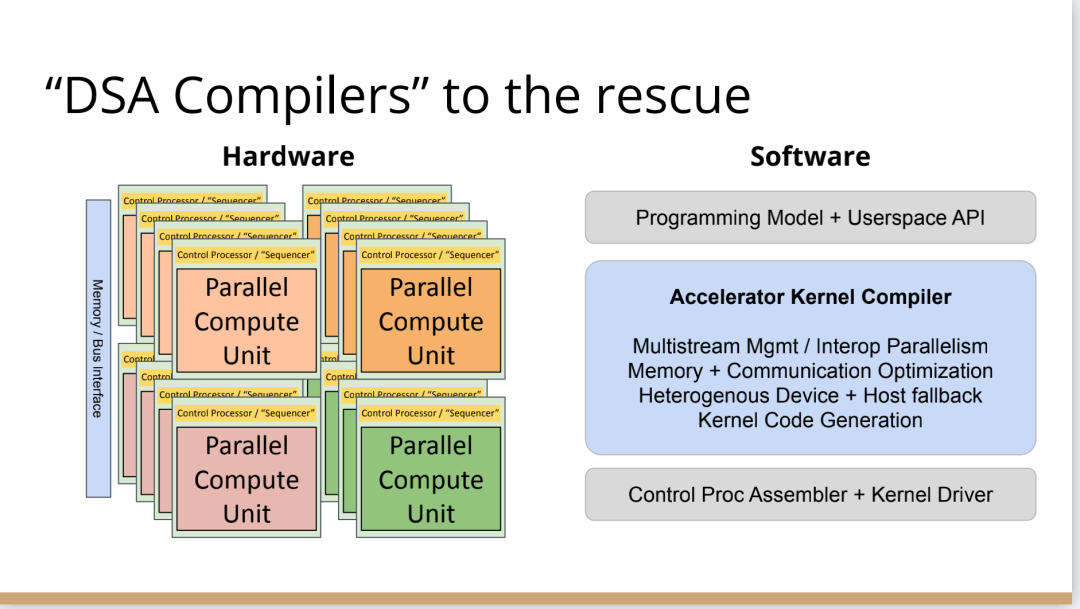
如果繼續這樣做,這些複雜性就會疊加起來,最終形成了這個編譯器層,它可以通過強大的編譯器工程來形成。這在理論上是可能的,隨著時間的推移,它可以通過自然演變逐漸形成,就像人類從爬行到行走一樣,這是我在實踐中所看到的真實情況。每個人都有機會成為這個過程的締造者,這方面還有很大的進步空間。
當你在構建一個真實的東西時,實際上很困難。剛開始感覺容易,是因為可以構建一個小型控制處理器和小型加速器,讓一些軟體執行得很快,這種情況下很簡單。但當你沿著“這條路”繼續走,困難會慢慢出現,實際上,直到遇到擴充套件問題之前都不會覺到特別難,但你不想改變方向了。
此外,正如我們之前所說的,產品質量並不一直都很好。現在,人們創造出令人驚歎的產品,而我也一直對這個行業中不斷髮生的創新感到驚訝。但我們也見過一些編譯器崩潰了,比如技術堆疊中出現的壞訊息。
這是有道理的,人們就不會總在這方面投資。雖然我能理解這種做法,但這阻礙了行業發展,導致使用這些工具變得更加困難。因此,要減少社群中願意容忍和使用這些工具的人。
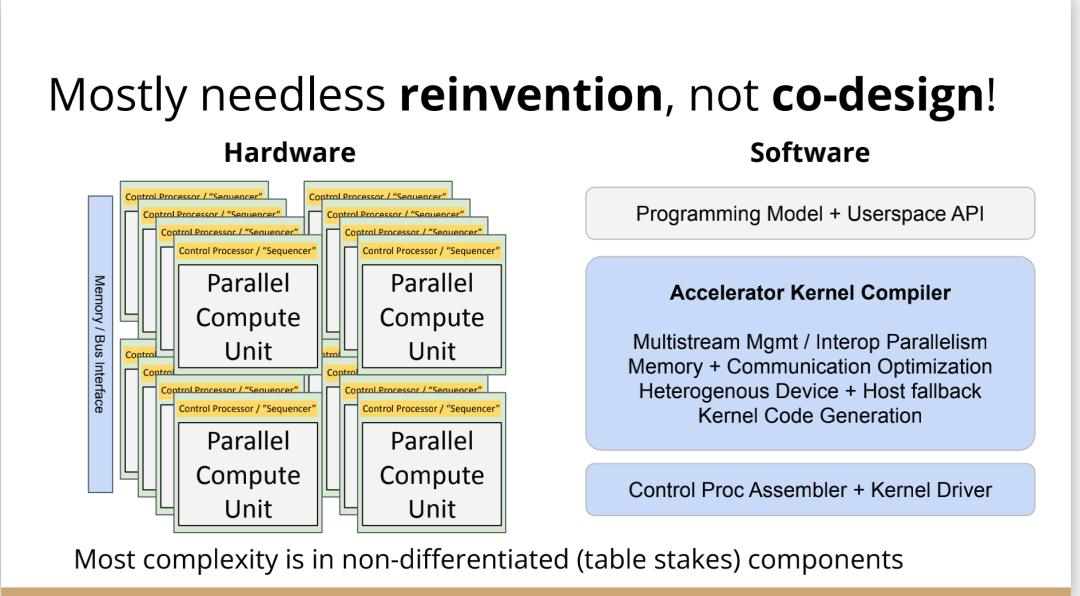
我認為另一個真正的問題是,大部分複雜性真的與解決加速器問題無關。如果我想建立一個5G網路加速器,需要考慮5G、FTS、問題中固有的並行性以及如何利用它們。如果要考慮人工智慧機器學習的工作量,我應該考慮的是算數運算以及計算和記憶體的正確比例等等。但相反,我們通常需要在和這些重要的問題無關的事情上投入很多時間,以複雜性而告終。
如果你把與加速器有關的重要東西抹掉,剩下的就是控制處理器的核心驅動和彙編程式以及像所有這些複雜的多流管理小組,該如何利用加速器上的所有tiles。
這不是我們想花費時間的地方,要花時間在程式設計模式、硬體等方面進行創新,但這種碎片化是真正阻礙行業發展的原因。
因此,我的主張是創新程式設計模型,發展新的應用程式,通過不斷創新推動行業向前發展。我們應該對此過程所需的一切實行標準化,通過標準化能夠快速完成工作,然後就可以把時間花在真正重要的事情上。

那麼,如何做好這個工作?幸運的是,業界已經開始對我們需要的所有介面匯流排進行標準化。如果你與你知道的SoC結構連線,通常使用AMBA或CHAI或類似的東西。如果要和記憶體連線,那麼你要用DDR或HBM這樣的東西。如果你要在系統中建立一個外掛卡,要使用像PCI Express這樣的東西。有一些新的標準,如CXL定義了新的方式,可以將PCI普遍化,並允許在更大規模的系統中使用新型加速器,但我們需要更進一步。

那麼,這個控制處理器呢?需要注意的是,當我們觀察加速器,開發在加速器上面執行的軟體最終比打造硬體的成本更高。況且在這一點上,硬體是更被人熟知的。不同硬體有不同配置,但構建軟體是一個尚未解決的問題。
控制處理器也在堆疊的底部,所以當我談到系統設計中存在這些微妙的陷阱時,事情看起來很容易,但更進一步會發現它們很困難。控制處理器是其中一種情況,剛開始,你考慮的是用小型狀態機來控制它,所以我會在電子表格程式寫一個編譯器。
有時候要意識到需要做電源管理,還要考量安全性,需要構建和協調這些東西的困難部分,真正改變它們最終的工作方式。如果構建控制處理器的人沒有同時構建編譯器,那麼他們就不會感受到構建軟體的痛苦,而軟體最終是更困難的部分。

Patterson和Hennessey在他們的演講中談到了這一點,他們從60年代開始觀察到行業存在著巨大的碎片化。IBM最終解決這個問題的方法是標準化指令集,選擇的是IBM 360指令集,至今仍在使用。這是一個驚人的壯舉。
所以,我們要做出選擇,比如我們是否要標準化這些控制過程。我們會使用IBM 360嗎,還是我們要用一些新的東西?

我認為,我們應該使用一些新東西,有一種指令集技術叫做RISC-V,它是CPU的一個開放的行業標準。我喜歡RISC-V的原因是,它是一個模組化的指令集,就像LLVM一樣是模組化的、基於庫的。如果不想用浮點數,它允許把指令集的不同部分劃分子集出來。
但是,如果你不想要整數乘法,也可以把它去掉。關於RISC-V的偉大之處在於,它不僅提供了一個指令集標準,還提供了在上面執行的整個軟體世界。因此,你可以得到一個C語言編譯器,得到Linux,得到所有圍繞RISC-V的這些東西。
像SiFive這樣的公司,它製造了很多不同的RISC-V處理器。你可以在設計領域中得到許多不同的視角,以不同的權衡點來實現該規範。因此,如果你正在建立一個非常簡單的加速器,如矩陣乘法或卷積加速器,可以有一個非常小的RISC-V核來控制一個大的硬編碼加速器block。
另一方面,如果你想要更多的可程式設計性,你可以改變花費在控制和並行處理上的矽的比例,並且有更多的控制邏輯,從而實現更多的可程式設計性和靈活性,可以調整比率。
也可以反過來,並行單元是處理器的一部分,使用這個處理器時,在處理器內建一個異構計算加速器。
或者相反,你可以把這個加速器中的每一個tile視為一個很大的CPU,這樣做就會得到像Graviton這樣的雲加速器,例如,你有一堆不同平鋪的CPU,通用性和加速的功能都可以在一個指令集內處理,這就允許提升軟體的生態系統。
你可能會擔心,如果想構建這樣一個微小的控制處理器,RISC-V會如何解決這個問題?很明顯,一般的解決方案太大了。有一些非常小的RISC-V的實現,你可以得到開源的標準化的RISC-V,大約有一萬五千種gates的實現,這是矽行業的美妙之處。因為有很多gates,可以不必擔心在控制處理器上花費太多gates,得到最符合需求的解決方案。

一旦這樣做,它改變了構建加速器的方式。以前你從選擇一個控制處理器開始,然後寫一個彙編程式或RISC-V給出一個彙編程式。但RISC-V不僅給出一個彙編程式,還給了一個C語言編譯器和一個可以程式設計的IR。
因此,可以針對控制處理器來生成核心。不僅可以得到C語言編譯器,還可以得到模擬器和偵錯程式。我從來沒有見過其他可以為模擬器和晶片安裝GDB、LLDB的加速器,這不是人們通常會投資的技術,因為它是一次性的。但是,通過建立和利用RISC-V的生態系統,你可以投資並再次構建下一個級別的技術,從而獲益。
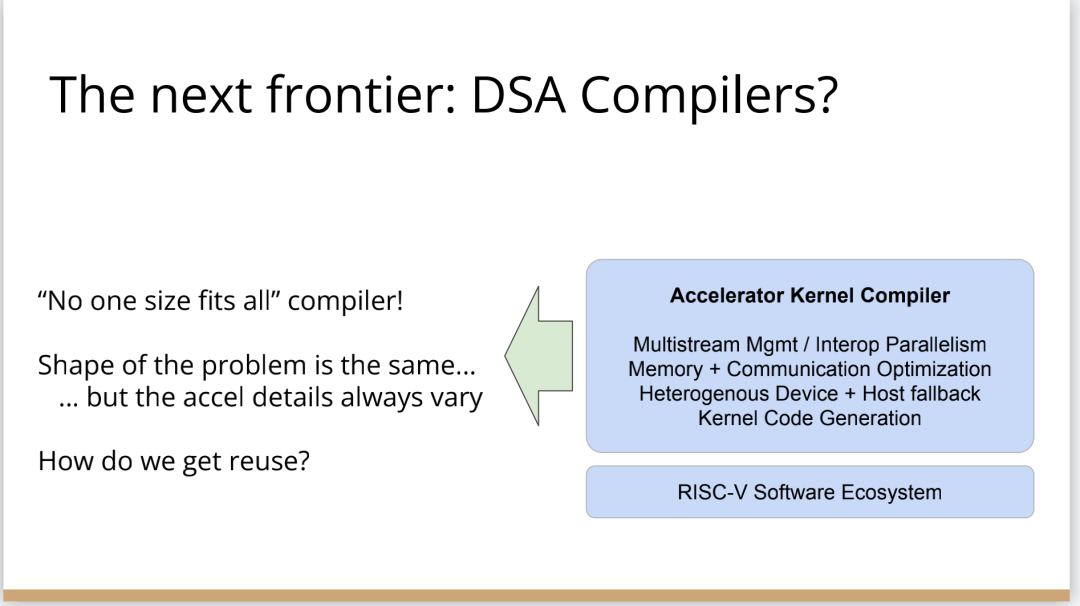
一旦做到這一點,就進入到下一層級的複雜性。做出了這個類似加速器核心編譯器的東西后,就會遇到下列問題:如何進行分層平行計算?一個數據中心有很多機器,電路板上有多個晶片?每個晶片在一個ASIC中有幾十個或上百個不同的加速器單元,又該如何程式設計?
有趣的是,雖然所有這些編譯器都是不同的,但它們有很多共同的特點。比如,都有記憶體層次結構,都有多個不同粒度級別的tiling,都需要能夠與其互動。所以,儘管這些編譯器是不同的,例如一個5G基站的編譯器應該與AI加速器不同,但像平鋪和記憶體層次結構這種需要解決的技術問題都是一致的。

現在有一種相對較新的編譯器技術MLIR可以幫上忙。你可以把MLIR看作是一個元編譯器,它允許你非常快速地構建加速器/編譯器。MLIR的全稱是“多級中間表示”,它支援構建分層編譯器,並以適用專門領域的方式構建,同時保留領域的複雜性。然後,使用MLIR提供的大量庫和例程來做一些事情,比如,用多面體編譯器來做迴圈展開和迴圈融合等等。
所以MLIR是LLVM技術家族的一部分,它繼承了LLVM的設計方法和使LLVM如此偉大的理念,所以有了模組化、可擴充套件性,有一個由友好的人們組成的偉大社群。我認為,LLVM社群的一件令人欣賞事是:LLVM是模組化的,有相當好的文件,很容易學習,適合用於研究。
我很高興看到MLIR的出現。儘管它只有幾年的歷史,但它已經被廣泛用於從CPU程式碼生成到GPU、機器學習、FPGAs以及硬體等領域,此外,也用於量子計算和編譯器本身的MLIR優化模式應用。在MLIR這個領域有很多有趣的事情發生。
MLIR的另一個優點是,直接在LLVM的基礎上分層。它使用LLVM的庫,所以可以做即時編譯,寫核心然後編譯成LLVM IR也很容易。當然,LLVM也有很好的RISC-V程式碼生成支援。你可以用一種非常簡單、漂亮且可組合的方式構建基於RISC-V的加速器。
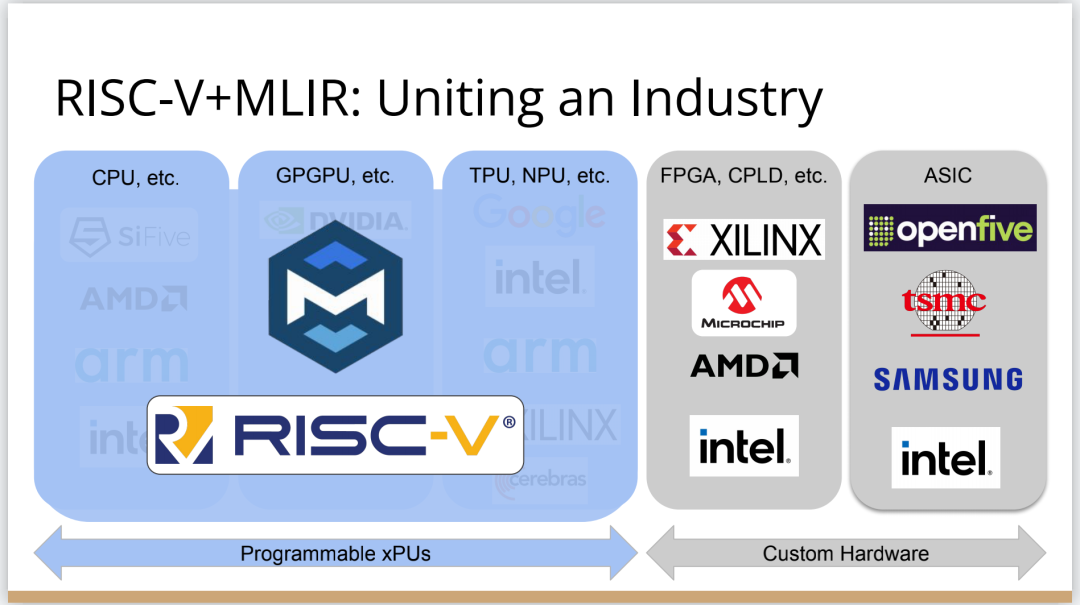
現在,我們開始看到的是,MLIR開始統一異構計算的世界,這也是我希望看到的。所有的大公司現在都在不同程度地使用MLIR,我認為,建立在RISC-V之上的MLIR很有必要,因為一旦開始從下往上整合行業,就可以開始把越來越多的層(layer)拉到一起,重複使用更多的技術。這使得我們可以專注在堆疊中更有趣的部分,而不是一遍又一遍地重新發明輪子。
我們能從中得到什麼?如果我們能把稀缺的編譯器和程式語言的能量整合到一起,讓這些人一起工作,那麼這個行業可以取得更多成就。如果我們一而再、再而三地重新發明輪子,我們就會互相拉扯。
作為一個產業,我們需要的是更多的創新,更多的程式設計模型,更多的技術和基礎設施,真的要減少行業的碎片化,提高其他未解決事物的模組化,然後專注於真正重要的部分。
我剛剛一直在談論加速器,談到了從CPU到TPU和GPU等各種不同的“xPU”。
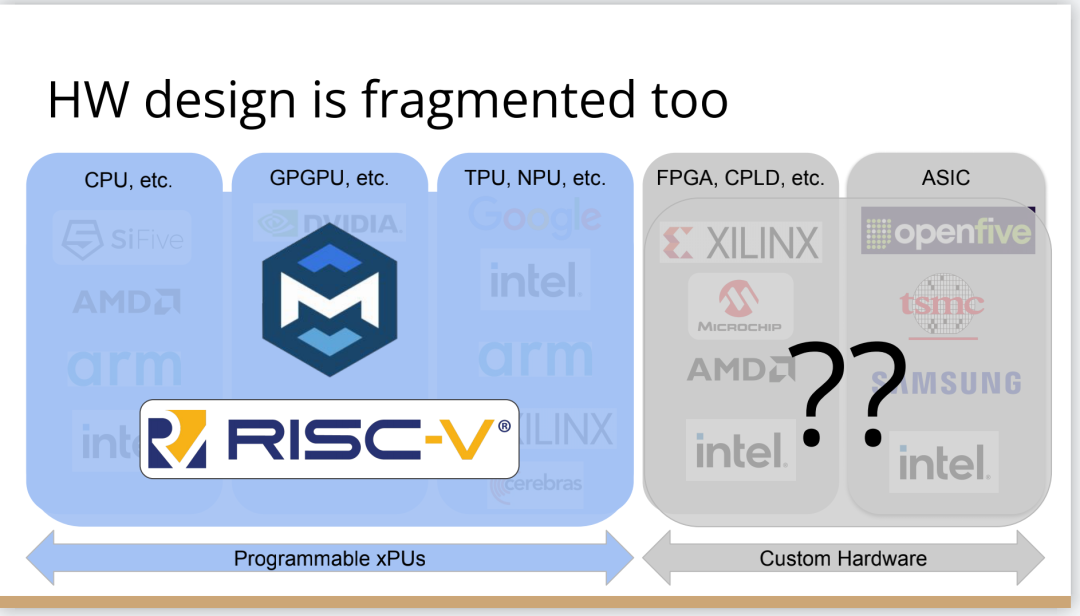
硬體本身呢?上圖右邊留出了一個很大的灰色區域,在這個領域工作的人都是“硬體人員”,在左邊領域工作的人既是硬體也是軟體人員,但右邊確實是一個非常不同硬體世界。
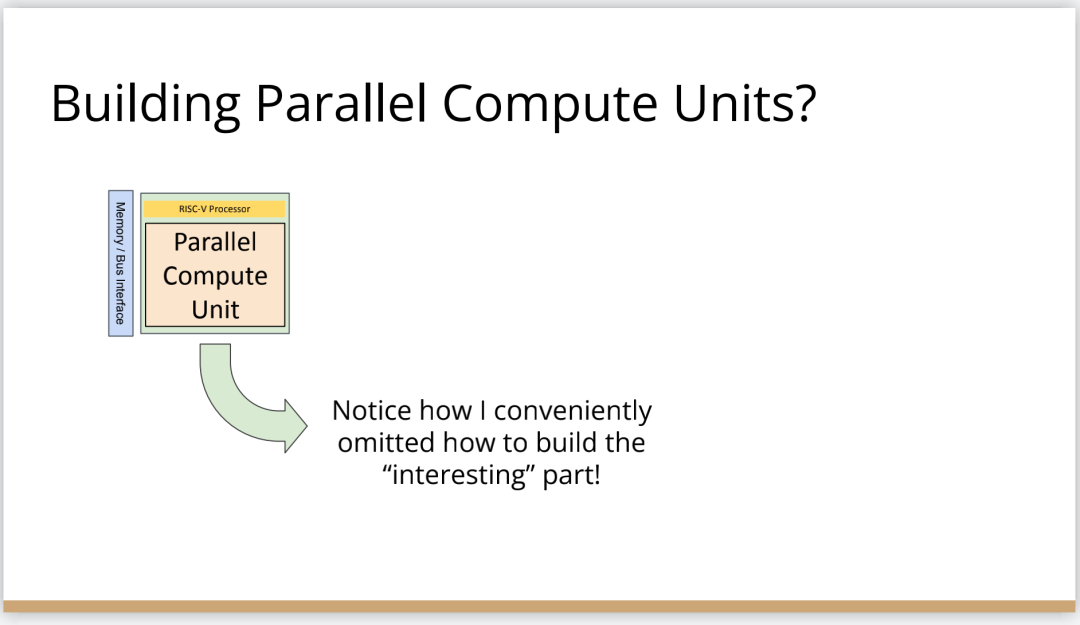
這也是平行計算單元裡的東西。這就是Patterson和Hennessey談到的適用專門領域的架構,以及如何構建這些硬體塊。我們需要演算法創新,需要許多不同技術的創新,這些都需要基於特定領域。
5
編譯器的創新機會
也許你不會感到驚訝,但我認為答案是編譯器,這是真正要走的一條路。

作為編譯器程式語言從業者,我認為硬體設計這個領域已經到了重新評估的地步。整個領域是建立在兩種技術之上,但實際上主要是一種叫做Verilog的技術,你大概率可能不喜歡Verilog。
它有一個非常複雜的標準,當我看它時,不知道它是被設計成一個IR,也即一個不同工具之間的中間表示,還是被設計成讓人們直接書寫的東西。我認為,它在這兩方面都很失敗,它真的很難使用,對工具來說也很難生成。
此外,EDA工具、硬體設計工具已經非常成熟,它們非常標準化,有很多大公司正在推動和開發這些工具。但他們的創新速度並不快,設計時並不注重可用性。它們比加速器編譯器要差得多,絕對不是以軟體架構的最佳實踐來構建的,而且成本也非常高。因此,這個領域有巨大的創新機會。

我不是第一個認識到這一點的人。在開源社群,已經構建了一堆工具推動行業向前發展。這些工具非常棒,比如Verilator被廣泛使用,Yosys是另一個非常棒的工具,它有很好的定理證明器(Theorem Prover)。
我的擔憂在於,這些工具的理想目標是試影象專有工具一樣好,而我並不真的認為專有工具有那麼好。另外,這些工具的設計者並沒有合作。每個工具都在遵循單一僵化的方法,沒有實現大程度的模組化或重複使用,可以從其中一些工具中得到網路列表,用它來解析一些Verilog之類的東西。但是,它不是由基於庫的設計構建,與LLVM之類的東西不一樣。

好訊息是,我看到了這裡正在發生的不同進展的全面爆發,這與我們一直在談論的摩爾定律的失效非常相關。我們看到,研究小組正在推動新硬體設計模型的生產,有Bluespec和Chisel等東西。有許多新的不同研究小組在探索不同的硬體設計方法,而且他們最終往往會生成Verilog,這真的很好,因為現在你可以從軟體和硬體世界引入新的型別系統方法、程式語言思想、編譯器技術。實際上,軟體和硬體有很多想法是互通的。
只是軟、硬體領域用不同的方式說著不同的語言。因此,如果雙方能有更多的交集,這對兩個行業都有益,這種合作令人驚奇,但他們也遇到了困難,這又回到了這個問題上:Verilog實際上不是一個很好的IR。
要建立在語法上正確,並且能表達你想要的東西的Verilog非常困難。此外,因為許多與Verilog有關的工具都有點奇怪,而且很難高質量地預測。生成與工具相容的Verilog是每個前端工具都必須重新發明的一門黑科技。因此,在堆疊中真的缺失了一種元件,這個元件允許人們在程式設計模型水平上進行創新,並允許人們找到方法讓所有工具都接受它。

有一個叫CIRCT的新開源專案正試圖解決這個問題。CIRCT的全稱是"Circuit IR for Compilers and Tools(編譯器和工具的Circuit IR)",它構建在MLIR和LLVM之上。CIRCT社群的目的是提升整個硬體設計世界,促進程式設計模型的創新,並啟用一套新的模組化硬體設計工具。它確實運用了很多我們到目前為止一直在討論的基於庫的技術。
此外,它提供了一個可組合的基於庫的工具鏈,可以建立有趣的新的彈性介面連線,你可以建立Chisel社群正在探索的新程式設計模型,用它來加速Chisel流程。它帶來了很多好處,可以讓很多人一起工作,推動不同方式的創新。我們正在建立一個真正偉大的小世界,讓關心硬體編譯器的人在一起工作,這很有趣。這項工作仍處於早期,目標是更快地構建加速器,讓加速器變得更快。

我們的大目標是,要把硬體設計和驗證過程速度都提高10倍。因此,構建新硬體往往最終需要更多的成本來驗證其正確性,這包括形式化方法,相當於單元測試,有很多不同方式可以證明你正在構建的東西在所有情況下都是正確的。
這種正確性驗證在硬體領域比在軟體領域裡更復雜,因為硬體領域並沒有真正的型別系統,也沒有真正的多層次的IR,所以也就不允許將一個狀態機表示為一個狀態機,並針對它編寫證明。現在,正在發生的事情是整個領域被“去掉了糖分(de-sugared)”,變成了基本上沒有型別的bits,然後所有的分析和工具都在這個層面上工作,我認為,我們可以通過構建和引入編譯器和語言社群中相當知名的技術來迅速提升改善整個領域。
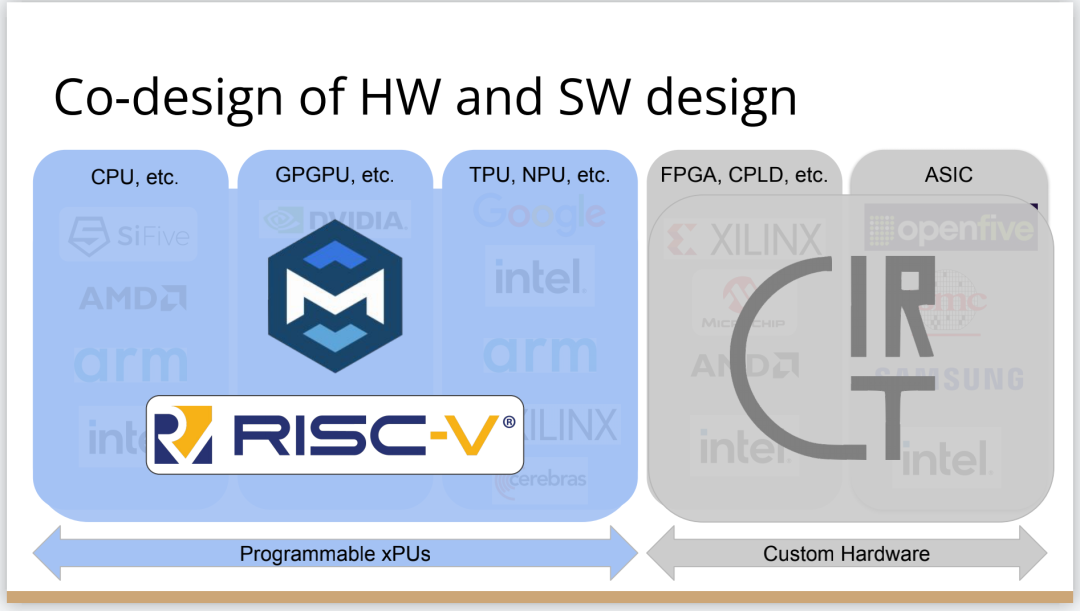
因此,我希望我們將能夠幫助覆蓋整個軟體和硬體領域,組合這些標準的開放工具,包括作為指令集的RISC-V,作為編譯器堆疊的MLIR,以及作為關注硬體的應用的CIRCT。我們正在努力推動整個行業更快發展。
6
總結
最後,我想說現在的確是“編譯器的黃金時代”。我認為,隨著硬體和軟體的協同設計變得更加重要,我們需要比以往更快地推動創新。
編譯器、程式語言以及所有的技術,包括形式化方法和提升線性型別的型別系統,以及其他相當好理解的系統,將會使整個領域受益。我認為形式化、工程化以及這個領域的不同部分的合作,都將推動所有事情發展得更快、更進一步。我很高興看到許多學術界相當知名的方法和技術正在落地。
人們正在試圖弄清楚這一點,他們學習新東西,但也在一些愚蠢的問題上翻跟頭。現在的情況是,我們看到發展速度加快了,看到了新的創新,對舊事物有新研究,因為人們正在回到第一性原則看問題。我非常高興和興奮地看到所發生的這一切。
(本文已獲取編譯授權,視訊連結:http://www.youtube.com/watch?v=4HgShra-KnY)
其他人都在看
歡迎下載體驗OneFlow v0.7.0最新版本:http://github.com/Oneflow-Inc/oneflow/

本文分享自微信公眾號 - OneFlow(OneFlowTechnology)。
如有侵權,請聯絡 [email protected] 刪除。
本文參與“OSC源創計劃”,歡迎正在閱讀的你也加入,一起分享。
- OneFlow原始碼解析:Eager模式下的裝置管理與併發執行
- OpenAI創始人:GPT-4的研究起源和構建心法
- GPT-4創造者:第二次改變AI浪潮的方向
- NCCL原始碼解析①:初始化及ncclUniqueId的產生
- GPT-4問世;LLM訓練指南;純瀏覽器跑Stable Diffusion
- 適配PyTorch FX,OneFlow讓量化感知訓練更簡單
- 超越ChatGPT:大模型的智慧極限
- ChatGPT作者John Schulman:我們成功的祕密武器
- YOLOv5全面解析教程⑤:計算mAP用到的Numpy函式詳解
- GPT-3/ChatGPT復現的經驗教訓
- ChatGPT背後:從0到1,OpenAI的創立之路
- 一塊GPU搞定ChatGPT;ML系統入坑指南;理解GPU底層架構
- YOLOv5全面解析教程④:目標檢測模型精確度評估
- ChatGPT資料集之謎
- OneFlow原始碼解析:Eager模式下的SBP Signature推導
- YOLOv5全面解析教程③:更快更好的邊界框迴歸損失
- ChatGPT背後的經濟賬
- Sam Altman的成功學|升維指南
- 開源機器學習軟體對AI的發展意味著什麼?
- “一鍵”模型遷移,效能翻倍,多語言AltDiffusion推理速度超快