OPPO 自研大規模知識圖譜及其在數智工程中的應用
導讀:OPPO 知識圖譜是 OPPO 數智工程系統小布助手團隊主導、多團隊協作建設的自研大規模通用知識圖譜,目前已達到數億實體和數十億三元組的規模,主要落地在小布助手知識問答、電商搜尋等場景。
本文主要分享 OPPO 知識圖譜建設過程中演算法相關的技術挑戰和對應的解決方案,主要包括實體分類、實體對齊、資訊抽取、實體連結和圖譜問答 query 解析等相關演算法內容。
全文圍繞下面四點展開:
- 背景
- OPPO 知識圖譜
- 知識圖譜在小布助手中的應用
- 總結與展望
背景
首先和大家分享下小布助手和知識圖譜的背景。
背景——小布助手
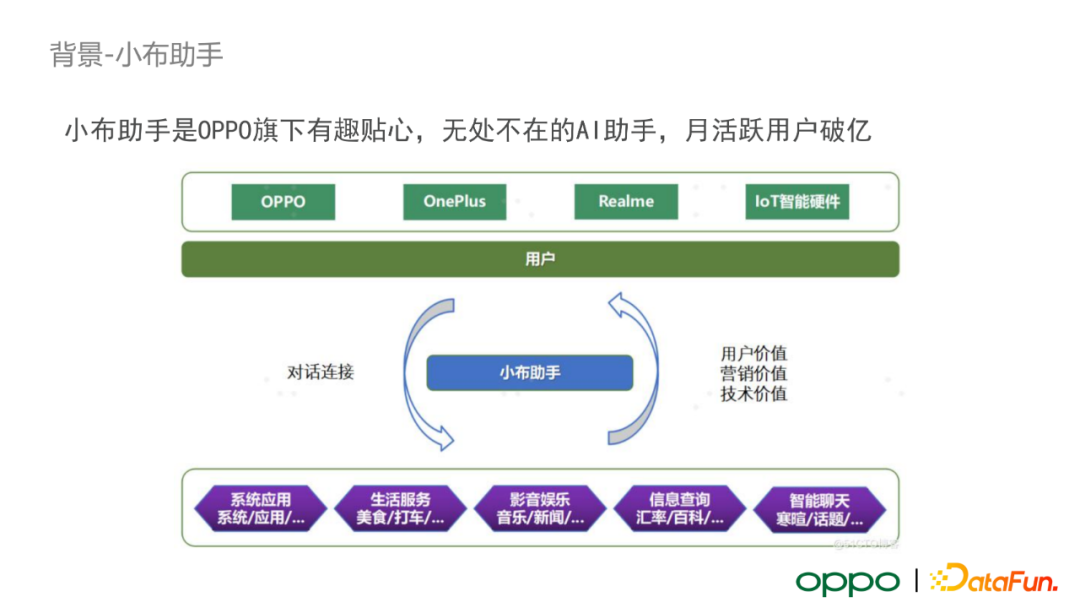
小布助手是 OPPO 旗下有趣貼心、無處不在的 AI 助手,搭載在 OPPO 手機、OnePlus、Realme 以及如智慧手錶等 IoT 智慧硬體上。它可以為使用者提供系統應用、生活服務、影音娛樂、資訊查詢、智慧聊天等服務,進而挖掘潛在的使用者價值、營銷價值和技術價值。
背景——OPPO 知識圖譜

在 2020 年年底,OPPO 開始著手構建自己的知識圖譜。經過一年左右的時間,OPPO 已經構建了數億實體和數十億關係的高質量通用知識圖譜。目前,OPPO 知識圖譜支援了每天線上數百萬次的小布問答請求。進一步,OPPO 正將通用知識圖譜逐漸擴充套件到商品圖譜、健康圖譜、風控圖譜等多個垂類。
OPPO 知識圖譜
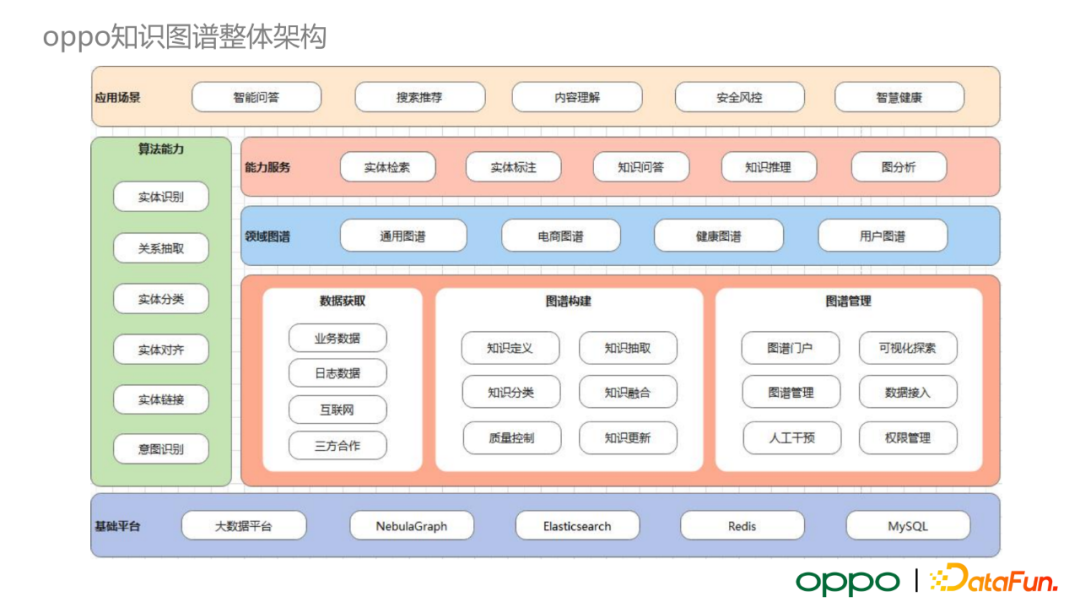
接下來為大家介紹 OPPO 知識圖譜的整體架構。如上圖所示,它由三大部分組成。最底層是通用的資料處理平臺和圖資料庫相關框架。我們具體選取 Nebula Graph 來儲存圖資料。中間層包含資料獲取、圖譜構建和圖譜管理模組。最頂層涵蓋了 OPPO 圖譜各種應用場景,包括智慧問答、搜尋推薦、內容理解、安全風控、智慧健康等。
下面介紹應用知識圖譜的三個核心演算法:實體分類、實體對齊和資訊抽取。
知識圖譜演算法——實體分類
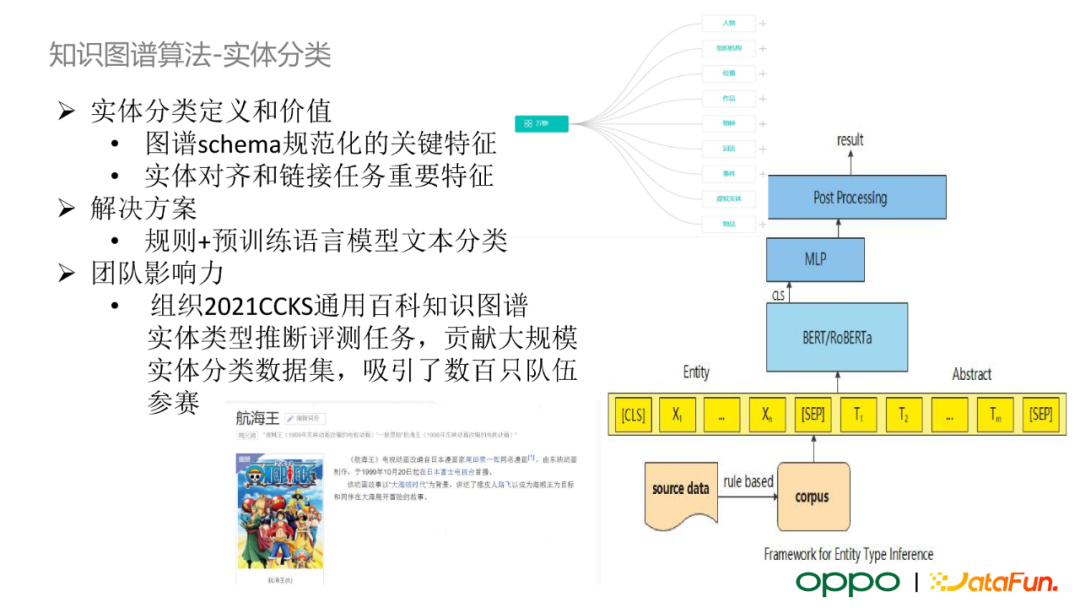
實體分類根據圖譜預定義的 schema 對實體進行歸類,進而可以使我們對實體進行屬性、關係的關聯。同時,實體分類可以對下游的實體對齊、實體連結和線上的智慧問答業務等提供重要的特徵。目前,我們採用規則+預訓練語言模型文字分類的 pipeline 方案。在第一階段,我們利用如百科中對實體的描述,使用預定義的規則處理大量半監督的偽標籤資料。隨後,這些資料會交給標註同事進行校驗,整理出有標籤的訓練集,結合預訓練語言模型訓練一個多標籤的文字分類模型。值得一提的是,我們為業界提供了一個大規模實體分類資料集,組織了 2021 CCKS 通用百科知識圖譜競賽,吸引了數百隻隊伍參賽。
知識圖譜演算法——實體對齊
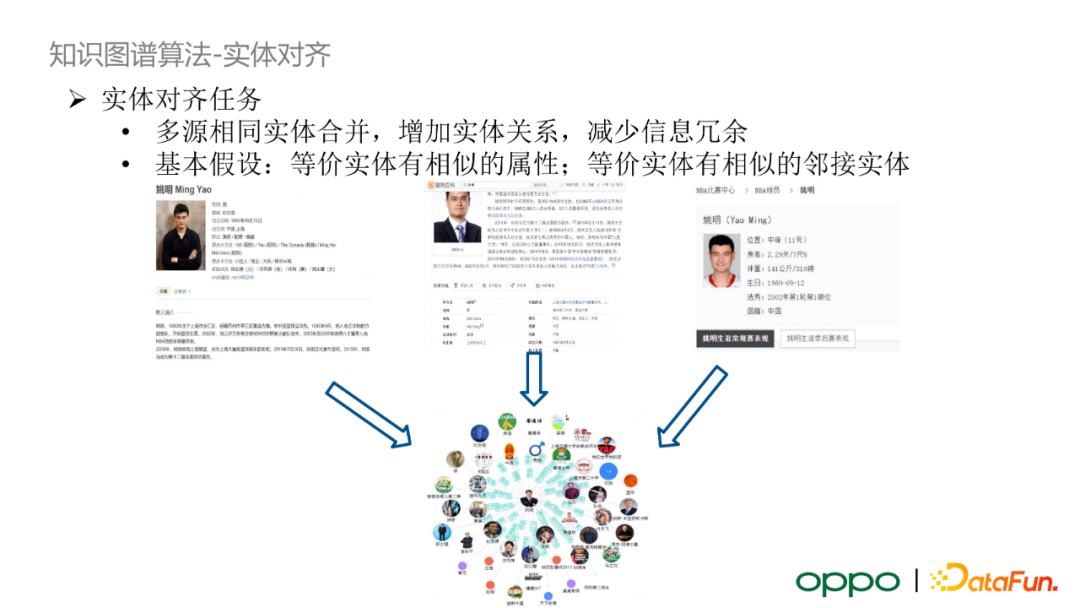
實體對齊任務是知識圖譜構建中比較關鍵的環節。在網際網路的開源資料中,同一實體在多個來源下存在相似或者相同的資訊,若將這部分冗餘資訊全部包含在知識圖譜中,那麼在下游使用知識圖譜進行資訊檢索時會帶來歧義。所以,我們對多源相同的實體進行資訊整合,減少資訊冗餘。
知識圖譜演算法——實體對齊演算法
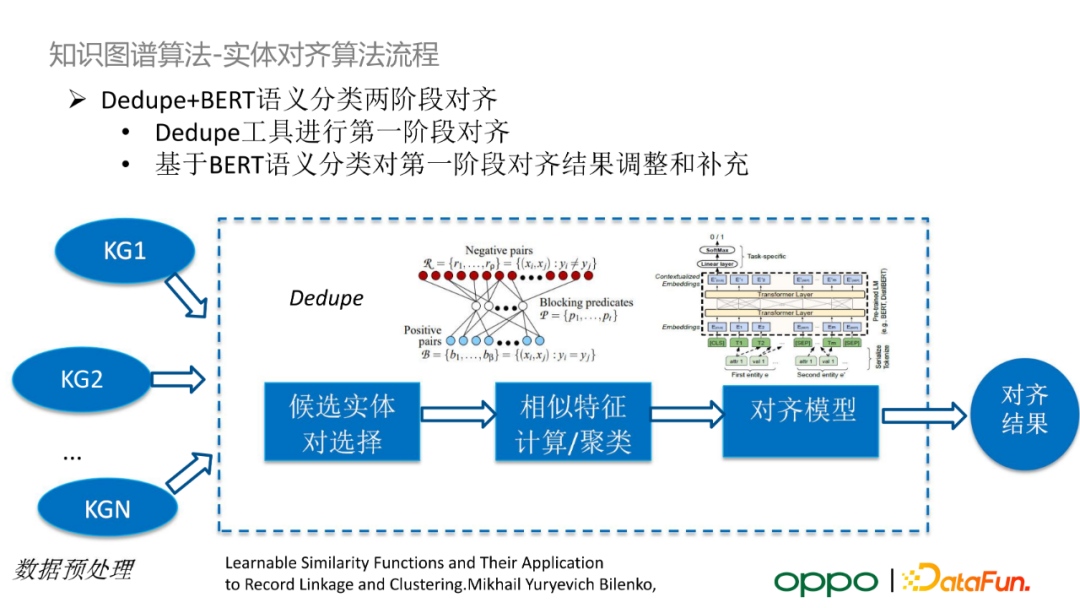 具體地,由於知識圖譜中的實體規模達到了上億的量級,考慮到效率問題,我們提出了 Dedupe+BERT 語義分類的兩階段方案。在第一階段,我們採用並行處理的方式將名字、別名相同的實體進行分組,輸入 Dedupe 資料去重工具,生成第一階段實體對齊結果。我們要求這一階段的結果的準確率很高。在第二階段,我們會訓練一個實體相關性匹配模型,其輸入是一對候選實體,旨在調整、補充第一階段的對齊結果。
具體地,由於知識圖譜中的實體規模達到了上億的量級,考慮到效率問題,我們提出了 Dedupe+BERT 語義分類的兩階段方案。在第一階段,我們採用並行處理的方式將名字、別名相同的實體進行分組,輸入 Dedupe 資料去重工具,生成第一階段實體對齊結果。我們要求這一階段的結果的準確率很高。在第二階段,我們會訓練一個實體相關性匹配模型,其輸入是一對候選實體,旨在調整、補充第一階段的對齊結果。
知識圖譜演算法——資訊抽取
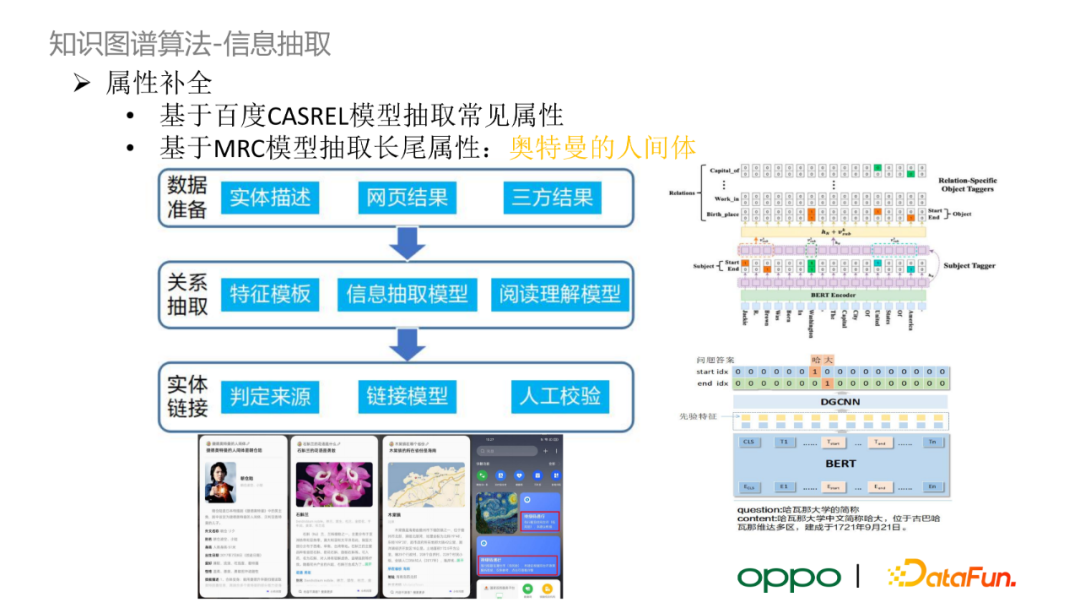
在實體分類與對齊後,由於資料來源存在資訊缺失,圖譜中存在一些實體缺失部分關鍵屬性。我們將缺失屬性的實體分成兩類,使用資訊抽取的方法對它們進行屬性補全。
第一類是常見的實體與屬性,如國家的首都、人物的年齡和性別等。我們使用百度 CASREL 模型以及業界常用的開源資料集訓練一個關係抽取模型。模型的結構可以看作一個多標籤的指標網路,每個標籤對應一個關係型別。CASREL 首先抽取句子中的主實體,再將主實體的 embedding 輸入指標網路,預測每一個關係下句子中的客體起始位置和終止位置,最後通過設定的閾值來判定 SPO 三元組是否可信。
第二類是長尾屬性,它們在開源資料集上標註較少。我們利用閱讀理解(MRC)模型抽取長尾屬性。如我們想要抽取“某奧特曼的人間體”這一屬性,我們就將“某奧特曼的人間體是誰”這一問題作為 query,檢索文字結果,使用閱讀理解模型判斷文字中是否包含“人間體”的客體。
總結來說,在構建知識圖譜的過程中,我們應用了實體分類、實體對齊與資訊抽取任務,希望通過它們來提升知識圖譜的質量和豐富程度。後續建設過程中,我們希望在現有的框架下將實體分類基於遷移學習擴充套件到商品分類、遊戲分類等垂域場景。此外,目前的實體對齊任務還較為基礎,我們希望在未來結合多模態、節點表示學習等多策略對齊方案。最後,對於資訊抽取任務,我們希望藉助大規模預訓練語言模型,基於少量標記樣本,甚至零標記樣本,來抽取實體關係。我們還考慮應用實體抽取演算法,使得它可以落地於小布助手的業務場景中。
知識圖譜在小布助手中的應用
第三部分重點介紹知識圖譜在小布助手業務場景中的應用。
知識圖譜的應用
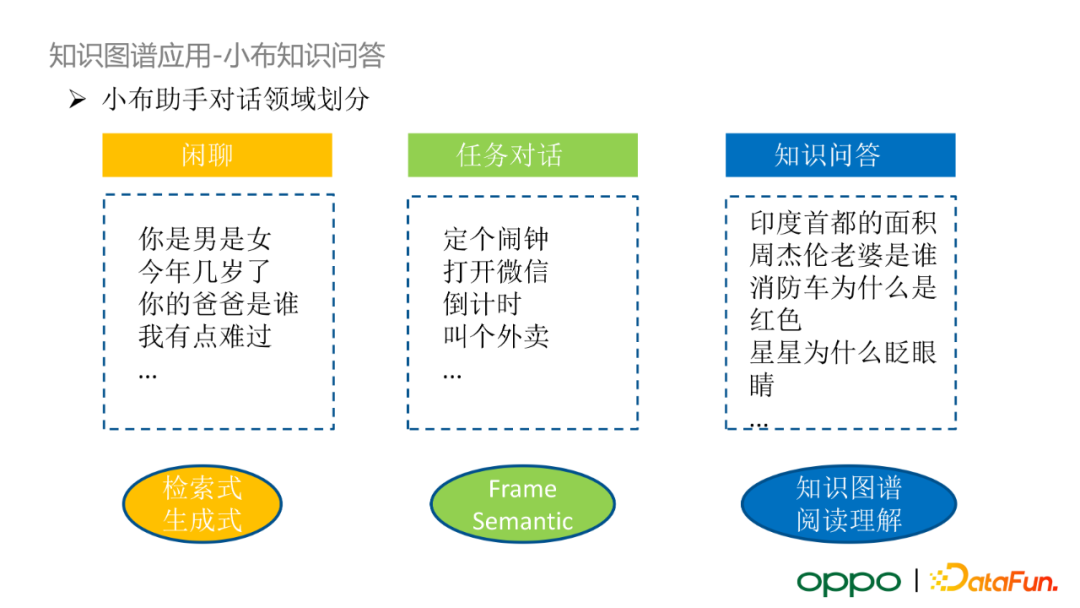
小布助手按照對話領域可以劃分為三大類:閒聊、任務對話和知識問答。其中,閒聊類使用檢索式、生成式演算法;任務對話利用幀語義的演算法對 query 進行結構化解析;知識問答進一步細分為兩部分,基於知識圖譜的 KBQA 的結構化問答和基於閱讀理解與向量檢索的非結構化問答。
知識圖譜應用——知識問答分類
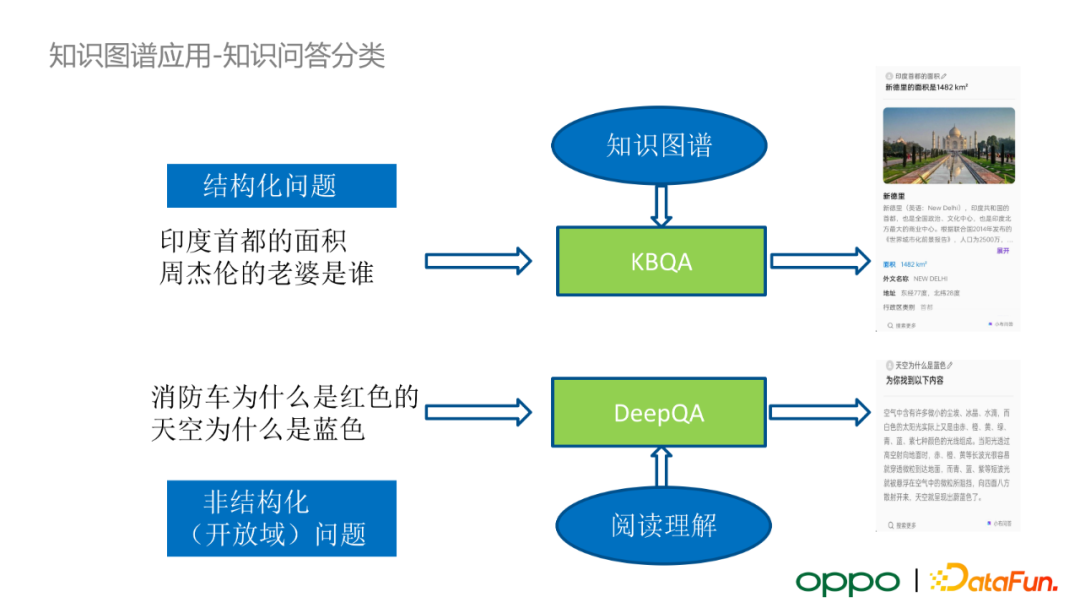
首先介紹知識問答。對於結構化問題,我們採用 KBQA 來解決;對於非結構化問題,我們採用 DeepQA+ 閱讀理解的框架來處理。
知識圖譜應用——結構化分類
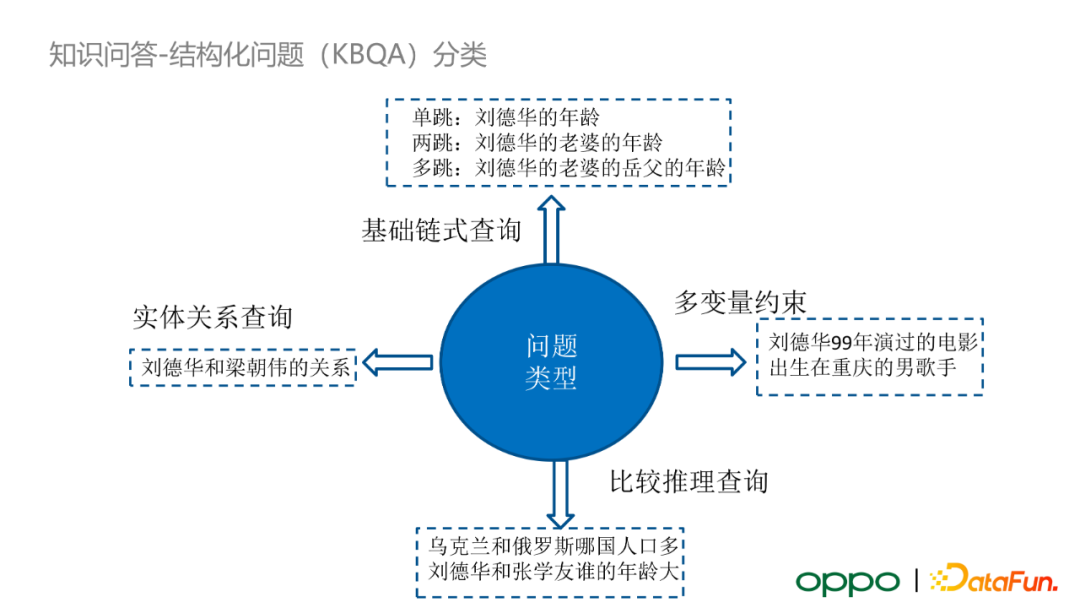 對於結構化問題,在小布助手的應用中有四大類 query:
對於結構化問題,在小布助手的應用中有四大類 query:
- 基礎鏈式查詢,如單跳、兩跳、甚至更多跳的問題
- 多變數約束查詢
- 實體關係查詢
- 比較推理查詢
知識圖譜應用——KBQA 整體演算法架構
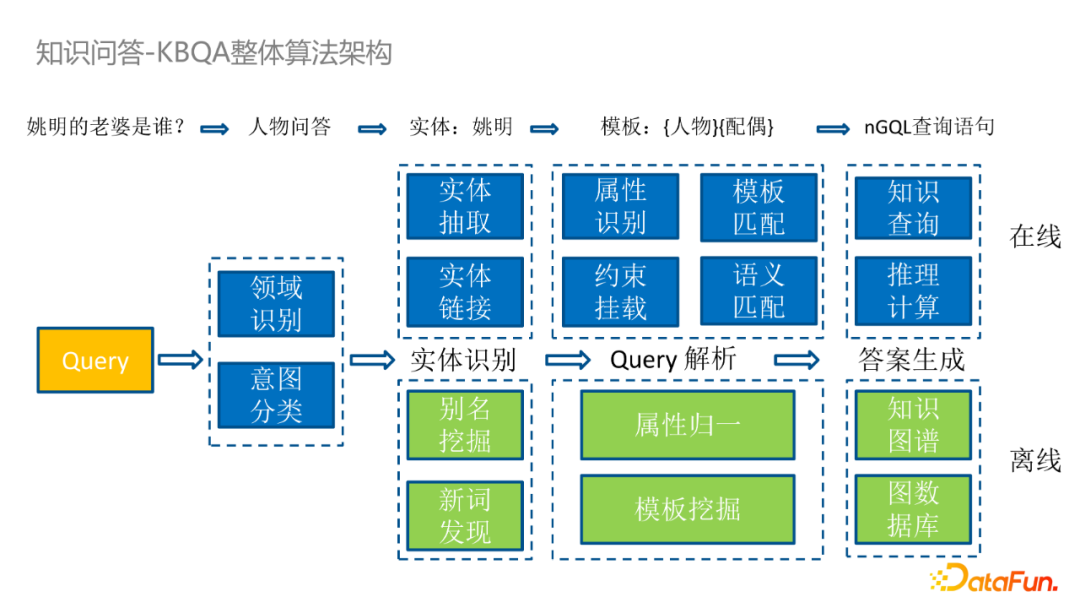
我們針對結構化問題設計了一套基於 KBQA 的演算法框架。首先,在接收到線上使用者的 query 輸入後,我們會先對其進行領域識別以及意圖分類。若 query 是可以使用 KBQA 解決,那麼我們會對 query 進行實體識別、query 解析和答案生成。這三個主要步驟又可以通過線上和離線兩方面進行進一步歸類。比如,離線 KBQA 會進行別名挖掘、新詞發現、屬性歸一、模板挖掘,最終更新知識圖譜和圖資料庫。線上 KBQA 會進行實體抽取、實體連結、屬性識別、約束掛載、模板匹配和長尾模板的語義匹配,最後在圖資料中進行知識查詢或者根據查詢結果進行推理計算。
知識問答——實體抽取
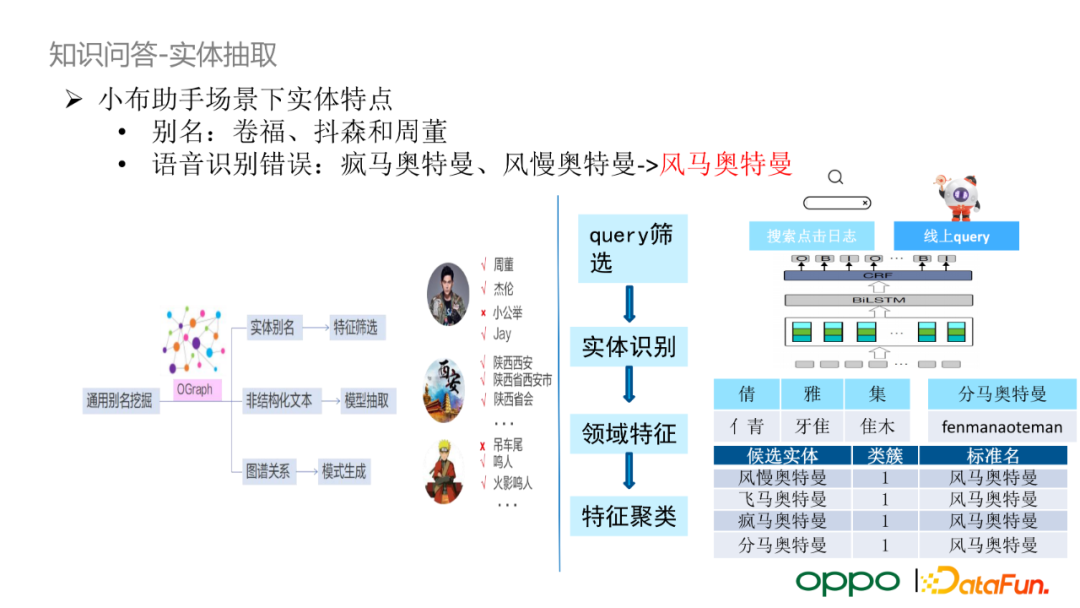
小布助手的輸入以語音為主,所以小布助手場景下實體往往存在別名以及語音識別錯誤的特點。在語音輸入時,使用者往往不會說出人物的完整名字,而是採用別名。其次,語音識別的錯誤率相對較高,導致輸入相較於網頁上的 query 輸入差異較大。針對別名問題,最基礎的解決方案是基於知識圖譜的實體別名建設一個對映詞表;其次,針對複合實體,我們會利用圖譜中的上位詞挖掘實體複合詞。針對語音識別錯誤問題,我們會採用內部大量搜尋點選日誌,利用點選網頁中 title 包含的標準名和對應的 query 做匹配。匹配時的輸入特徵有兩類:偏旁部首的特徵(倩雅集和晴雅集)以及拼音特徵(分馬奧特曼和風馬奧特曼)。我們將候選標準名的特徵和 query 的特徵進行聚類,最終選取距離最近的標準名。值得一提的是,在生成實體對映詞表前,我們還會進行額外的人工校驗。
知識問答——實體連結
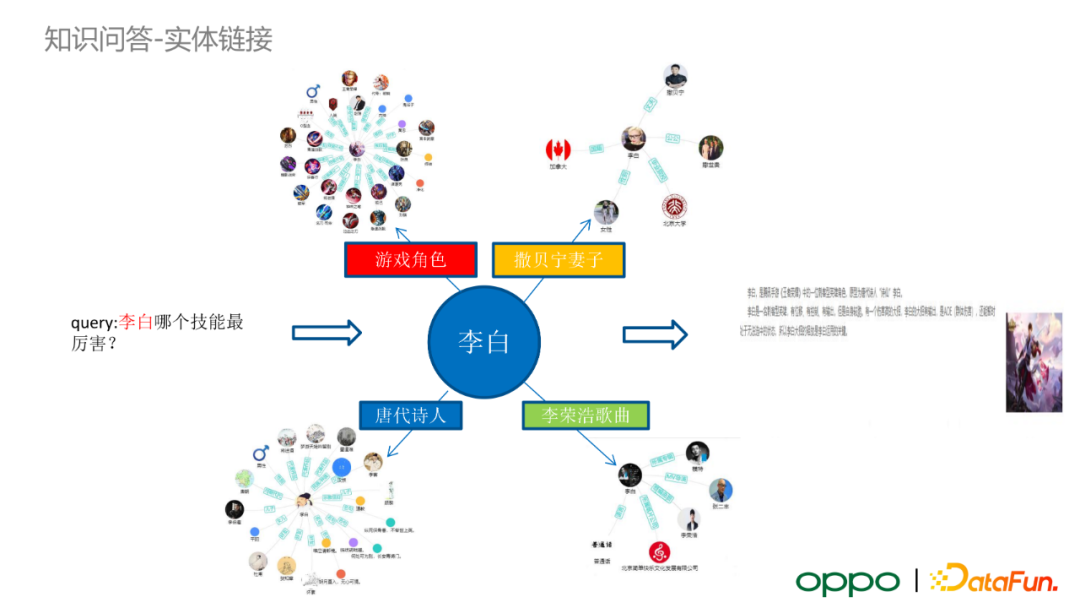
在對使用者 query 進行實體識別之後,我們需要進行實體連結任務。以“李白哪個技能最厲害?”這個 query 為例。“李白”這一實體會在知識圖譜中對應著多個不同型別的實體,如遊戲角色、唐代詩人、李榮浩歌曲、撒貝南妻子等。此時,我們需要結合 query 的語義來選取真正的實體。
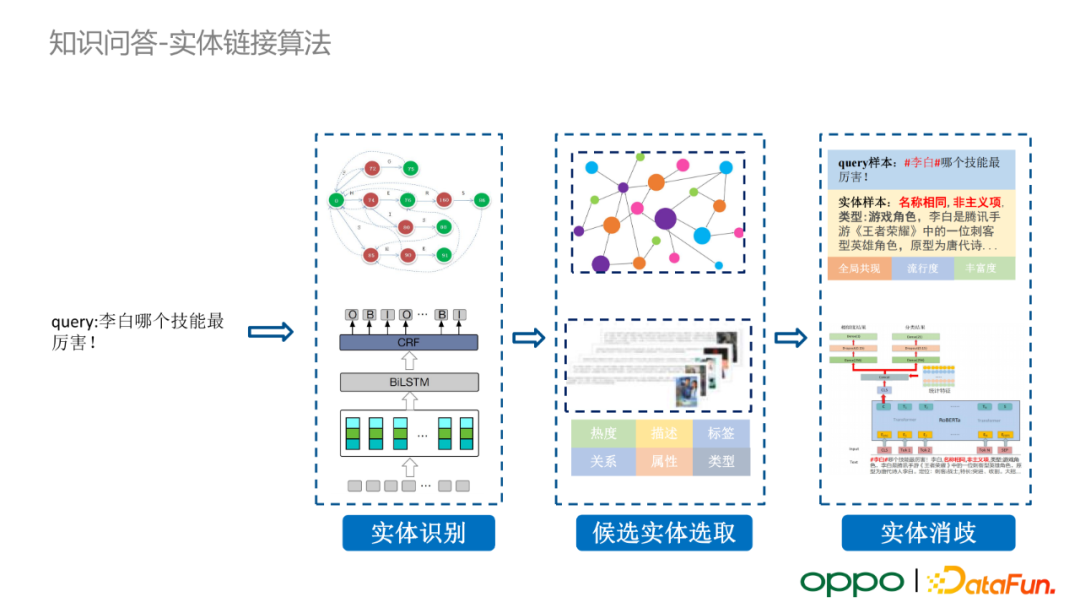 實體連結會經歷三個步驟。首先,我們採用 BiLSTM+CRF 進行實體識別;之後,我們會在知識圖譜中召回候選實體;最後,我們基於實體消歧模型,對 query 和候選實體的匹配度進行打分,選擇最匹配的實體。若所有候選實體的匹配度均低於預設的閾值,我們則會輸出一個特殊的空類別。
實體連結會經歷三個步驟。首先,我們採用 BiLSTM+CRF 進行實體識別;之後,我們會在知識圖譜中召回候選實體;最後,我們基於實體消歧模型,對 query 和候選實體的匹配度進行打分,選擇最匹配的實體。若所有候選實體的匹配度均低於預設的閾值,我們則會輸出一個特殊的空類別。
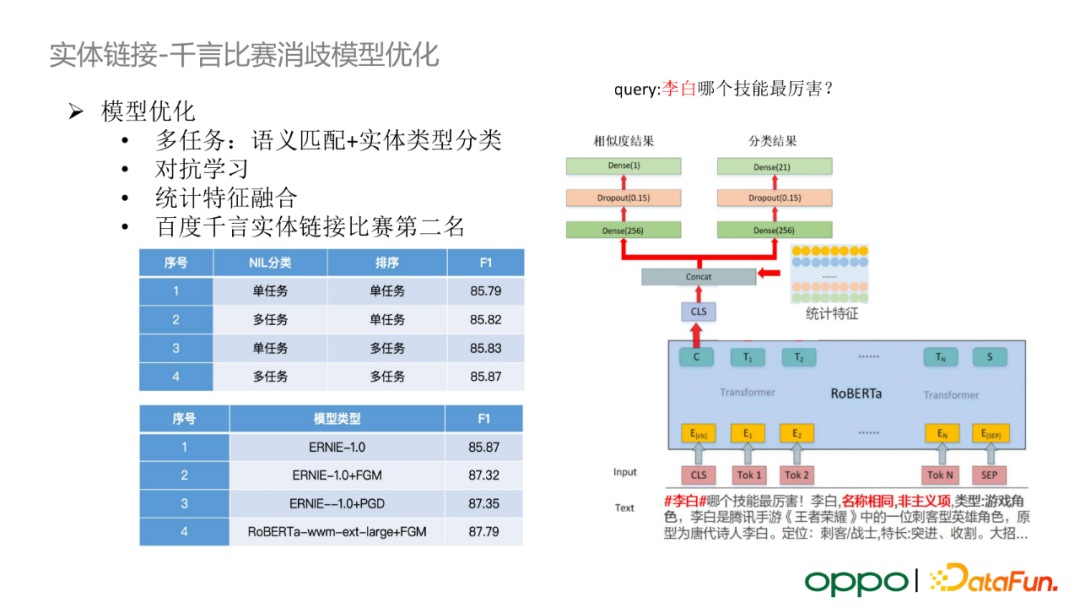
上圖呈現的方案是我們團隊在參加百度千言實體連結比賽中提出的。它採用了多工訓練框架(語義匹配+實體型別分類),引入了對抗學習策略,融入了統計類特徵(如實體的熱度、實體的豐富度等),並加入了多模型整合的方法。最終我們在千言實體連結比賽中斬獲第二名。具體地,我們將 query 與實體的相似度匹配任務建模為一個二分類任務,將實體型別分類任務建模為一個多分類任務。經過對比實驗,我們證明了多工學習、對抗學習的思路對實體消歧模型的效果有一定提升。需要指出的是,在實體連結模型真正上線使用的時候,我們會選取一個相對較小規模的模型。
知識問答——Query 解析演算法
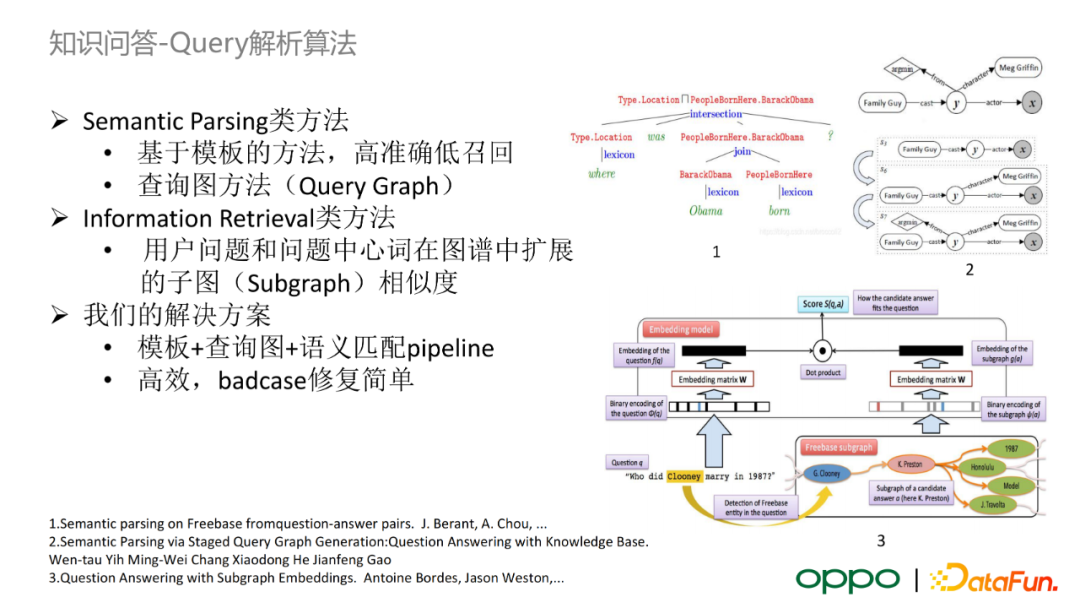 對 query 進行實體連結後,我們需要對 query 基於模板進行屬性抽取。業界主要有兩種方案:基於語義解析(semantic parsing)類的方法和基於資訊檢索(information retrieval)類的方法。OPPO 主要選取語義解析類的方案,並且在解析失敗的長尾屬性採用語義匹配的方法進行兜底。
對 query 進行實體連結後,我們需要對 query 基於模板進行屬性抽取。業界主要有兩種方案:基於語義解析(semantic parsing)類的方法和基於資訊檢索(information retrieval)類的方法。OPPO 主要選取語義解析類的方案,並且在解析失敗的長尾屬性採用語義匹配的方法進行兜底。
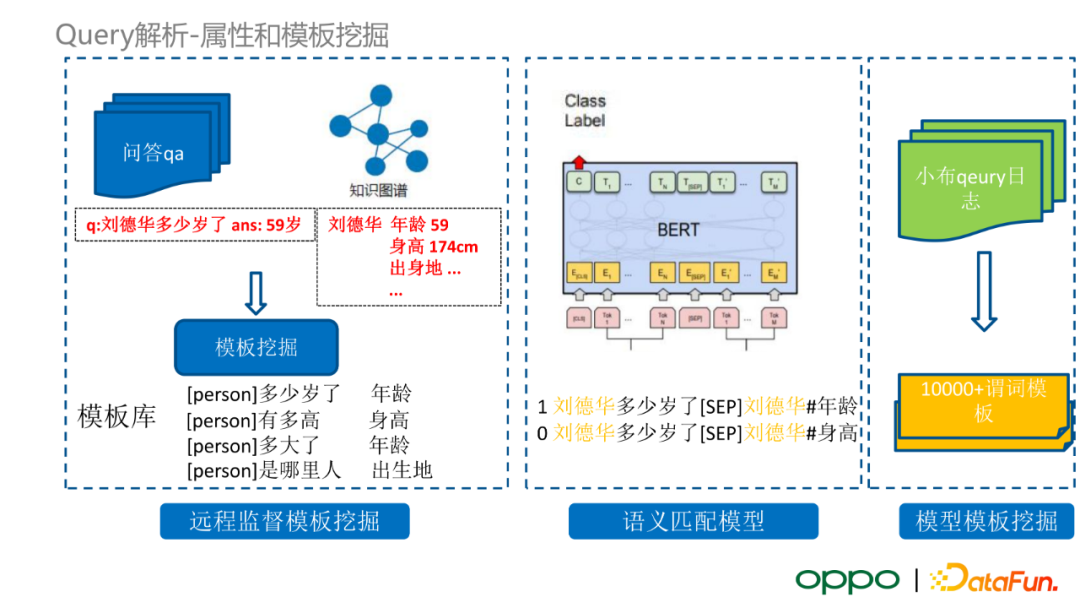
在語義解析類的方案中,首先我們需要挖掘用於語義解析的常見模板。我們採用遠端監督模板挖掘的方式,利用網際網路海量的問答資料,將這些語料與我們的知識圖譜進行匹配,得到問答庫中實體的屬性,最後得到問答語料中常見的 query 模板。例如,“q:劉德華多少歲了 ans:59歲”這個問答,經過圖譜屬性檢索,得到 query 實際上在詢問某個人的年齡屬性。類似的,我們可以得到詢問某個人的身高屬性、年齡屬性、出生地屬性的 query,據此生成一系列 query 模板。基於挖掘的模板,我們可以訓練一個語義匹配分類模型,其輸入是原始 query 和一個候選query 屬性。此外,在訓練過程中,我們會將實體 mask 掉,旨在使模型學習 query 在實體資訊之外的語義與實體屬性的相關性。在模型訓練完畢後,我們使用小布線上 query 日誌,先對它們進行實體抽取,然後將 query 以及圖譜中 query 實體所對應的所有候選屬性輸入模型,進行語義匹配的預測任務,得到一部分較高置信度的候選模板。輸出模板會交由標註人員進行校驗,最終得到的模板會加入 query 解析的演算法模組中。
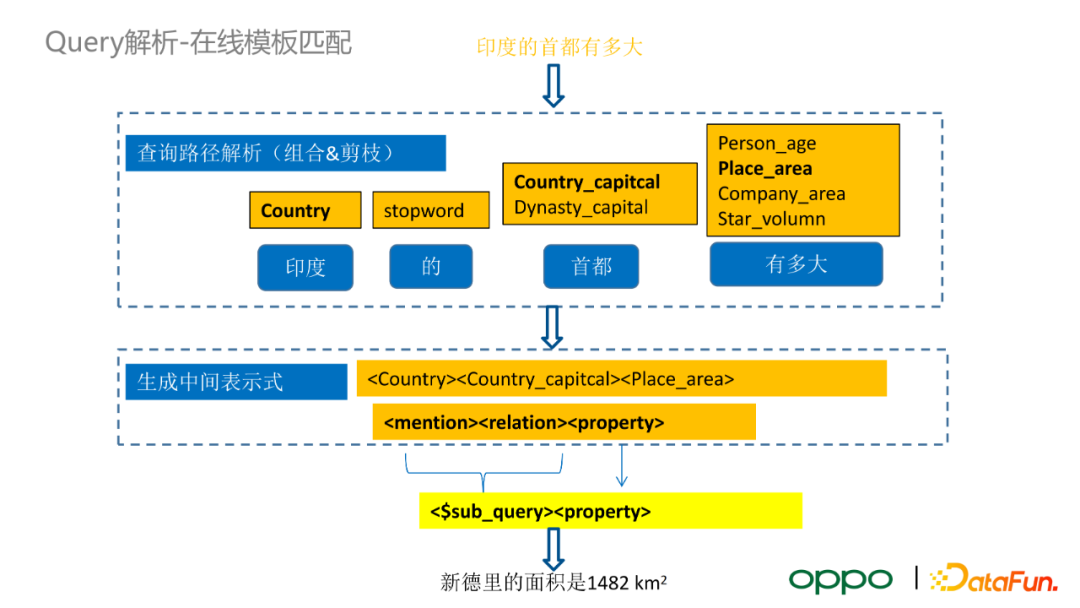
接下來以一個具體的例子來解釋我們如何使用模板來解析線上的 KBQA 問題。比如使用者輸入 query 為“印度的首都有多大”,即使用者的真實意圖是詢問新德里的面積。首先,我們會對 query 做實體識別,將“印度”對映至圖譜中的“國家”,利用模板將“首都”對映至“國家的首都”或者“王朝的首都”,同理將“有多大”歸一化至“人的年齡”、“地區的面積”、“公司的面積”、“行星的體積”等屬性。此時還不能完全確定對應的屬性,所以我們會將所有的候選屬性進行排列組合,結合剪枝的方法,選擇最有可能的模板,生成中間表示式。在上面的例子中,最佳模板是“國家首都的面積”。這個 query 實際上是個兩跳的問題,我們會利用單條模板將其中一部分抽象為一個子查詢,如“國家的首都”。具體地,我們會將子查詢與剩餘的查詢模板拼接在一起,生成一個複合查詢。在執行知識圖譜的查詢的時候,我們會首先執行子查詢,並將其替換為查詢得到的實體,最後按照生成的 query 繼續在圖譜中搜索最終的結果。
知識問答——模版語義匹配
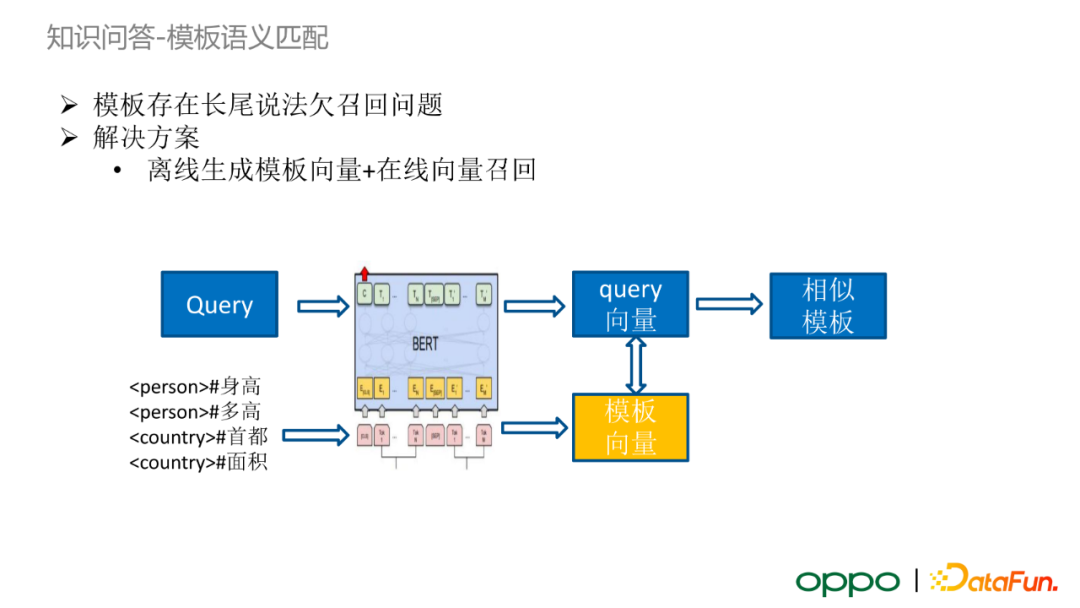
雖然我們離線挖掘了大量的歸一化模板,但是這一方法依然對一些極端情況效果不佳。由於使用者輸入的不確定性,模板存在長尾 query 欠召回的問題。考慮到線上效率問題,我們很難完全將 query 與所有模板進行模型的語義匹配打分。
基於上述問題,我們提出了類似於雙塔模型匹配的方案:將模板通過 BERT 模型生成對應的模板向量,建立模板向量索引。當無法得到合適的模板進行 query 解析時,輸入 query 會經過 BERT 模型得到 query 向量,隨後在模板向量索引中召回一部分相似模板向量,最後通過人工設定的閾值判斷是否接受候選模板。在實際業務中,使用這一方法進行應答的佔比較小。
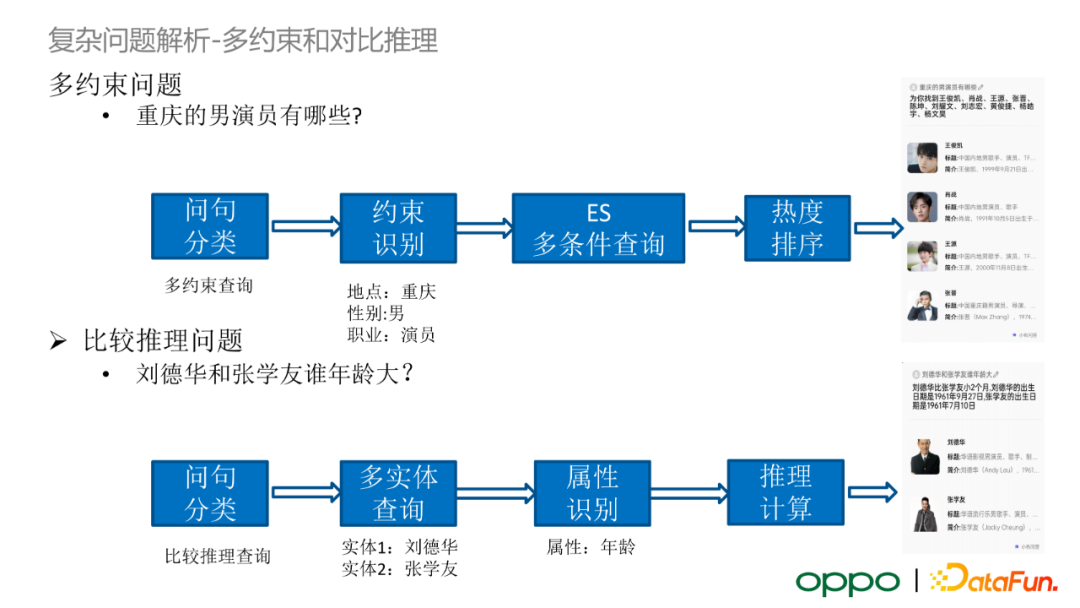 使用者可能會提出多約束問題,例如“重慶的男演員有哪些?”。我們會利用問句分類模組判斷出 query 屬於多約束查詢,隨後將 query 中包含的所有約束識別出來。在使用多約束查詢時,我們不會在圖資料庫中執行查詢操作,而是選用 ES 進行多條件查詢,這是因為圖資料庫檢索耗時很大。最後,我們將 ES 查詢輸出進行熱度排序,輸出相對合理的結果。類似地,對於比較推理問題,我們首先利用問句分類模組識別出 query 屬於比較推理查詢,隨後在圖譜中進行多實體查詢,根據比較推理中需要查詢的屬性判斷兩個實體對應的屬性是否可比。若多實體屬性是可比的,我們會執行推理計算,最終輸出推理查詢的結果。
使用者可能會提出多約束問題,例如“重慶的男演員有哪些?”。我們會利用問句分類模組判斷出 query 屬於多約束查詢,隨後將 query 中包含的所有約束識別出來。在使用多約束查詢時,我們不會在圖資料庫中執行查詢操作,而是選用 ES 進行多條件查詢,這是因為圖資料庫檢索耗時很大。最後,我們將 ES 查詢輸出進行熱度排序,輸出相對合理的結果。類似地,對於比較推理問題,我們首先利用問句分類模組識別出 query 屬於比較推理查詢,隨後在圖譜中進行多實體查詢,根據比較推理中需要查詢的屬性判斷兩個實體對應的屬性是否可比。若多實體屬性是可比的,我們會執行推理計算,最終輸出推理查詢的結果。
知識問答——非結構化問題問答
 接下來簡單介紹一下 OPPO 對於非結構化問答的解決方案。
接下來簡單介紹一下 OPPO 對於非結構化問答的解決方案。
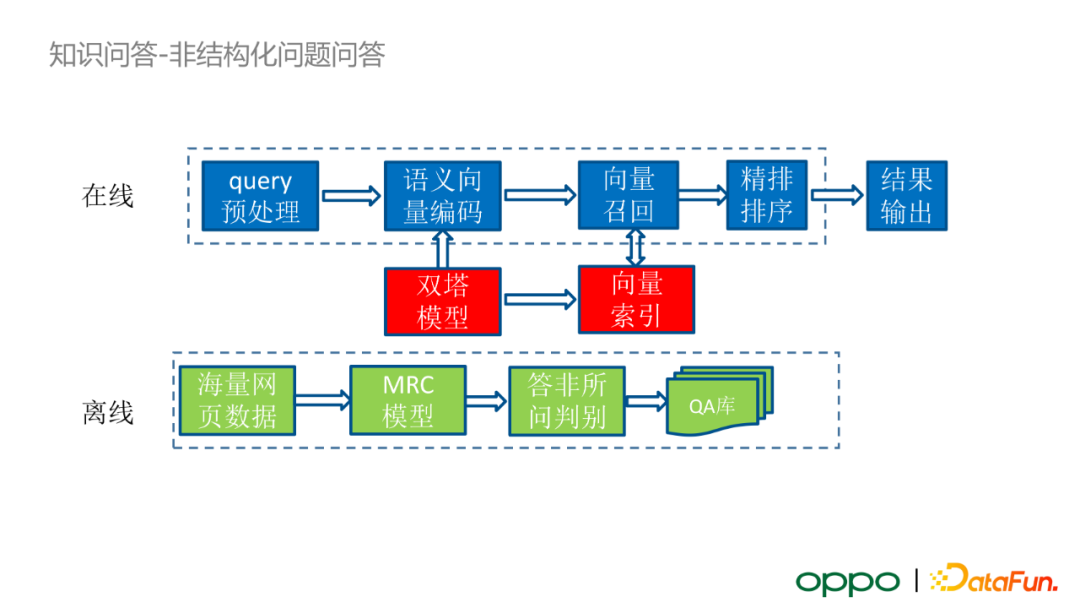
離線情況下,我們選取了業界流行的海量網頁資料 +MRC 模型進行答案抽取的框架。首先,利用搜索 query 中包含的大量 URL 和點選日誌,獲取 query 對應的網頁文字資料;隨後,將 query 與網頁文字資料輸入 MRC 模型,得到 query 在文字中對應的答案;之後,答案會經過一個離線訓練好的“答非所問”判別模型,篩選出那些與 query 真正相關的答案;最終離線構建問題-答案的資料庫。
此外,基於構建的 QA 庫,我們會使用雙塔模型構建 QA 資料庫的向量索引。線上查詢時,query 首先會經過意圖識別和文體型別識別的模組。在 OPPO 業務設定中,使用 KBQA 的優先順序大於使用非結構化問答框架的優先順序。如果 KBQA 無法針對輸入 query 返回結果,那麼 query 會被輸入至非結構化問題的向量檢索框架中。Query 會被雙塔模型進行語義向量編碼,隨後在索引庫中進行向量召回得到 topK 候選 QA。由於向量召回的方案會丟失 query 與答案的互動資訊,所以在得到候選 QA 後,query 向量與候選向量會經過一個精排模型增強語義互動,得到最終的精排排序打分。根據預設的閾值,我們可以選擇接受或拒絕候選 QA 結果。
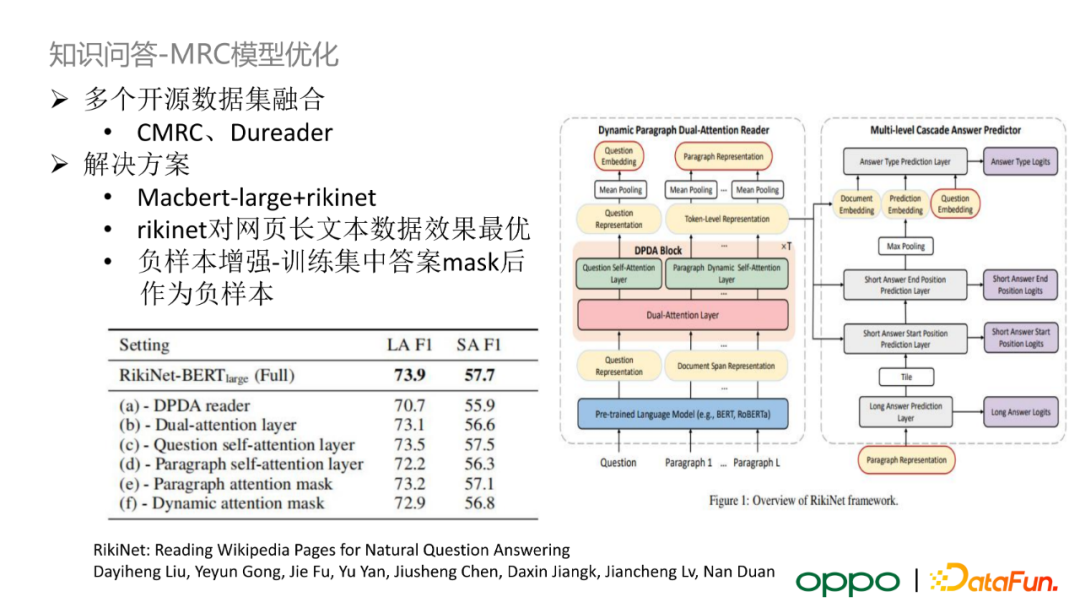
我們針對 MRC 模型進行了一些優化。首先,我們選擇 RikiNet 作為 MRC 模型。它的特點是對網頁中長文字的資料處理效果最優,其潛在的原因是 RikiNet 會對輸入文字進行段落劃分,在語言模型 attention 機制中不同段落之間沒有資訊互動,避免不同段落之間的噪聲資訊影響答案資訊。
總結與展望
最後,對今天分享的內容做一個總結和展望。
雖然 OPPO 著手構建知識圖譜的時間相對較晚,但是在構建過程中積累了大量經驗。首先,圖譜構建演算法是建設高質量知識圖譜的關鍵環節,我們會優先保證演算法的準確率,對召回率的要求相對較低。其次,針對知識問答演算法,在離線時我們會訓練用於模板挖掘、閱讀理解的大模型,保證離線挖掘的資料質量;線上服務時,我們會選取線上模板+小模型的方案保證服務效率。
在未來,我們可能會嘗試以下幾類優化方案:
- 常識推理圖譜+常識問答
- 多模態圖譜+多模態問答
- 使用者圖譜+個性化推薦
- 知識圖譜+大規模預訓練語言模型
- 低資源條件的資訊抽取
Q&A
Q:通用百科圖譜的實體量級是多少?有什麼辦法可以降低實體對齊的時間複雜度?
A:OPPO 內部的知識圖譜的實體量級為約兩億,關係數為十幾億的量級。由於圖譜的規模較大,在嘗試降低實體對齊的時間複雜度時,我們首先會對候選實體做類別劃分,例如實體型別是人物則在人物類別的條件下做實體對齊,這相當於借鑑了分而治之的思想降低一部分計算複雜度。隨後,我們採用兩階段的實體對齊演算法。第一階段不會涉及深度學習模型,而是將實體進行粗粒度的分組(如別名相同的實體),選用 Dedupe 和 Spark 框架執行並行化實體對齊。
Q:知識問答中如何判斷 query 的對話領域?
A:小布助手在內部有一套複雜的領域分類和意圖識別系統。例如,在閒聊領域,我們會標註大量的閒聊語料。隨後,我們會訓練 BERT 模型對語料進行分類。
Q:如何辨別語音識別錯誤與新詞的情形?
A:在糾正語音識別錯誤時,我們使用搜索點選日誌對應的網頁 title,與 query 一起輸入模型進行實體識別。這是因為我們認為網頁 title 在大多數情況下都會包含正確的實體名。隨後,我們考慮了偏旁部首的特徵和拼音特徵,當 query 特徵和候選實體特徵的相似度達到了預設的閾值後,那麼我們基本上可以認為這是一個語音識別錯誤而不是一個新詞。
Q:實體消歧模型中會不會加入一些手工特徵?
A:我們會加入一些手工特徵,例如實體的熱度特徵、實體在訓練資料中真正被標註為正例的比例、實體屬性的個數等統計類特徵。
Q:RikiNet 對網頁長文字資料效果更加的原因是什麼?
A:RikiNet設計了一種特殊的 attention 機制。首先,它將長文字按照段落進行切分。一般情況下,短答案只會出現在一個段落中。RikiNet 的 attention 機制使得段落之間不存在注意力互動,這樣就可以讓不存在答案的段落包含的無關資訊無法影響包含答案的段落語義資訊。只不過這只是實驗中的得到的結論,沒有理論支撐。
Q:query 線上模板匹配中,查詢路徑解析的剪枝是如何實現的?
A:例如“印度的首都有多大”這一例子,我們會使用到實體分類輔助剪枝任務。首先,“印度”是一個國家,雖然“首都”可以對映到“國家的首都”或者“王朝的首都”,但由於前面的實體被識別為“國家”,那麼“王朝的首都”的排序就相對靠後。總的來說,我們會根據識別出的實體型別和屬性之間的關係進行剪枝。如果屬性型別不存在衝突,無法直接進行剪枝操作,那麼我們會對候選模板進行熱度排序,即若一個模板在訓練集出現的頻次更高,那麼我們優先考慮這一模板。
Q:請問 OPPO 如何應對方言的語音輸入?
A:OPPO 目前主要支援粵語方言輸入。這一部分的工作是前端 ASR 負責的,所以方言會在 ASR 模組後就轉換為普通話文字輸入了。
今天的分享就到這裡,謝謝大家。
交流圖資料庫技術?加入 Nebula 交流群請先填寫下你的 Nebula 名片,Nebula 小助手會拉你進群~~ 點選此處檢視 NebulaGraph 的 GitHub:GitHub - vesoft-inc/nebula
- 讀 NebulaGraph原始碼 | 查詢語句 LOOKUP 的一生
- 當雲原生閘道器遇上圖資料庫,NebulaGraph 的 APISIX 最佳實踐
- 從全球頂級資料庫大會 SIGMOD 看資料庫發展趨勢
- 「實操」結合圖資料庫、圖演算法、機器學習、GNN 實現一個推薦系統
- 如何輕鬆做資料治理?開源技術棧告訴你答案
- 圖演算法、圖資料庫在風控場景的應用
- 「實操」適配 NebulaGraph 新版本與壓測實踐
- Chaos 測試下的若干 NebulaGraph Raft 問題分析
- 如何設計一個高效能的圖 Schema
- 從一個 issue 出發,帶你玩圖資料庫 NebulaGraph 核心開發
- 資料庫運維 | 攜程分散式圖資料庫NebulaGraph運維治理實踐
- 百度愛番番基於圖技術、流式計算的實時CDP建設實踐
- ChatGPT 加圖資料庫 NebulaGraph 預測 2022 世界盃冠軍球隊
- 58 同城一鍵部署運維架構的實踐 - 叢集搭配管理平臺多場景降本增效
- 蘇寧構建知識圖譜的大規模告警收斂和根因定位實踐-AI 監控保證日常和大促穩定性
- NebulaGraph 的雲產品交付實踐
- 基於圖資料庫、圖演算法、圖神經網路的 ID Resolution/ID Mapping 大資料分析方法與程式碼示例
- 基於圖演算法、圖資料庫、機器學習、GNN 的欺詐檢測方法與程式碼示例
- 攜程分散式圖資料庫Nebula Graph運維治理實踐—大規模叢集部署與二開優化
- 圖資料庫賽道興起,看 NebulaGraph 如何打造差異化!