作者 | 張怡
來源 | Datawhale(ID:Datawhale)
【導語】經常有朋友私信問,如何學python?如何敲程式碼?如何進入AI行業?正好回頭看看自己這一年走過的路,進行一次經驗總結。這是一篇關於如何成為一名AI演算法工程師的長文,來看看你距離成為一名AI工程師還有多遠吧。
具體內容:
我是因為什麼開始接觸敲程式碼
人工智慧/機器學習/深度學習
自學如何尋找學習資料
如何選擇程式語言/框架
校招/社招/實習/面試經驗
一碗雞湯
宣告:
本篇內容均屬於個人觀點,建議採納對自己有用的經驗,如有疏漏,歡迎指正,共同進步!
2017年5月開始第一份實習 / 2017年7月開始學敲程式碼 / 2017年11月碩士畢業
擅長的程式語言:R / Python
不花錢報班,全靠自學,最初是因為窮,後來發現“開源”的世界真是太美好了!

我是因為什麼開始接觸敲程式碼?
1、我的第一個模型是什麼?
由於本科是數學,研究生是量化分析,第一份實習是一家金融科技公司,開始接觸所謂的“Fintech”
第一個任務就是做客戶的信用評分卡模型,目的給每個使用者打一個信用分數,類似支付寶的芝麻信用分。這是銀行標配的一個模型,最常見最傳統的演算法用的就是邏輯迴歸。
在課堂上使用的工具是SAS,SPSS,屬於有操作介面的,選單非常齊全,只需要滑鼠點一點就能建模,很好上手。但是SAS這些要付錢的,年費還是相當的貴,所以深圳大部分公司進行資料分析和建模工作都選擇開源免費的R語言或者Python。這就體現了掌握一門程式語言的重要性。
雖然說是建模任務,但是前三個月跟建模基本都扯不上邊。都在做資料清洗,表格整理(攤手),都在library各種包,用的最多的可能是data.table和dplyr。沒辦法,很多模型都有包可以直接呼叫,是最簡單的環節了。其實一開始,我一直在犯很低階的錯誤,各種報錯,沒有library啦,標點符號沒打對啦,各種很low的錯誤犯了一次又一次,而且連報錯的內容都不會看,不知道怎麼去改正。如果你也像我一樣,真的請不要灰心,我就是這樣走過來的。對著錯誤一個個去解決就好了~
當時什麼都不知道的時候,覺得真難呀,每個環節都有那麼多細節要照顧,要學的那麼多,做完一個還有一個,還要理解業務含義。但是當完整的做一遍之後再回頭,就會覺得,其實,也沒那麼難嘛~
2、敲程式碼容易嗎
因為我不是計算機專業的,所以基本上屬於沒怎麼敲過程式碼的那種。
後來發現程式設計師也有好多種類的,前端後端等,因此敲的程式碼種類也很多,才會有幾十種的程式語言,下圖是一些這幾年的主流語言。
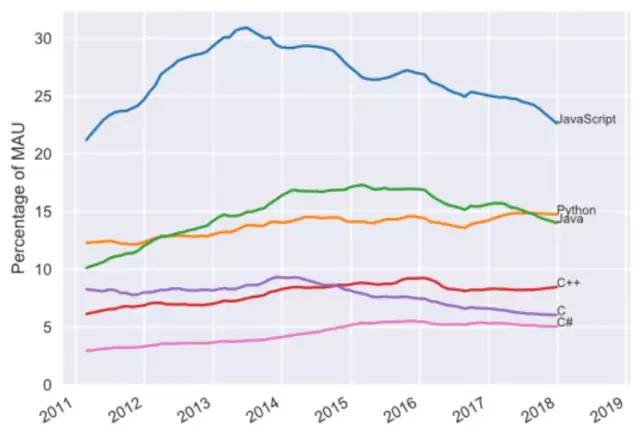
實習時我一直被隊友嫌棄很蠢,而且一開始敲的東西怎麼也執行不通,執行出來的都是鬼結果。有n次想放棄的念頭,“我幹嘛一定要敲這玩意兒?”,但也有n+1次想堅持的理由,因為我真的喜歡我正在做的事。為什麼用“堅持”,因為真的不容易。不難,但真的需要有耐心。
一開始我的狀態就是一行行程式碼的執行,一個個命令的熟悉,反覆看,反覆執行。
- 從敲出第一行程式碼到敲出第一個完整的模型花了3個月
- 學習XGBoost,光是理論學了3個月,因為前期鋪墊要學的還有adaboost/gbdt和各種機器學習的知識模組
- 從機器學習(Machine Learning)切換到自動機器學習(Auto Machine Learning)花了2個月
從一年前的“什麼是過擬合,什麼是交叉檢驗,損失函式有哪些”到後來參加全球人工智慧峰會時都能聽懂的七七八八,會覺得,努力沒有白費呀!
慢慢的就從一開始的那種“唉,怎麼又報錯啊,好挫敗”的心態變成現在的“啊?沒error?感覺不對啊,再查驗一遍吧”這種抖M傾向的人。程式碼虐我千百遍,我已經被磨的沒有了脾氣。
已經有幾個朋友說想轉行了,我何曾沒想過,只是不知不覺中堅持了下來而已。因為熱愛,越虐越停不下來
為什麼第一個寫:“我是因為什麼開始敲程式碼的”,因為動機真的非常重要!所以,很多人在問我“如何學python?”這種問題時,我的第一回答都是“你學python用來幹嘛?”在學校也敲打過python,做個爬蟲demo什麼的,因為目的性不強沒多久就放一邊了。清晰的目標就比如說你要做NLP,你要知道NLP的應用有智慧問答,機器翻譯,搜尋引擎等等。然後如果你要做智慧問答你要知道現在最發達的技術是深度學習,使用的演算法有RNN/LSTM/Seq2Seq/等等一系列。而我的清晰目標是在實習的時候給我的任務。當任務很明確的時候,所需要的語言就明確了,所要學習的演算法也就明確了,很多東西就順理成章了不用一頭亂撞了。
AI的應用範圍很廣,每一個研究方向都是無窮盡的。由於金融公司很少與影象處理,NLP等技術會有交集,而我強大的好奇心讓我決定去純粹的科技公司一探究竟。目前已投身於智慧家居,目標是Javis
我經常在公交的廣告牌上看見這些詞,好像哪家公司沒有這個技術就落後了似的。更多的還有強化學習,遷移學習,增量學習等各種學習。
機器學習是人工智慧的一種,深度學習是機器學習的一種。學AI先學機器學習。
2、計算機的“演算法” 與 數學的“演算法” 的區別理論知識對於AI演算法工程師極其重要。敲程式碼只是思路的一個實現過程。這裡的“演算法”和計算機CS的“演算法”還不太一樣,AI演算法是偏數學推導的,所以數學底子還是需要點的,學的越深,要求越高。面試的時候,很少讓手寫程式碼,90%都是在問模型摳演算法細節。在學校我是一個不愛記筆記的人,甚至是一個不愛上課的人。但是自從入了機器學習的坑後,筆記寫的飛起~
按照資料集有沒有Y值可以將機器學習分為監督學習、半監督學習和無監督學習。監督學習是分類演算法,無監督學習是聚類演算法。
ML這棵樹還可以有更多的分支。先有個整體感受,再一個一個的解決掉。這裡的知識點也是面試最愛問的幾個,是重點呀!面試過的同學應該都不陌生了。
機器學習之大,初學者都無從下手。說白了,機器學習就是各種模型做預測,那麼就需要有資料,要想有好的效果,就要把原始的髒資料洗乾淨了才能用。資料內隱藏的資訊有時候是肉眼不可見的,那麼就需要一些相關技巧來把有用資訊挖出來。所有絞盡腦汁使用的技巧,都是為了能預測的更準確。但是誰也沒辦法做到百分百的命中。
這裡簡單介紹下機器學習的三大塊:傳統的機器學習ML、影象處理CV、自然語言處理NLP這是一個世界級的最權威的機器學習比賽,已被谷歌收購。上面的賽題不僅很有代表性,還有很多免費的優秀的資料集供你使用,要知道收集資料是機器學習的第一大難題,它就幫你解決了。入門不用立馬參加比賽,把資料下載下來,盡情折騰就好了,要是沒有思路,去網上搜別人的解題筆記和程式碼借鑑一下也很美好~因為這是大家都爭相打榜的比賽,所以你並不孤單。
等做完第一個titanic的比賽應該就有點感覺了。上面4個比賽我都做過,覺得很經典,很適合入門。
如今的樣本輸入可以是文字,可以是影象,可以是數字。深度學習是跟著影象處理火起來的。甚至現在這個概念都火過了“機器學習”。深度學習的演算法主要都是神經網路系列。入門推薦CNN(卷積神經網路)的一系列:LeNet5
AlexNet
VGG
GoogleNet
ResNet
“開源”,我的愛!程式碼屆裡開源的中心思想就是,share and free。
對於機器學習,網上的社群氛圍特別好,分享的很多很全面,而且MLer都非常樂於助人。介紹幾個我經常逛的社群,論壇,和網頁:
全球最權威的機器學習比賽,已被谷歌收購。賽題覆蓋傳統機器學習、nlp、影象處理等,而且都是很實際的問題,來自各行各業。kaggle是數一數二完善的ML社群了,賽題開放的資料集就很有用,非常適合新手練手。對優秀的kaggler也提供工作機會。
全球最大同**友網站,適合搜專案,開源大社群,大家一起看星星,看issue~
程式碼報錯找它,程式碼不會敲找它!所有與程式碼相關的坑,基本都有人踩過啦。
最接地氣的部落格聚集地,最常看的網頁之一,一般用來搜尋細節知識點或者程式碼報錯時。
專業做機器學習100年!各演算法各技巧的例子code應有盡有。
創辦人是Twitter的創始人,推崇優質內容,國內很多AI公眾大號的搬運都來自於這裡,medium裡每個作者都有自己獨特的見解,值得學習和開拓眼界,需要科學上網。
谷歌的AI團隊維護的部落格,每天至少更新一篇技術部落格。剛在上海開的谷歌開發者大會宣佈將會免費開放機器學習課程,值得關注一下,畢竟是AI巨頭。
首先說明我沒有上課,也沒有報班,屬於個人學習習慣問題。但考慮到學習差異性,所以還是總結了口碑排名靠前的課程系列。前提,需要有一定數學基礎,沒有的可以順便補一補。專注於深度學習。Fast.ai的創始人就蠻有意思的,是橫掃kaggle影象處理的高手,不擺架子,也不故弄玄虛。中心思想就是深度學習很簡單,不要怕。fast.ai有部落格和社群。Jeremy和Rachel鼓勵撰寫部落格,構建專案,在會議中進行討論等活動,以實力來代替傳統證書的證明作用。
有中文版,課程覆蓋程式設計基礎,機器學習,深度學習等。
科技圈也是有潮流要趕的,等你入坑就知道。追最新的論文,最新的演算法,最新的比賽,以及AI圈的網紅是哪些~有條件的開個twitter,平時娛樂看看機器學習板塊還是蠻有意思的,有很多自嘲的漫畫~
考過雅思和GMAT,曾經我也是一個熱愛英文的孩子,如今跪倒在海量技術文件和文獻裡苟活baidu???ummm......別為難我......很少用 語言+問題,例如:python how to convert a list to a dataframe 直接複製錯誤資訊,例如:ValueError: No variables to save... 請把所有的問題往上拋,網上查比問人快!總是問別人會引起關係破裂的~ 當你讀到一個非常不錯的技術文件時,看完別急著關掉。這可能是一個個人網站,去觀察選單欄裡有沒有【About】選項。或者這也可能是一個優秀的社群,看看有沒有【Home】選項,去看看po的其它的文章。
雖然說了那麼多,但還是要說請放棄海量資料!用多少,找多少就好了!(別把這句話當耳旁風)資料不在量多而在於內容是有質量保證的。很多課程或者公眾號只管塞知識,你有疑問它也解答不了的時候,這樣出來的效果不好,就像一個模型只管訓練,卻不驗證,就是耍流氓。
說到底,語言只是工具,不去盲目的追求任何一種技術。根據任務來選擇語言,不一樣的程式設計師選擇不一樣的程式語言。很多人最後不是把重點放在能力而是炫工具,那就有點走偏了。
據觀察,在機器學習組裡R和Python是使用率最高的兩門語言,一般你哪個用的順就用哪個,只要能達到效果就行,除非強制規定。我使用之後的感受是,人生苦短,我用python。
演算法任務大致分為兩種,一種是普通演算法工程師做的“調包、調參”,另一種是高階演算法工程師做的,可以自己建立一個演算法或者能靈活修改別人的演算法。
tensorflow / caffe / keras /... Auto ML(auto machine learning),自動機器學習。就是你只管丟進去資料,坐等跑出結果來就行了。前一陣子谷歌的CloudML炒的很火,願景是讓每個人都能建模,但畢竟這種服務是要錢的。所以我研究了下開源的auto sklearn框架的程式碼,發現了什麼呢?建模到底有多簡單呢?就,簡單到4行程式碼就可能打敗10年工作經驗的建模師。
再說回來,如果你自己根本不知道自己在做什麼,只能跑出來一個你不能負責的結果,就是很糟糕的,那還不是一個合格的演算法工程師。你的模型必須像你親生的那樣。但是,只要你想,絕對能做到的!
對,就是這麼簡單粗暴,裝這個就ok了。學python的應該都會面臨到底是python2還是python3的抉擇吧。語言版本和環境真的很讓人頭疼,但是Anaconda驚豔到我了,就是可以自定義python環境,你可以左手py2右手py3。
Anaconda自帶的ide。介面排版與Rstudio和Matlab很相似。輸入什麼就輸出什麼結果,適合分析工作,我寫小功能的時候很喜歡用。Anaconda自帶的ide,屬於web介面的。當你程式跑在虛擬機器,想調程式碼的時候適合用。對於寫專案的,或者程式碼走讀的比較友好。當你需要寫好多python檔案互相import時,特別好用。
2019屆的秋招:2019年7月 - 2019年11月
2020屆的春招:2020年2月 - 2020年4月
2020屆的暑期實習:2020年3月 - 2020年5月
2020屆的秋招:2020年7月 - 2020年11月
建議提早半年開始準備。我的程式碼也是從實習開始敲起,敲了半年才覺得下手如有神哈哈。不要做沒實際意義的課後題,也不要照著書本例題敲,敲完你就忘了,書本這些都是已經排除萬難的東西,得不到什麼成長。入門修煉:全國大學生數學建模競賽、全美大學生數學建模競賽、kaggle、天池…
如果明確自己的職業方向為人工智慧/資料探勘類的,請不要浪費時間去申請其他與技術無關的實習。端茶送水,外賣跑腿,列印紙並不能幫你。當時由於身邊同學都斷斷續續出去實習,面前有一份大廠行政的實習,我…竟然猶豫了一下,好在也還是拒絕了。
儘量選擇大廠的技術實習,畢竟以後想進去會更難。但是不要因為一個月拿3000塊就只幹3000塊的活。把整個專案跟下來,瞭解框架的架構,優化的方向,多去嘗試,就算加班(加班在深圳很正常)也是你賺到,思考如何簡化重複性工作,去嘗試瞭解自己部門和其他部門的工作內容與方向,瞭解的越多你對自己想做的事情瞭解的也越多。我實習做的評分卡模型,除了傳統邏輯迴歸,也嘗試新的XGB等等,而且雖然別人也在做,但是私下自己會把整個模型寫一遍,包含資料清洗和模型調優等,這樣對業務的瞭解也更透徹,面試起來所有的細節都是親手做過的,也就比較順了。
如果沒有實習在手,世界給我們資料探勘選手的大門還是敞開著的。kaggle上有專門給資料探勘入門者的練習場。相關的比賽還有很多,包括騰訊、阿里等大廠也時不時會發布算法大賽,目測這樣的演算法大賽只會越來越多,你堅持做完一個專案,你在平臺上還可以得到相關名次,名次越靠前越有利哈哈哈這是廢話。
自我介紹/專案介紹
類別不均衡如何處理
資料標準化有哪些方法/正則化如何實現/onehot原理
為什麼XGB比GBDT好
資料清洗的方法有哪些/資料清洗步驟
缺失值填充方式有哪些
變數篩選有哪些方法
資訊增益的計算公式
樣本量很少情況下如何建模
交叉檢驗的實現
決策樹如何剪枝
WOE/IV值計算公式
分箱有哪些方法/分箱原理是什麼
手推SVM:目標函式,計算邏輯,公式都寫出來,平面與非平面
核函式有哪些
XGB原理介紹/引數介紹/決策樹原理介紹/決策樹的優點
Linux/C/Java熟悉程度
過擬合如何解決
平時通過什麼渠道學習機器學習(好問題值得好好準備)
決策樹先剪枝還是後剪枝好
損失函式有哪些
偏向做資料探勘還是演算法研究(好問題)
bagging與boosting的區別
模型評估指標有哪些
解釋模型複雜度/模型複雜度與什麼有關
說出一個聚類演算法
ROC計算邏輯
如何判斷一個模型中的變數太多
決策樹與其他模型的損失函式、複雜度的比較
決策樹能否有非數值型變數
決策樹與神經網路的區別與優缺點對比
資料結構有哪些
model ensembling的方法有哪些
問題是散的,知識是有關聯的,學習的時候要從大框架學到小細節。
沒事多逛逛招聘網站看看招聘需求,瞭解市場的需求到底是什麼樣的。時代變化很快,捕捉資訊的能力要鍛煉出來。你可以關注的點有:職業名/職業方向/需要會什麼程式語言/需要會什麼演算法/薪資/...
每個面試的結尾,面試官會問你有沒有什麼想問的,請注意這個問題也很關鍵。比如:這個小組目前在做什麼專案/實現專案主要用什麼語言和演算法/…儘量不要問加不加班,有沒有加班費之類的,別問我為什麼這麼說(攤手)
在面試中遇到不理解的,比如C++語法不懂,可以問這個C++具體在專案中實現什麼功能。如果你提出好問題,能再次引起面試官對你的興趣,那就能增加面試成功率。應屆生就好好準備校招,別懶,別怕輸,別怕被拒,從哪裡跌倒從哪裡起來。社招不是你能招呼的,會更挫敗,因為你什麼也沒做過。
雖然是做技術的,但是日常social一下還是收益很大的。實習的時候,也要與周圍同事和平相處,尤其是老大哥們,也許哪天他就幫你內推大廠去了。內推你能知道意想不到的資訊,面試官,崗位需求,最近在做什麼專案之類的。
挑選給你機會的公司,不要浪費自己的時間。不要每家都去,去之前瞭解這家公司與你的匹配度。尤其社招,你一改動簡歷就很多人給你打電話,你要有策略的去進行面試,把握總結每個機會。像我就是東一榔頭西一榔頭的,好多都是止步於第一面,就沒回信兒了,因為每次面完沒有好好反思總結,等下次再遇到這問題還是抓瞎,十分消耗自己的時間和信心。
AI才剛剛起步,為什麼呢?因為上數學課的時候,課本上都是柯西,牛頓,高斯等等,感覺他們活在遙遠的時代,很有陌生感。但是現在,我每天用的模型是比我沒大幾歲的陳天奇創造出來的,我甚至follow他的社交賬號,他就鮮活在我的世界裡,這種感覺,很奇妙。每次查論文查文獻的時候,看2017年出來的都覺得晚了,懊悔自己怎麼學的這麼慢,看2018年2月出來的才心裡有點安慰。這個證明,你在時代發展的浪潮上,也是一切剛剛起步的證明。機遇與挑戰並肩出現的時候,是你離創造歷史最近的時候。而所謂的風口所謂的浪尖都不重要,重要的是,因為你喜歡。
當你因為真的熱愛某件事,而不斷接近它的時候,你的靈魂像是被上帝指點了迷津,受到了指示,受到了召喚。你會很自然的知道該做什麼,你想做什麼,好像生而為了這件事而來。你有時候自己都想不明白為什麼做這件事。看過月亮與六便士的應該懂這種使命感~
我不是屬於聰明的那類人,我是屬於比較倔的那種。就是隻要我認定的,我認定到底。天知道我有多少次懷疑過自己,有多少次想放棄,但我還是選擇咬牙向前,選擇相信自己。堅持的意義就在這裡。(*本文為AI科技大本營轉載文章,轉載請聯絡作者)
六大主題報告,四大技術專題,AI開發者大會首日精華內容全回顧
CSDN“2019 優秀AI、IoT應用案例TOP 30+”正式發布
如何打造高質量的機器學習資料集?
從模型到應用,一文讀懂因子分解機
用Python爬取淘寶2000款套套
7段程式碼帶你玩轉Python條件語句
高階軟體工程師教會小白的那些事!
誰說 C++ 的強制型別轉換很難懂?



 ,收到请求立即删除
,收到请求立即删除
朋友會在“發現-看一看”看到你“在看”的內容