亞馬遜雲科技實時數倉相關產品的特點和優勢
近年來,各級政府和企業響應數字化轉型的號召,都已開始或者即將開始數字化轉型。各類企業通過前期的業務線上化、資訊化,積累了大量資料,而數字化轉型就是要聚合這些資料,進行深入挖掘分析,用資料來驅動業務,用資料來支撐決策、用資料來推動業務和商業模式創新、推動業務流程優化,進而實現降本增效。
要實現資料價值,建設資料倉庫是在數字化轉型過程中不得不面對的一項任務。資料倉庫匯聚各個業務部門資料,避免資料孤島,使資料真正成為整個企業的資料,而不是某個部門的資料。
資料倉庫的技術架構包括離線數倉和實時數倉或準實時數倉。離線數倉已發展多年,當前已無法完全滿足企業在競爭中脫穎而出的發展需求,實時數倉越來越多成為企業建設資料倉庫的首選。然而由於實時數倉對實時性的嚴格要求,實現實時數倉的技術難度遠遠大於離線數倉,一些現有的實時數倉架構,只能實現準實時,而且無法解決削峰平谷、無感擴充套件等問題。
本文為大家提供一種高效的實時數倉架構:基於亞馬遜雲科技 Serverless 架構的實時數倉架構。
實時數倉常見場景與亞馬遜雲科技的做法賞析
我們先來賞析一下常見的實時數倉場景,以及亞馬遜雲科技Serverless架構的實時數倉成功落地的案例:
1、APP 埋點資料實時採集與分析(比如:實時智慧推薦、實時欺詐檢測)
在此,我們以智慧推薦場景為例:根據使用者歷史的購買或瀏覽行為,通過推薦演算法預測使用者興趣與需要,並從海量推薦資產(可能是短影片、廣告、動圖)中挑選最合適的進行推送。推薦系統在飛速發展,對時延的要求也越來越苛刻和實時化。往往業務方希望客戶在使用App(或瀏覽網頁)時,就能基於當前行為和歷史資料進行動態推薦。
資料來源一般為App埋點採集和歷史瀏覽資料、消費資料、和廣告資產等。
常見做法:流式ETL與資料同步與傳輸可能會用到Flume、Kafka等工具,計算有可能會採用ClickHouse、Flink、Spark等大資料計算工具。資料來源端和資料消費端就五花八門一些,在此不作展開。(同樣的技術架構也出現在實時欺詐檢測等場景中)
我們來看一下亞馬遜雲科技的案例:使用 Amazon Kinesis Data Streams (流式資料接入產品,Amazon KDS)實時接入 APP 埋點資料到 Amazon Redshift(雲原生資料倉庫) 中,用於指標分析和 BI 展現。支援高達30萬/秒的資料攝入速率,延遲小於10秒;在資料實時攝入數倉的同時,支援高併發實時查詢,支援大寬表多表關聯,複雜聚合等各種 SQL 查詢,查詢結果秒級響應。

圖1 實時數倉架構--APP 埋點資料實時採集與分析
2、RDBMS CDC+KDS+Amazon Redshift Serverless(實時BI報表、複雜事件處理)
在這個案例中,主要採集源頭日誌資料和 RDS 結構化資料的變更資料動態捕獲(Change Data Capture,CDC)。這是一個數據倉庫非常常見的需求,外部資料庫系統(賬戶、存款、製造、人力資源等)作為資料來源時,業務團隊需求需要CDC日誌資料動態接入資料倉庫,實現實時的分析需求,比如實時BI報表、複雜事件處理(應急響應)。
CDC日誌資料通過 Amazon Kinesis 實時傳送到 Amazon KDS,經過流處理後,結果寫入 RDS,並提供 API 的方式供第三方查詢。同時,Amazon Redshift可以直接消費 Kinesis 資料,用於查詢分析,整體延遲小於30秒。
CDC日誌採集方式支援多種,包括 Amazon DMS、Debezium、Flink CDC、Canal 等,採集資料寫入Kinesis後,接著使用 Amazon Redshift Streaming Ingestion 功能將CDC資料實時寫入 Amazon Redshift。
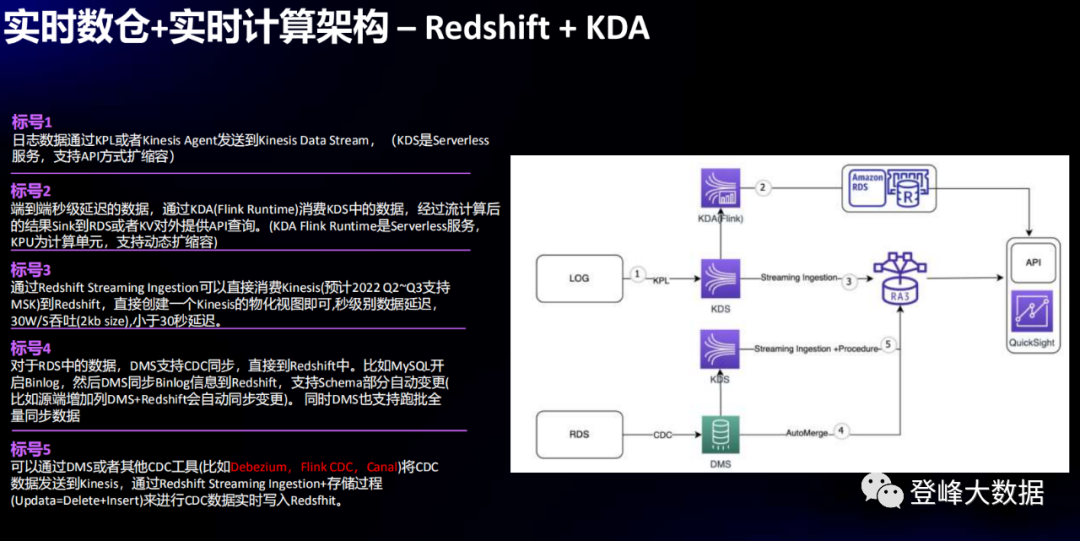
圖2 實時數倉--RDBMS CDC+KDS+Amazon Redshift Serverless
經典解決方案—藉助Amazon Redshift打造雲原生數倉
在繼續開展下文前,需要介紹一個無法繞過的產品——Amazon Redshift ,一種快速、可擴充套件、安全且完全託管的雲資料倉庫,可以幫助使用者通過標準 SQL 語言簡單、經濟地分析各類資料。
無論是構建傳統資料倉庫架構還是實時數倉架構,藉助Amazon Redshift使用者都可以一站式的進行部署。相比其他雲資料倉庫,Amazon Redshift 可實現高達三倍的效能價格比。數萬家客戶正在藉助 Amazon Redshift 每天處理 EB 級別的資料,藉此為高效能商業智慧(BI)報表、儀表板應用、資料探索、實時分析和等分析工作負載以及機器學習、資料探勘提供強大動力。Amazon Redshift支援ACID事務特性、ANSI SQL標準、JDBC/ODBC 連線協議的 MPP 架構列式儲存資料倉庫。Amazon Redshift 不僅可以基於自身內部表進行資料分析,還可以查詢 Amazon S3 中的資料,S3 是一項具備極致彈性的物件儲存,它已經成為了雲上資料湖事實上的標準,既可以儲存結構化資料,也可以是半結構化資料、非結構化資料。Redshift與S3 可以無縫結合,實現智慧湖倉架構。
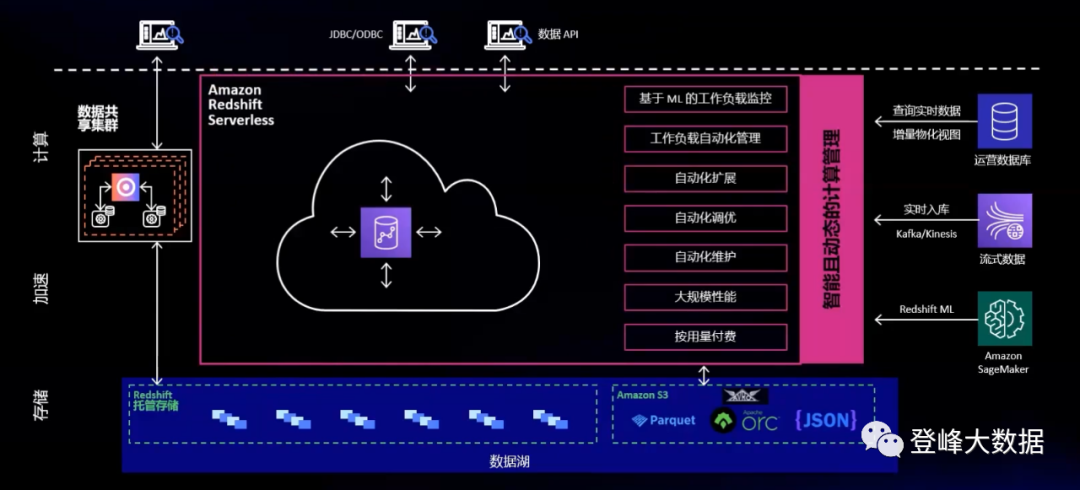
圖3 Amazon Redshift Serverless 架構
實時數倉架構要解決的問題
良好的實時數倉架構,可以解決以下四方面的問題:資料實時接入、資料實時分析、資料實時輸出。
-
資料實時接入:資料倉庫主要用來儲存來自各個業務系統的資料。實時數倉的第一步,就是要解決資料如何實時進入資料倉庫的問題。
-
資料實時分析:實時接入的資料,要能夠立即可用,滿足即席查詢、報表分析和挖掘預測的需求,資料準,延遲低。
-
資料實時輸出:資料實時分析的結果,要能夠及時進行 BI 報表展現、及時以資料服務的形式提供給第三方。
-
實時數倉智慧化:資料分析解決的是過去發生了什麼,數倉智慧化要解決的是未來要發生什麼。讓實時數倉具備機器學習、智慧預測能力,是實現智慧湖倉的必備功能。
Serverless 架構不僅彌補了傳統離線數倉的不足,而且完美解決了上述四方面的問題,先看下整體實時數倉架構圖:
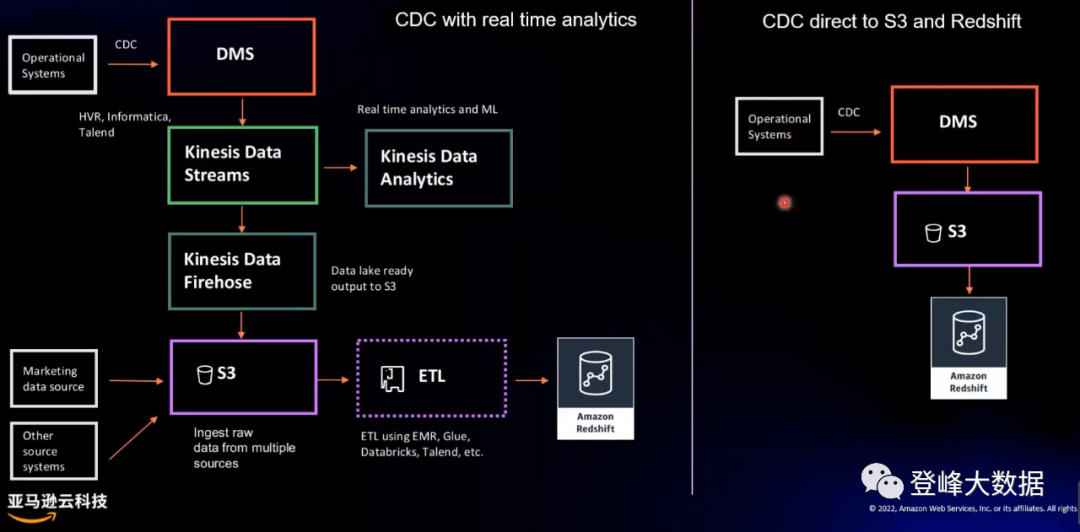
圖4 亞馬遜雲科技 Serverless實時數倉架構圖
Serverless 實時數倉架構採用 Amazon KDS(Amazon Kinesis Data Streams) + Amazon Redshift Serverless+Redshift ML+S3 技術產品組合,KDS 負責資料的實時接入,Redshift Serverless+Redshift ML+S3 負責"智慧湖倉"的落地,實現資料實時分析、實時輸出、實時預測。同時,Redshift Serverless 架構,運維簡單,按需計費,降本增效,將客戶從紛繁複雜的架構搭建、監控、運維中解放出來,專注於資料查詢分析,資料價值挖掘,實現資料驅動決策。
-
資料實時接入:接入的資料,可以分為三大類:結構化資料(資料庫資料)、半結構化資料(Json、CSV資料)和非結構化資料(圖片影片資料)。
對於源自資料庫的結構化資料,通用的實時接入方式是使用 CDC 技術增量接入。在亞馬遜雲科技實時數倉架構中,採用Amazon DMS產品接入CDC資料到Amazon KDS。Amazon DMS支援同構遷移、不同資料庫平臺之間的異構遷移和CDC資料接入,可以從任何支援的源中將資料低延遲、持續地複製到任何支援的目標。此外,利用 Amazon Redshift 流式攝取功能可以將 Kinesis 中的資料以極低延遲攝取到 Amazon Redshift 中。
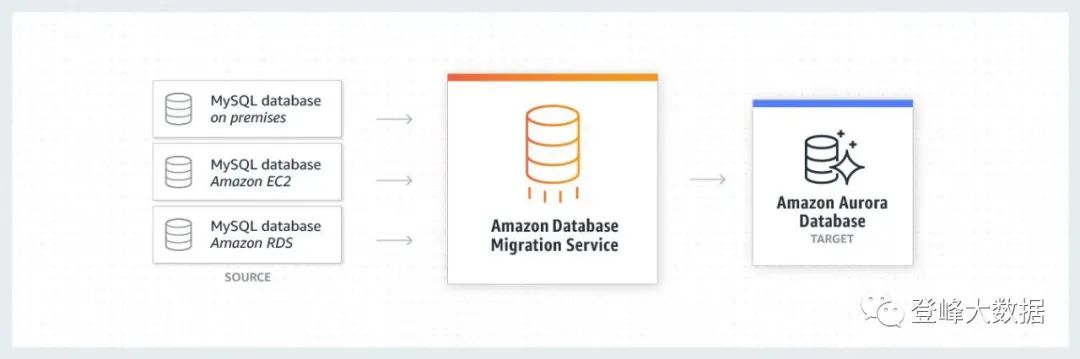
圖5 Amazon Database Migration Service (Amazon DMS) 遷移資料到智慧湖倉
對於非結構化資料,傳統實時接入方式是掃描指定目錄,將新增檔案寫入檔案系統(HDFS、Amazon S3 等),然後開發程式解析檔案,寫入資料庫表中。然而,採用亞馬遜雲科技提供的 DMS+S3+Redshift 方式,無需開發資料解析程式,只需通過簡單的配置,即可實現資料入寫 S3,Redshift 可與 S3 完美整合,即資料進入 S3,即可在 Redshift 中查詢分析。
-
資料實時分析:資料的實時分析,由 Amazon Redshift Serverless 提供,智慧湖倉的各個分層都建立在 Redshift 資料庫中,使用 SQL 語句做數倉指標計算,採用 ETL 工具排程指標計算任務,相容開源 ETL 工具,也可以使用亞馬遜的 ETL 工具。
-
資料實時輸出:Amazon Redshift 支援 JDBC 協議,可以作為各類 BI 報表產品的資料來源,實現資料的實時輸出;Amazon Redshift Data API 可以將資料以 API 的方式提供給第三方,Amazon Redshift Data API 不需要與叢集的持久連線。提供了安全 HTTP 終端節點以及與亞馬遜雲科技開發工具包的整合。使用終端節點執行 SQL 語句,無需管理連線。對 Data API 的呼叫是非同步的。
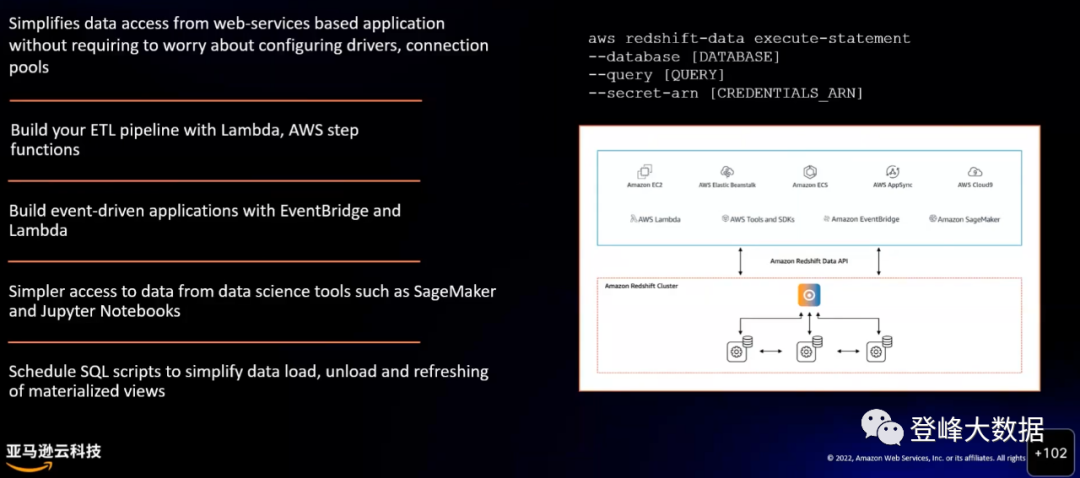
圖6 Amazon Redshift Data API
-
Amazon Redshift 實時數倉+ML:為實時數倉增加機器學習和人工智慧的能力,是大多數企業在建設實時數倉過程中面臨的一個難題,主要問題在於:1、機器學習的門檻高;2、機器學習開發人員招聘困難。Amazon Redshift實時數倉架構利用 Amazon Redshift ML 產品解決了上述難點,大大降低了建設智慧湖倉的難度。
Amazon Redshift ML 使 SQL 使用者可以輕鬆地使用熟悉的 SQL 命令建立、訓練和部署機器學習模型。通過使用 Amazon Redshift ML,可以使用 Redshift 叢集中的資料來通過 Amazon SageMaker 訓練模型。隨後,模型將會本地化,並可在 Amazon Redshift 資料庫中進行預測。藉助 Amazon Redshift ML,無需移動資料或學習新技能,即可利用 Amazon SageMaker 這種完全託管的機器學習服務。
藉助由 Amazon SageMaker 提供支援的 Amazon Redshift ML,使用 SQL 語句從 Amazon Redshift 中的資料建立和訓練機器學習模型,然後將這些模型用於多種使用案例場景,例如直接在查詢和 BI 報表中進行流失預測和欺詐風險評分。
用寫 SQL 語句的方式,開發機器學習功能,底層各種機器學習演算法的複雜性,交由 Amazon Redshift ML 解決,客戶可以將更多的精力專注在業務上面。
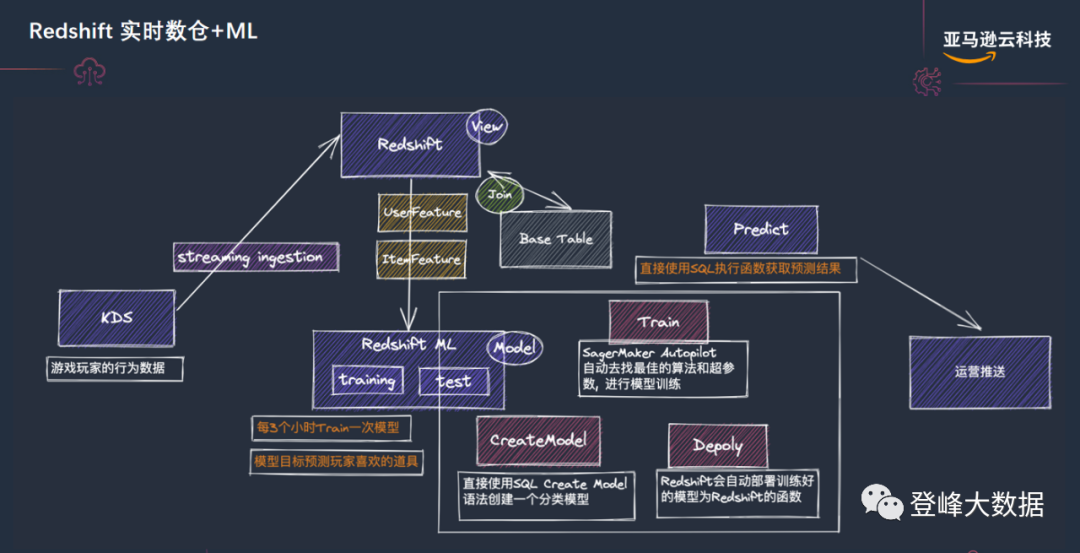
圖7 Amazon Redshift 實時數倉+ML
Serverless 實時數倉架構的優勢
成熟的技術架構,可以大大降低企業的人力和財力成本。傳統的實時數倉架構(採用託管伺服器的方式),無法實現削峰平谷。以電商行業為例,實時數倉架構的伺服器資源,必須能夠應對資料高峰(各類大型活動、促銷與其他不可預測的工作負載)帶來的壓力,所以硬體採購往往是按資源峰值採購的,結果是大部分資源在大部分時間都是閒置的,無形提高了企業成本;傳統實時數倉架構,無法實現無感擴充套件,即伺服器叢集節點的增加和減少,會增加運維人員工作量,可能會帶來業務的暫停。總的來說,Serverless 實時數倉架構的優勢包括如下幾點:
-
Serverless 實時數倉架構讓資料倉庫優雅的具備實時資料分析能力(實時 OLAP 看板,實時業務監測);
-
Serverless 實時數倉架構讓實時智慧分析成為可能(基於實時資料與歷史資料的實時風控/實時推薦/實時機器學習);
-
亞馬遜雲科技提供了雲上實時數倉搭建最全面的功能元件,讓使用者可以敏捷,高效,低成本的構建自己的實時數倉;
- 使用 Serverless 實時數倉雲平臺,自動擁有削峰平谷、無感擴充套件、運維簡單、易於使用等優勢。
轉載自登峰大資料
- 搬得進來,搬得出去!快來過一把資料遷移的“癮”
- NGINX中文社群邀您參與問卷調研,送Apple AirPods無線耳機
- 亞馬遜雲科技構建無處不在的雲
- 為什麼事件驅動架構這麼火?亞馬遜雲科技給你答案
- 共碼未來丨2022 Google 谷歌開發者大會主旨演講亮點回顧
- Google 谷歌開發者大會觀看指南,速速收藏!
- 2022 Google 谷歌開發者大會亮點搶先看
- 一個人也能搞自動駕駛?亞馬遜雲科技是這麼說的
- 亞馬遜雲科技實時數倉相關產品的特點和優勢
- 資料量暴漲下 IT 成本走高,儲存技術該創新了
- AI新引擎為何可以幫助企業應對“烏卡時代”?
- 市場遇冷,看雲原生資料庫如何助力企業降本增效與持續創新
- 從功能模組、元件到架構,大資料平臺建設如何更好的適配業務?
- 期待重聚丨 2022 Google 谷歌開發者大會即將回歸!
- 借生態力量,openGauss突破效能瓶頸
- 他們齊聚 2022 ECUG Con,只為「中國技術力量」
- “軟體定義世界,開源共築未來” 2022開放原子全球開源峰會7月底即將開啟
- 沒有紮實的雲底座,有資格談數字化轉型?
- 立即加入 NGINX 微服務之月,贏取獨家定製好禮!
- Microservices June 微服務之月即將開啟!