帶你重走 TiDB TPS 提升 1000 倍的效能優化之旅
今天我們來聊一下資料庫的效能優化,第一部分簡單介紹一下效能優化的通用的方法,第二部分我們講一個實際案例。
效能優化這個事情核心只有一句話,使用者響應時間去哪兒了?效能優化很困難的原因在於,為了定位使用者響應時間在各個模組的分佈,需要對系統的各個部件進行測量和分析,從底層硬體,CPU、IO、網路到上層應用架構,應用程式碼跟資料庫的互動方式都需要涉及。
使用者響應時間
效能優化的第一個概念是使用者響應時間。使用者響應時間是使用者在使用一個業務系統的時候,發起一個請求到這個請求返回總體消耗的時間為使用者響應時間。一個典型的使用者響應時間的分佈如下圖:
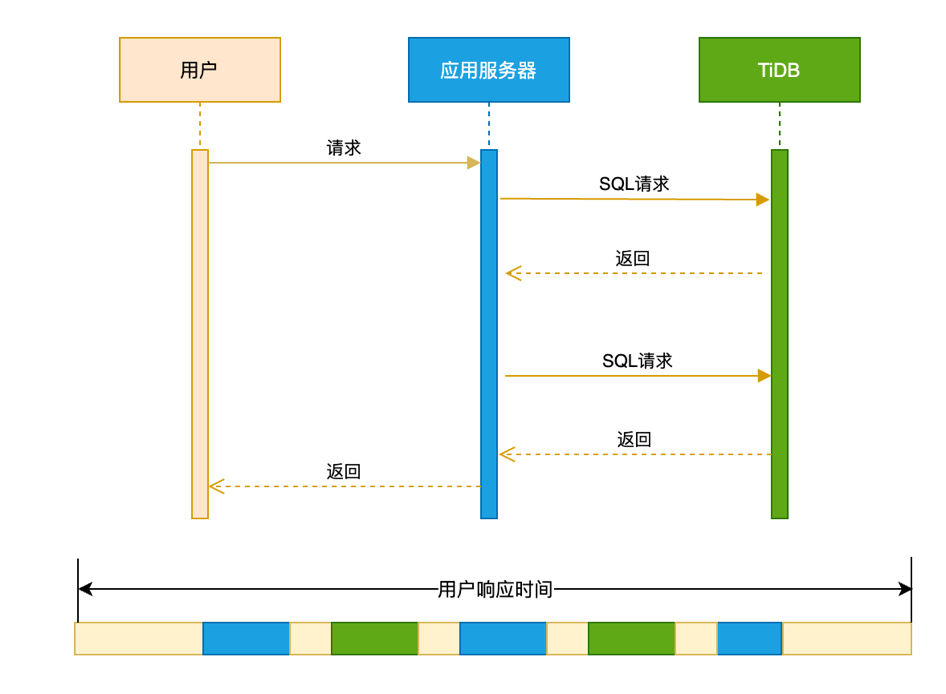
從時序圖看,一個使用者響應時間可能包括:
-
使用者請求到達應用伺服器的網路時間
-
應用伺服器本身業務邏輯處理時間
-
應用伺服器跟資料庫伺服器之間互動消耗的網路時間
-
資料庫多次處理 SQL 的時間
-
應用伺服器返回使用者資料的網路時間
整個鏈路上來看,會涉及到網路、應用伺服器和資料庫這幾個重要的部件。只要知道戶響應時間在每個模組的分佈,我們就能定位瓶頸,進行鍼對性的優化。
現實中效能瓶頸的定位又非常難。因為絕大部分的應用都沒有去部署 APM 之類的工具,能夠去跟蹤一個應用請求在全鏈路上面的時間消耗。大部分場景的效能優化工作,都是在缺乏全域性的時間分佈情況下進行的。我們推薦的一種可靠的效能優化的方法:基於資料庫時間進行效能優化。
資料庫時間
資料庫時間為單位時間內資料庫提供的服務時間。對比資料庫時間和應用總的使用者響應時間,可以判斷應用系統的瓶頸是否在資料庫中。
一個應用系統,ΔT 時間內提供的總的服務時間,可以拿平均業務的 TPS 乘以平均的響應時間。ΔT 時間內的資料庫時間,有多種演算法:
-
平均 TPS X 平均事務延遲 X ΔT
-
平均的 QPS X 平均的延遲 X ΔT
-
平均的活躍連線數 X ΔT, 下圖資料庫活躍連線圖的面積即為資料庫時間
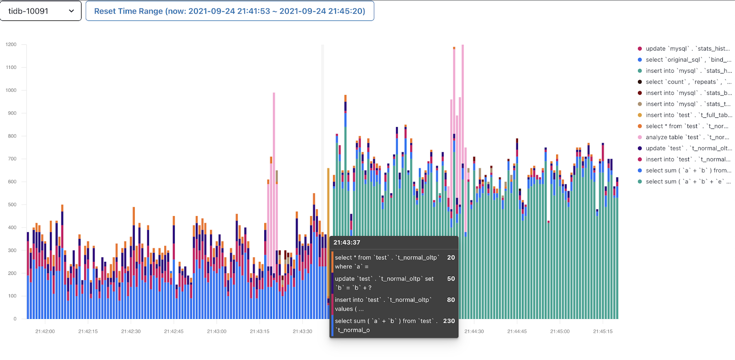
基於資料庫時間和使用者響應時間的對比,先從全域性的角度判斷瓶頸在資料庫裡面還是在資料庫的外面,然後再進行鍼對性的排查和優化。把資料庫時間除以總的使用者響應時間:
-
趨近 0,資料庫時間在總的服務時間裡面是很小的佔比,說明瓶頸並不在資料庫中。
-
趨近 1,說明整個應用系統瓶頸是在資料庫裡面。工程師通過降低資料庫時間來進行效能優化,比如優化 SQL 執行計劃、解決資料庫中存在的熱點爭用等。
實際案例
背景
這個例子是我們與合作伙伴一起完成的課題,銀行核心應用在分散式資料庫和國產 ARM 伺服器上聯合優化的案例。系統的硬體採用的是 ARM 伺服器,每臺伺服器有 16 個 Numa,每臺機器有一個 NVMe 盤。銀行核心應用的負載屬於 “Read Heavy”,查詢語句佔比 66%。本次應用涵蓋 4 支混合交易。
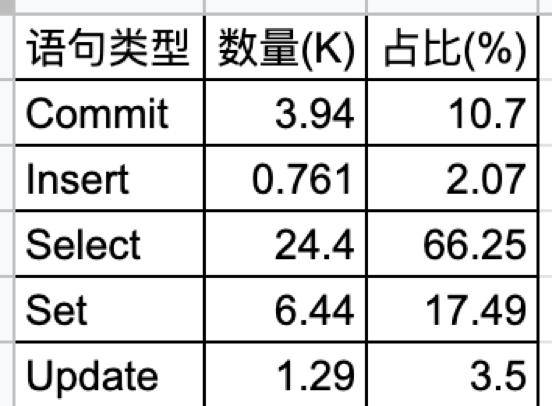
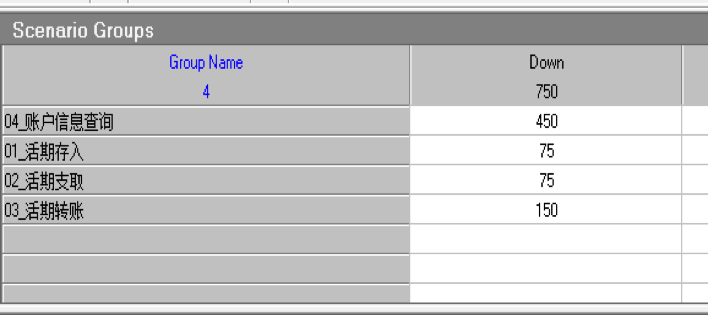
TPS 從 1 到 30
這個結果在合作伙伴的實驗室跑起來之後,業務的 TPS 只有 1 左右,遠低於預期。
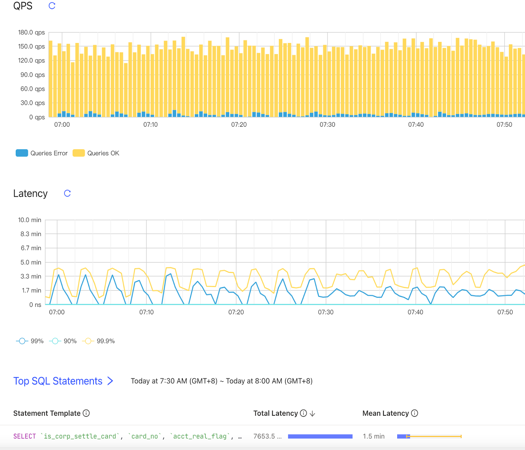
業務端會有超時的報錯 (Coprocessor task terminated due to exceeding the deadline)。通常這種情況都是執行計劃不優化造成的,比如說缺少索引,導致需要全表掃描。從 TiDB 的 Dashboard 上面會看到資料庫的 QPS 只有 100 左右,80、90-in-txn 的延遲超過一分鐘,再看 Top SQL,可以看到有 Top SQL 因為缺失索引在走全表掃描的。
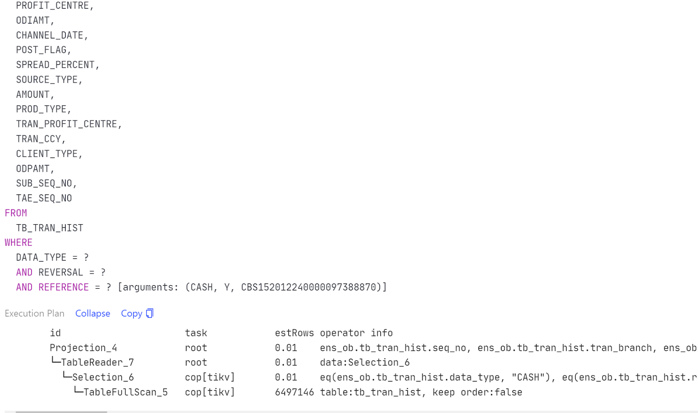
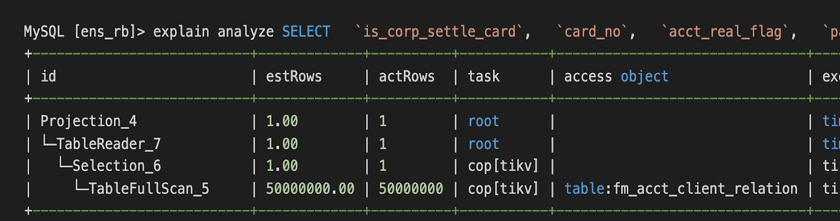
第一個 SQL 優化例子是解決索引缺失的問題,第二個 SQL 優化的例子是解決有索引卻用不上的問題。因為業務系統上使用了 OR 條件,即使 OR 兩端的過濾欄位上都有索引,也預設走全面掃描。需要手工開啟 index merge 功能 (set @@global.TiDB_enable_index_merge=on),執行計劃才走索引。
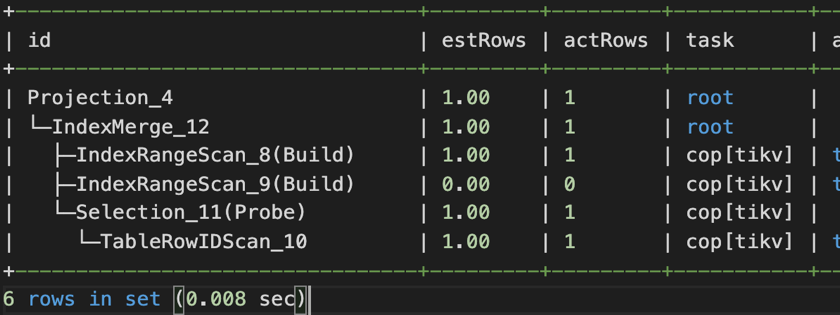
優化這兩類慢 SQL 之後之後,TPS 上升到了 30 以上。
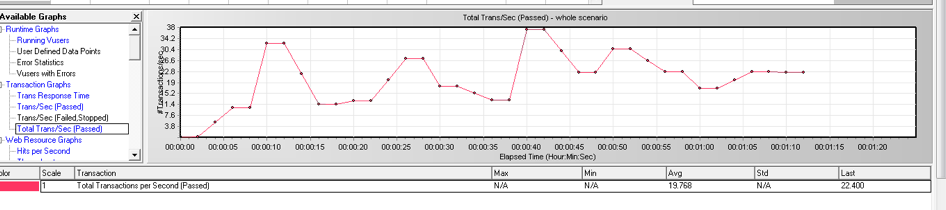
TPS 從 30 到 320
接著為了提高資源利用率,我們檢查了一下叢集的拓撲。測試環境是六臺 ARM 伺服器,每臺16 個 Numa,每個 Numa 是 8C 16GB。現有的拓撲部署了 3 個 TiDB + 3 個 TiKV。TiDB 是繫結到 0~4 的 Numa 上面,沒有充分利用整個機器的能力。我們對這個組網的方式做了調整,部署了 36 個 TiDB + 6 個 TiKV,每個 TiDB 會綁兩個 Numa ,每個 TiKV 有四個 Numa 。做了這個組網方式的修改之後,TPS 上升到了 320。
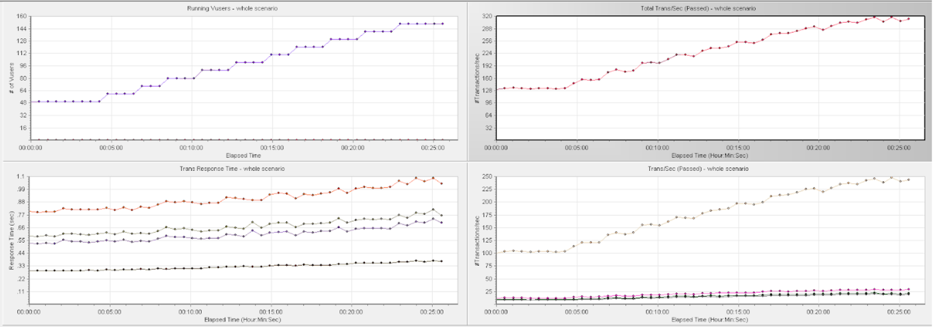
TPS 從 320 到 600
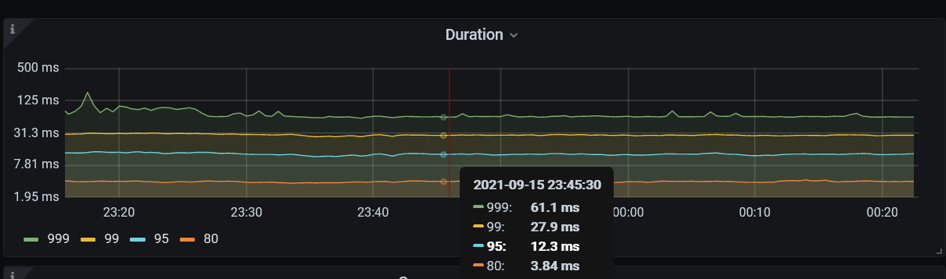
在 TPS 320 的壓力下觀察到一個現象是,資料庫的 CPU 利用率比較低,每個 TiDB 雖然綁定了兩個 Numa ,有 16 核的 CPU,但是 CPU 使用在 100% - 520%,用了 1-5 個邏輯 CPU 左右。同時,應用伺服器的 CPU 使用率不到 10%。query 80th 延遲是 3.84 毫秒。這是一種非常典型的情況,看起來資料庫的壓力不大,應用伺服器的 CPU 利用率很小,但是總體的 TPS 上不去。目前硬體資源肯定是充足的,我們不確定整個系統的瓶頸在哪裡。根據之前講到的使用者響應時間跟資料庫時間的比例關系:
應用系統每秒響應時間:應用 TPS 300 乘以平均延遲 1 秒 = 300 秒
TiDB 每秒的資料庫時間:QPS 30,000 乘以平均延遲 1.3 毫秒 = 39 秒
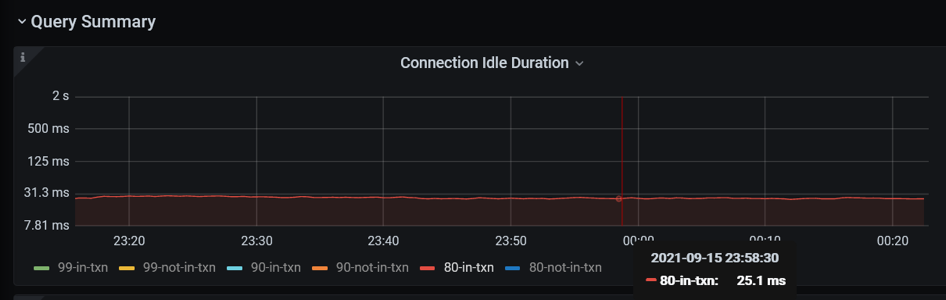
資料庫時間只佔使用者響應時間 13%。在 TiDB 裡面有更直觀的方式,有一個指標叫 connection idle duration,指標記錄一個應用連線提交 SQL 的間隔時間。這個例子,一個 SQL 的處理延遲 80 分位數為 3.84 毫秒,在事務裡面提交 SQL 的間隔時間 80 分位數 25 毫秒。資料庫花了將近 4 毫秒處理完一條 SQL 之後,他要等 25 毫秒才收到下一條 SQL。所以,很明顯這個瓶頸不在資料庫裡面。
確認瓶頸不在資料庫之後,我們對整體的火焰圖和網路做了一些分析。由下方火焰圖可見,整個系統的 CPU 20% 是消耗在一個叫 finish_task_switch 的,做程序切換,排程相關的系統呼叫上,說明系統在核心態存在資源爭搶和序列點。因為有 16 個 Numa,每個 Numa 8 核,一共有 128 核,我們使用 mpstat -P ALL 5 命令對所有 CPU 的利用率進行確認,發現了一個比較有趣的現象 —— 所有的網絡卡的軟中斷(%soft),都打到了第一個 Numa(CPU 0-7)上。因為業務本身網路流量大,軟中斷處理(%soft)在 CPU 0-7 上使用率是 38% 到 94%。又因為我們在第一個 Numa 上面還跑著 TiDB、PD 和 HAProxy 等,使用者 CPU (%usr)是 2% 到將近40%,第一個 Numa 的 CPU 都被打滿了(%idle 接近 0)。其他的 Numa 使用率僅 55% 左右。跟 ARM 廠商機器的工程師聊過,確認 ARM 伺服器默認出廠就會使用第一個 Numa 處理網絡卡軟中斷。網絡卡流量的處理瓶頸解釋了 SQL 提交的間隔時間非常長的原因。
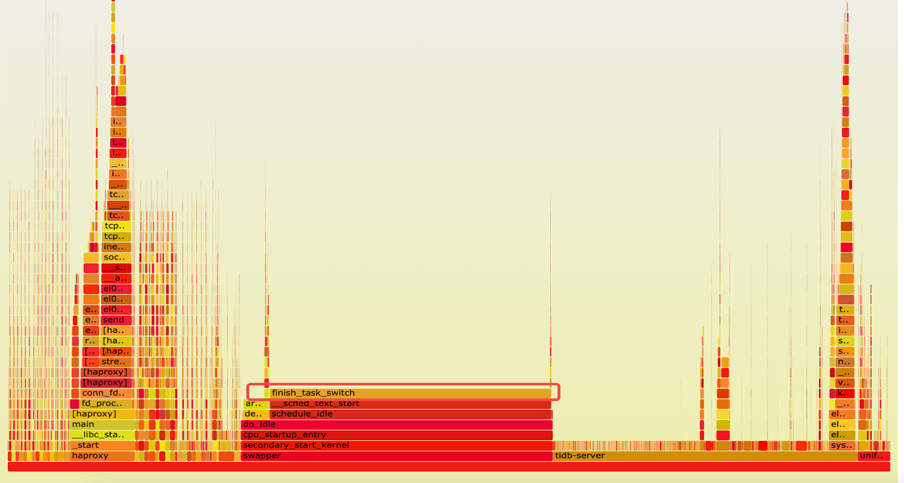
整個系統的火焰圖
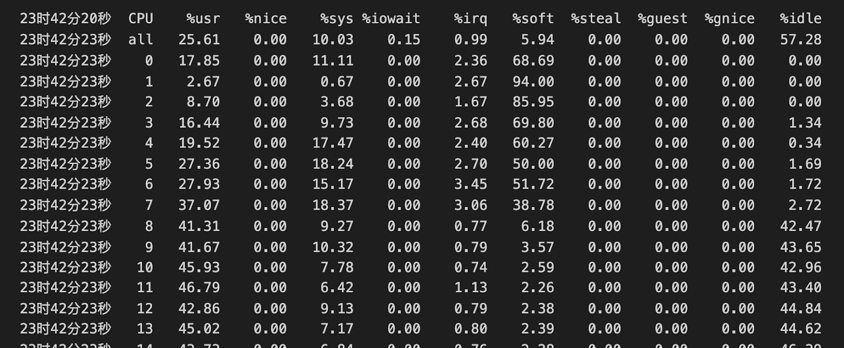
mpstat -P ALL 5 命令輸出
另外,對於沒有綁核的程式 —— PD 和 HAProxy,我們在火焰圖裡面觀察到關於記憶體的訪問或者記憶體的加鎖等系統呼叫佔比非常高。對於開啟 Numa 的系統,其實 CPU 訪問記憶體的速度是不平等的。通常訪問遠端 Numa 的記憶體延遲是訪問本地 Numa 記憶體的十倍。硬體廠商也推薦應用最好不要進行跨 Numa 部署,因為在 ARM 伺服器進行跨 Numa 的記憶體訪問,延遲會更高,極大的影響程式執行效能。
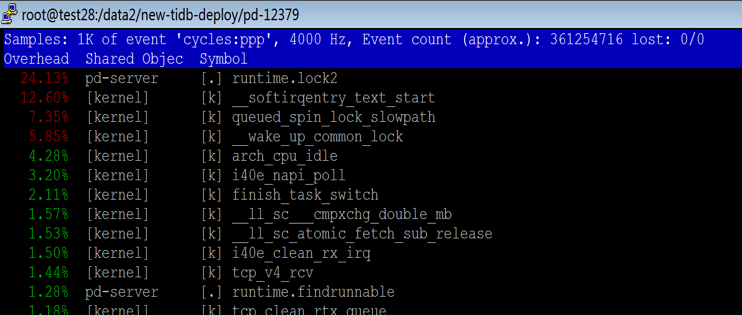
PD-Server 程序 perf top 命令輸出
基於上面的分析,我們進行了組網方式的調整。對於六臺機器,1)第一個 Numa 都空出來專門處理網路軟中斷,不跑任何的程式;2)所有的程式都需要綁核,每個 TiDB 只綁一個 Numa,TiDB 的資料翻倍, PD 和 HAProxy 也進行綁核。做了這個調整之後,應用的 TPS 上升到 600。Connection Idle duration 的 80-in-txn 延遲就從 26 毫秒下降到 5 毫秒。
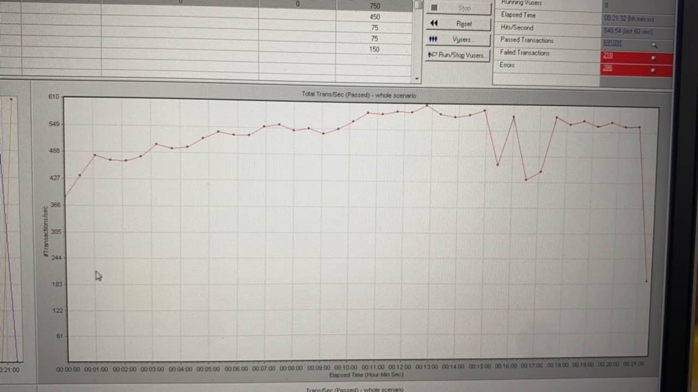
TPS 從 600 到 880
資料庫最大連線數穩定在 2000,應用加大併發連線數也沒有提升。使用 mysql 連線 HAProxy 地址會報錯。因為 HAProxy 單個 proxy 後臺 session 限制預設兩千,通過把 HAProxy 從多執行緒模式改成了多程序的模式可以解除這個限制。變更之後連線數上升到 4400,TPS 上升到 880。
Load Runner
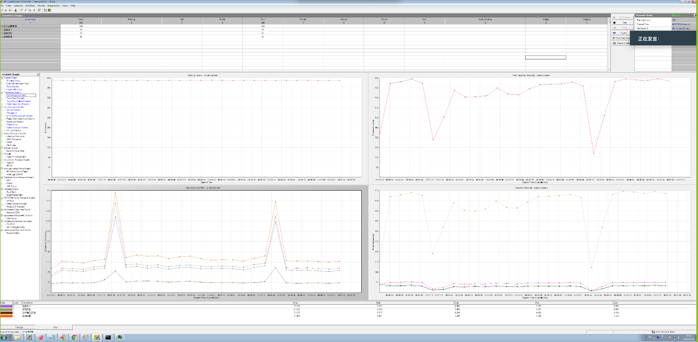
TPS 抖動解決
TPS 880 時應用出現明顯的波動,事務處理延遲出現巨大的波動。從 Dashboard 中可以看到同樣的 QPS 波動,P999 延遲在同樣的時間出現小的尖刺。資料庫是造成應用效能波動的原因嗎?
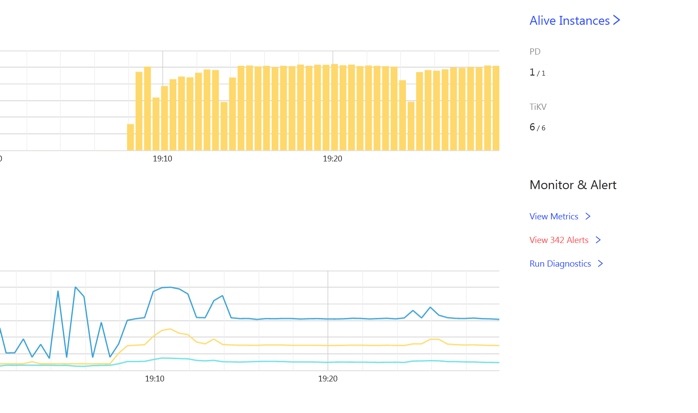
帶著這個疑問,在監控上我們修改 promtheus 的表示式,檢視 P9999 延遲,發現波動巨大,比 P999 明顯。時間點和 load runner 的資料可以對齊。檢視 TiKV-Detail 的監控發現 TiKV 例項出現重啟,通過系統資訊確認 TiKV 出現 OOM (out of memory)。OOM 的原因是之前遺留了 3 個 TiKV 例項 scale-in 之後,只是變成 TombStone 但沒有清除,導致現有的 TiKV 例項 OOM。
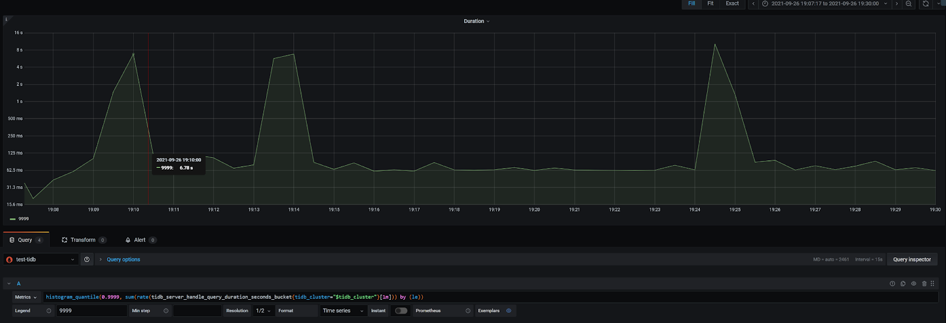
Duration P9999
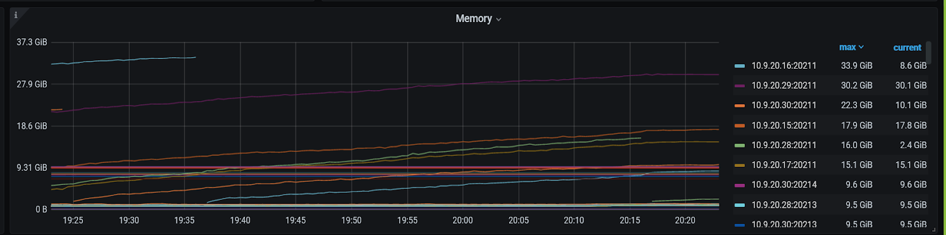
Grafana TiKV-Detail 面板觀察到 OOM 重啟

TiKV.log 日誌顯示 OOM
SQL 執行計劃穩定性 - 永不準確的統計資訊
在某一次壓測的過程中,應用 TPS 掉為 0,從 TiDB Dashboard 我們發現出現一條 Top SQL。這個 sql 執行計劃發現了變化,出現了兩個執行計劃。MQ_PRODUCER_MSG 是一個訊息隊列表,query 包含 flow_id 和 status 兩個過濾條件,flow_id 和 status 上面都有單列的索引。常的執行計劃是走 flow_id 的上面的索引,平均執行時間是 62 毫秒。出問題的時候,優化器選擇 status 列索引,執行時間是 38 秒。
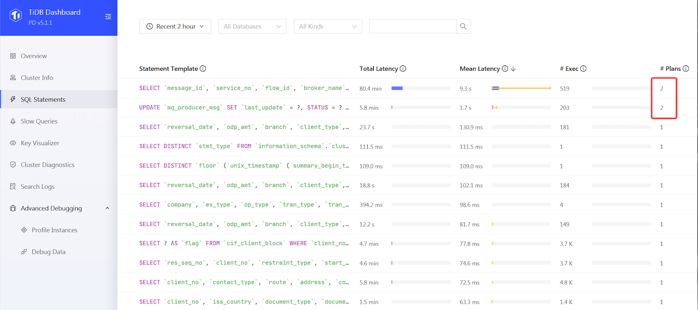

在錯誤的執行計劃中,對於條件 status=1,優化器估算為 0 行,所以選擇 了 status 列上面的索引。我們嘗試重現,對 status =1 的條件做一個 explain analyze,估算值是四萬多,並沒有出現估算等於 0 情況。

接著分析慢日誌,63 個 TiDB 例項都出現這個錯誤的執行計劃,一共有 94 個連線執行了錯誤的執行計劃,也就是每個 TiDB 例項有一個或者兩個連線執行過這個錯誤的執行計劃。
select instance, count(*) from information_schema.cluster_slow_query where index_names like '%MQ_STATUS_INDEX%' group by instance;
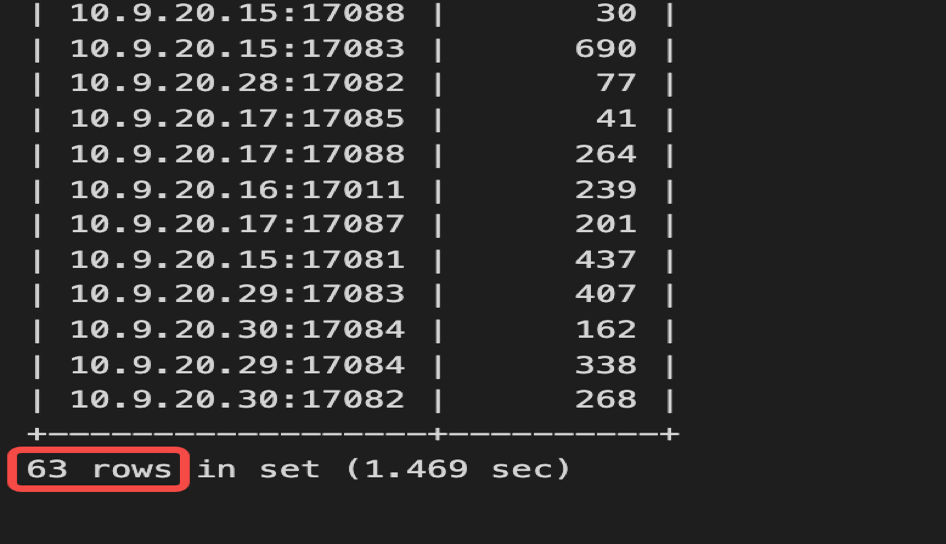
select conn_id,instance, count(*) from information_schema.cluster_slow_query where index_names like '%MQ_STATUS_INDEX%' and digest = 'cca85ee01e54b3b37775c8b07c2808f306177d28fd0376b2d8c5dd5663f488ec' group by instance,conn_id;

基於以上的分析我們懷疑錯誤的估算跟 TiDB 非同步載入統計資訊的行為相關。統計資訊 Lazy Load 的 feature 是對於列上詳細的統計資訊,比如 (histogram/cm_sketch 等),只有等到第一次被用到之後,後臺任務才會非同步載入的。為了驗證,我們重啟一個 TiDB 例項,然後對 status=1 進行 explain analyze,依然沒有重現 status=1 估算為 0 的情況。

通過 stats_histograms.update_time 檢查上一次統計資訊更新時間可以確認跑負載之前表上的統計資訊剛好被自動更新過 (注意:stats_meta.update_time 不代表上一次統計資訊更新時間)。然而統計資訊還是不準確,這是為什麼呢?
通過偶然的機會我們發現,status=1 情況只存在於跑負載過程中。負載跑完以後,表裡面沒有status=1 的資料。所以自動收集統計資訊時,因為上一輪的負載已結束,status=1 的資料已經被處理完了,表裡沒有 status=1 的資料,所以 status=1 的估計值為 0,status 列唯一值 (NDV, number of distinct values)只有 1。而正確的統計資訊裡,NDV 為 2。
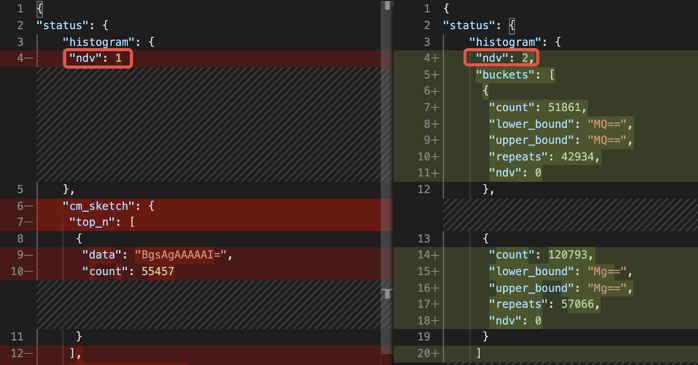
左邊為錯誤的的統計資訊,右邊為正確的統計資訊
對於業務中訊息中間表,資料是頻繁變動的,統計資訊是否具有代表性,取決於統計資訊更新時,資料的狀態。針對這種情況,TiDB 優化器需要支援手工鎖定統計資訊,避免 auto analyze 任務在錯誤的時間點蒐集了非典型統計資訊。在現有版本,需要通過 SQL Binding 手工繫結執行計劃,確保正確的執行計劃被選擇。
TPS 880 到 1200+
資料庫優化之後,應用的 TPS 跟應用 jvm 的個數成正比。最終,使用一臺 ARM 伺服器,同樣是 16 個 Numa,部署15個應用,每個應用 jvm 繫結一個 Numa,連線到 TiDB 叢集。最優應用併發在 1200 左右,最大應用 TPS 為 1250 左右。應用伺服器和資料庫伺服器 CPU 資源利用率在 70% 左右。
優化總結
這個案例裡面我們學到了什麼?
第一, ARM 伺服器上萬物綁 Numa,包括應用 jvm、Haproxy、TiDB 的所有的元件:PD、TiDB 和 TiKV。
第二,效能優化最核心的問題就是時間去哪兒了。難點是任何地方都可能成為瓶頸,如何進行觀測和定位?在這個案例裡面,我們通過使用者響應時間和資料庫時間的對比,判斷了瓶頸在資料庫裡面,還是資料庫外面,也可以直接通過 TiDB 的指標 connation idle duration (資料庫連線提交 SQL 間隔時間),進行快速的判定。
第三,我們在這個案例裡重度使用了 TiDB Dashboard 和 grafana 等內建監控,進行 sql 優化和關鍵指標的分析;利用了火焰圖、mpstat等系統工具,對進行 CPU、網路、IO 等資源進行觀測。
TiDB 效能和穩定性的挑戰
對於銀行核心交易應用是 read heavy 負載,一個交易包含上百條小查詢,如何保持高效能和穩定性是一個巨大的挑戰。
對 TiDB 例項進行 trace,同樣一條 sql 的執行,針對一個單行配置表的查詢,延遲範圍從 1.5毫秒到 15 毫秒,雖然大多數執行分佈在 2.5 毫秒左右,最大的延遲 15 毫秒。分析最高的 15 毫秒延遲資訊,可以發現 sql 執行過程中 goroutine 需要頻繁切換出來進行 gc mark asist 等操作,影響了 sql 的處理延遲。


分析 TiDB 的火焰圖,CompilePreparedStatements 佔了 18% 的 TiDB CPU,按照 alloc_objects 排序,TiDB 記憶體申請操作大約36% 來源於 CompilePreparedStatements 中的planner.Oplimzer。為什麼開啟了執行計劃快取(prepared plan cache),優化器還需要對於 prepared statements 進行解析和執行計劃生成的操作,消耗大量的記憶體和 CPU?
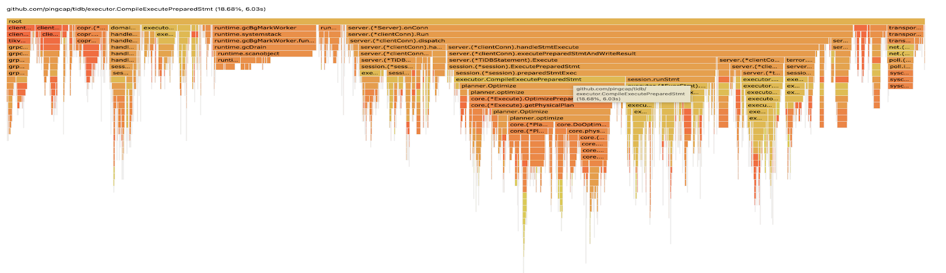
通過 grafana 監控,可以確認 prepared plan cache 命中率為 72.7%, 27.3% 的 prepared statement 沒有命中 plan cache 的 sql,會重複解析生成執行計劃。因為這次測試使用了v5.1.1 版本,prepared-plan-cache 還是實驗特性,部分 sql 語句還不支援快取執行計劃。
-
Queries Using Plan Cache OPS = 33.3k
-
StmtExecute = 45.8k
-
prepared plan cach 命中率 = 33.3/46.8 = 72.7%

在近期新版本 v5.3.0 中,prepared plan cache 這個 feature 已經正式 GA,解決了之前部分語句的執行計劃無法快取的問題,消除了重複解析 SQL、 生成執行計劃帶來的 CPU 和記憶體的消耗。正如對於執行在 Oracle 上的 OLTP 應用,使用繫結變數和軟解析可以使效能得到數量級別的提升,隨著 prepared plan cache 特性的 GA,TiDB 在銀行核心負載中,效能和穩定性方面將有顯著的提升。另外,應用使用 prepared statement 介面,還可以有效防止 SQL 注入攻擊,提高整個系統的安全性。
- 基於tidbV6.0探索索引優化思路
- TiDB HTAP特性的應用場景簡析
- 記憶體悲觀鎖
- 用一個性能提升了666倍的小案例說明在TiDB中正確使用索引的重要性
- TiDB 6.0 新特性解讀 | Collation 規則
- 一個小操作,SQL查詢速度翻了1000倍。
- 中國技術出海,TiDB 資料庫海外探索之路 | 卓越技術團隊訪談錄
- 一個小操作,SQL查詢速度翻了1000倍。
- TiDB 查詢優化及調優系列(三)慢查詢診斷監控及排查
- TiDB 查詢優化及調優系列(三)慢查詢診斷監控及排查
- TiDB 查詢優化及調優系列(二)TiDB 查詢計劃簡介
- TiFlash 原始碼閱讀(一) TiFlash 儲存層概覽
- 簡單瞭解 TiDB 架構
- Oceanbase和TiDB粗淺對比之 - 執行計劃
- TiKV 縮容不掉如何解決?
- 簡單瞭解 TiDB 架構
- Oceanbase 和 TiDB 粗淺對比之 - 執行計劃
- TiDB 6.0 的「元功能」:Placement Rules in SQL 是什麼?
- TiDB 在連鎖快餐企業丨海量交易與實時分析的應用探索
- 對Indexlookup的理解誤區