Curve 基於 Raft 的寫時延優化
1 背景
Curve(http://github.com/opencurve/curve )是網易數帆自主設計研發的高效能、易運維、全場景支援的雲原生軟體定義儲存系統,旨滿足Ceph本身架構難以支撐的一些場景的需求,於2020年7月正式開源。當前由CurveBS和CurveFS兩個子專案構成,分別提供分散式塊儲存和分散式檔案儲存兩種能力。其中CurveBS已經成為開源雲原生資料庫PolarDB for PostgreSQL的分散式共享儲存底座,支撐其存算分離架構。
![]()
在CurveBS的設計中,資料伺服器ChunkServer資料一致性採用基於raft的分散式一致性協議去實現的。
典型的基於raft一致性的寫Op實現如下圖所示:
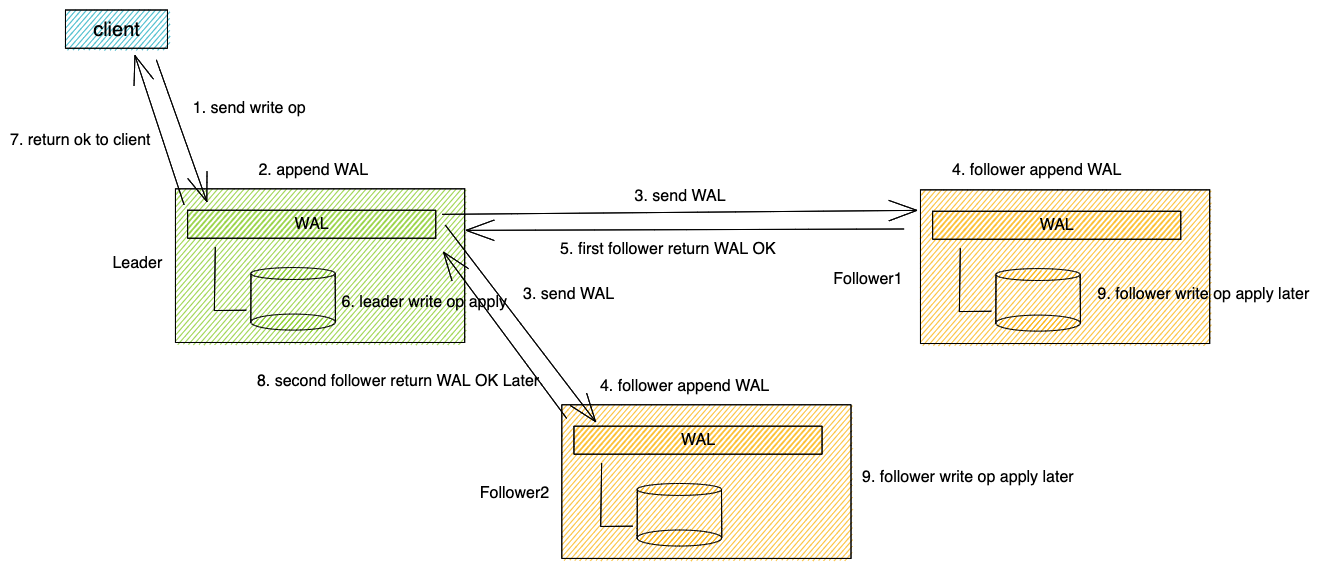
以常見的三副本為例,其大致流程如下:
- 首先client 傳送寫op(步驟1),寫op到達Leader後(如果沒有Leader,先會進行Leader選舉,寫Op總是先發送給Leader),Leader首先會接收寫Op,生成WAL(write ahead log),將WAL持久化到本地儲存引擎(步驟2), 並同時並行將WAL通過日誌傳送rpc傳送給兩個Follower(步驟3)。
- 兩個Follower在收到Leader的日誌請求後,將收到的日誌持久化到本地儲存引擎(步驟4)後,向Leader返回日誌寫入成功(步驟5)。
- 一般來說,Leader日誌總是會先完成落盤,此時再收到其他一個Follower的日誌成功的回覆後,即達成了大多數條件,就開始將寫Op提交到狀態機,並將寫Op寫入本地儲存引擎(步驟6)。
- 完成上述步驟後,即表示寫Op已經完成,可以向client返回寫成功(步驟7)。在稍晚一些時間,兩個Follower也將收到Leader日誌提交的訊息,將寫Op應用到本地儲存引擎(步驟9)。
在目前CurveBS的實現中,寫Op是在raft apply 到本地儲存引擎(datastore)時,使用了基於O_DSYNC開啟的sync寫的方式。實際上,在基於raft已經寫了日誌的情況下,寫Op不需要sync就可以安全的向client端返回,從而降低寫Op的時延,這就是本文所述的寫時延的優化的原理。
其中的程式碼如下,在chunkfile的Open函式中使用了O_DSYNC的標誌。
CSErrorCode CSChunkFile::Open(bool createFile) {
WriteLockGuard writeGuard(rwLock_);
string chunkFilePath = path();
// Create a new file, if the chunk file already exists, no need to create
// The existence of chunk files may be caused by two situations:
// 1. getchunk succeeded, but failed in stat or load metapage last time;
// 2. Two write requests concurrently create new chunk files
if (createFile
&& !lfs_->FileExists(chunkFilePath)
&& metaPage_.sn > 0) {
std::unique_ptr<char[]> buf(new char[pageSize_]);
memset(buf.get(), 0, pageSize_);
metaPage_.version = FORMAT_VERSION_V2;
metaPage_.encode(buf.get());
int rc = chunkFilePool_->GetFile(chunkFilePath, buf.get(), true);
// When creating files concurrently, the previous thread may have been
// created successfully, then -EEXIST will be returned here. At this
// point, you can continue to open the generated file
// But the current operation of the same chunk is serial, this problem
// will not occur
if (rc != 0 && rc != -EEXIST) {
LOG(ERROR) << "Error occured when create file."
<< " filepath = " << chunkFilePath;
return CSErrorCode::InternalError;
}
}
int rc = lfs_->Open(chunkFilePath, O_RDWR|O_NOATIME|O_DSYNC);
if (rc < 0) {
LOG(ERROR) << "Error occured when opening file."
<< " filepath = " << chunkFilePath;
return CSErrorCode::InternalError;
}
...
}
2 問題分析
先前之所以使用O_DSYNC,是考慮到raft的快照場景下,資料如果沒有落盤,一旦開始打快照,日誌也被Truncate掉的場景下,可能會丟資料,目前修改Apply寫不sync首先需要解決這個問題。
首先需要分析清楚Curve ChunkServer端打快照的過程,如下圖所示:

打快照過程的幾個關鍵點:
- 打快照這一過程是進StateMachine與讀寫Op的Apply在StateMachine排隊執行的;
- 快照所包含的last_applied_index在呼叫StateMachine執行儲存快照之前,就已經儲存了,也就是說執行快照的時候一定可以保證儲存的last_applied_index已經被StateMachine執行過Apply了;
- 而如果修改StatusMachine的寫Op Apply去掉O_DSYNC,即不sync,那麼就會存在可能快照在truncate到last_applied_index,寫Op的Apply還沒真正sync到磁碟,這是我們需要解決的問題;
3 解決方案
解決方案有兩個:
3.1 方案一
- 既然打快照需要保證last_applied_index為止apply的寫Op必須Sync過,那麼最簡單的方式,就是在執行打快照時,執行一次Sync。這裡有3種方式,第一是對全盤進行一次FsSync。第二種方式,既然我們的打快照過程需要儲存當前copyset中的所有chunk檔案到快照元資料中,那麼我們天然就有當前快照的所有檔名列表,那麼我們可以在打快照時,對所有檔案進行一次逐一Sync。第三種方式,鑑於一個複製組的chunk數量可能很多,而寫過的chunk數量可能不會很多,那麼可以在datastore執行寫op時,儲存需要sync的chunkid列表,那麼在打快照時,只要sync上述列表中的chunk就可以了。
- 鑑於上述3種sync方式可能比較耗時,而且我們的打快照過程目前在狀態機中是“同步”的執行的,即打快照過程會阻塞IO,那麼可以考慮將打快照過程改為非同步執行,同時這一修改也可減少打快照時對IO抖動的影響。
3.2 方案二
方案二則更為複雜,既然去掉O_DSYNC寫之後,我們目前不能保證last_applied_index為止的寫Op都被Sync了,那麼考慮將ApplyIndex拆分稱為兩個,即last_applied_index和last_synced_index。具體做法如下:
- 將last_applied_index拆分成兩個last_applied_index和last_synced_index,其中last_applied_index意義不變,增加last_synced_index,在執行一次全盤FsSync之後,將last_applied_index賦值給last_synced_index;
- 在前述打快照步驟中,將打快照前儲存last_applied_index到快照元資料變更為last_synced_index,這樣即可保證在打快照時,快照包含的資料一定被sync過了;
- 我們需要一個後臺執行緒定期去執行FsSync,通過定時器,定期執行Sync Task。執行過程可能是這樣的: 首先後臺sync執行緒遍歷所有的狀態機,拿到當前的所有last_applied_index,執行FsSync,然後將上述last_applied_index賦值給對於狀態機的last_synced_index;
3.3 兩種方案的優缺點:
- 方案一改動較為簡單,只需要改動Curve程式碼,不需要動braft的程式碼,對braft框架是非侵入式的;方案二則較為複雜,需要改動braft程式碼;
- 從快照執行效能來看,方案一會使得原有快照變慢,由於原有快照時同步的,因此最好在這次修改中改成非同步執行快照;當然方案二也可以優化原有快照為非同步,從而減少對IO的影響;
3.4 採取的方案:
- 採用方案一實現方式,原因是對braft的非侵入式修改,對於程式碼的穩定性和對後續的相容性都有好處。
- 至於對chunk的sync方式,採用方案一的第3種方式,即在datastore執行寫op時,儲存需要sync的chunkid列表,同時在打快照時,sync上述列表中的chunkid,從而保證chunk全部落盤。這一做法避免頻繁的FsSync對全部所有chunkserver的造成IO的影響。此外,在執行上述sync時,採用批量sync的方式,並對sync的chunkid進行去重,進而減少實際sync的次數,從而減少對前臺IO造成的影響。
4 POC
以下進行poc測試,測試在直接去掉O_DSYNC情況下,針對各種場景對IOPS,時延等是否有優化,每組測試至少測試兩次,取其中一組。
測試所用fio測試引數如下:
- 4K隨機寫測試單卷IOPS:
[global]
rw=randwrite
direct=1
iodepth=128
ioengine=libaio
bsrange=4k-4k
runtime=300
group_reporting
size=100G
[disk01]
filename=/dev/nbd0
- 512K順序寫測單卷頻寬:
[global]
rw=write
direct=1
iodepth=128
ioengine=libaio
bsrange=512k-512k
runtime=300
group_reporting
size=100G
[disk01]
filename=/dev/nbd0
- 4K單深度隨機寫測試時延:
[global]
rw=randwrite
direct=1
iodepth=1
ioengine=libaio
bsrange=4k-4k
runtime=300
group_reporting
size=100G
[disk01]
filename=/dev/nbd0
叢集配置:
| 機器 | roles | disk |
|---|---|---|
| server1 | client,mds,chunkserver | ssd/hdd * 18 |
| server2 | mds,chunkserver | ssd/hdd * 18 |
| server3 | mds,chunkserver | ssd/hdd * 18 |
4.1 HDD對比測試結果
| 場景 | 優化前 | 優化後 |
|---|---|---|
| 單卷4K 隨機寫 | IOPS=5928, BW=23.2MiB/s, lat=21587.15usec | IOPS=6253, BW=24.4MiB/s, lat=20465.94usec |
| 單卷512K順序寫 | IOPS=550, BW=275MiB/s,lat=232.30msec | IOPS=472, BW=236MiB/s,lat=271.14msec |
| 單卷4K單深度隨機寫 | IOPS=928, BW=3713KiB/s, lat=1074.32usec | IOPS=936, BW=3745KiB/s, lat=1065.45usec |
上述測試在RAID卡cache策略writeback下效能有略微提高,但是提升效果並不明顯,512K順序寫場景下甚至略有下降,並且還發現在去掉O_DSYNC後存在IO劇烈抖動的現象。
我們懷疑由於RAID卡快取的關係,使得效能提升不太明顯,因此,我們又將RAID卡cache策略設定為writethough模式,繼續進行測試:
| 場景 | 優化前 | 優化後 |
|---|---|---|
| 單卷4K隨機寫 | IOPS=993, BW=3974KiB/s,lat=128827.93usec | IOPS=1202, BW=4811KiB/s, lat=106426.74usec |
| 單卷單深度4K隨機寫 | IOPS=21, BW=85.8KiB/s,lat=46.63msec | IOPS=38, BW=154KiB/s,lat=26021.48usec |
在RAID卡cache策略writethough模式下,效能提升較為明顯,單卷4K隨機寫大約有20%左右的提升。
4.2 SSD對比測試結果
SSD的測試在RAID直通模式(JBOD)下測試,效能對比如下:
| 場景 | 優化前 | 優化後 |
|---|---|---|
| 單卷4k隨機寫 | bw=83571KB/s, iops=20892,lat=6124.95usec | bw=178920KB/s, iops=44729,lat=2860.37usec |
| 單卷512k順序寫 | bw=140847KB/s, iops=275,lat=465.08msec | bw=193975KB/s, iops=378,lat=337.72msec |
| 單卷單深度4k隨機寫 | bw=3247.3KB/s, iops=811,lat=1228.62usec | bw=4308.8KB/s, iops=1077,lat=925.48usec |
可以看到在上述場景下,測試效果有較大提升,4K隨機寫場景下IOPS幾乎提升了100%,512K順序寫也有較大提升,時延也有較大降低。
5 總結
上述優化適用於Curve塊儲存,基於RAFT分散式一致性協議,可以減少RAFT狀態機應用到本地儲存引擎的一次立即落盤,從而減少Curve塊儲存的寫時延,提高Curve塊儲存的寫效能。在SSD場景下測試,效能有較大提升。對於HDD場景,由於通常啟用了RAID卡快取的存在,效果並不明顯,因此我們提供了開關,在HDD場景可以選擇不啟用該優化。
本文作者:許超傑,網易數帆資深系統開發工程師
- Curve技術合集:http://zhuanlan.zhihu.com/p/311590077
- Curve主頁:http://www.opencurve.io/
- Curve原始碼:http://github.com/opencurve/curve
- 掃碼加入Curve交流群:

- Curve 替換 Ceph 在網易雲音樂的實踐
- 雲原生行業應用崛起,從“可用”到“好用”有多遠?
- 雲原生時代,中介軟體應該如何“進化”?
- Curve 進入 CNCF Sandbox,完善統一雲原生開源儲存拼圖
- 網易數帆 Envoy Gateway 實踐之旅:堅守 6 年,崢嶸漸顯
- 網易數帆對 Istio 推送的效能優化經驗分享 | IstioCon 2022
- IstioCon 回顧 | 網易數帆的 Istio 推送效能優化經驗
- 有數BI大規模報告穩定性保障實踐
- 資料標準在網易的實踐
- 馴服 Kubernetes!網易數帆雲原生運維體系建設之路
- Curve 基於 Raft 的寫時延優化
- 您的聲音我們關心 | 網易數帆有數產品Q1季報
- Slime 2022 展望:把 Istio 的複雜性塞入智慧的黑盒
- 網易數帆王佰平:我的 Envoy Maintainer 之路
- 首屆 DIVE 精彩回顧丨踐行企業數字化,基礎軟體如何創新
- 首屆 DIVE 精彩回顧丨踐行企業數字化,基礎軟體如何創新
- 為什麼你應該瞭解 Loggie
- 網易數帆資料生產力技術體系
- 汪源做客阿里雲大咖說,論道 PolarDB 資料庫開源與儲存生態
- 網易數帆資料生產力方法論